En este artículo vamos a ver cómo hacer una tabla de distribución de frecuencias utilizando el lenguaje de programación R.
El método table() en R se usa para calcular los recuentos de frecuencia de las variables que aparecen en la columna especificada del marco de datos. El resultado se devuelve en forma de estructura tabular de dos filas, donde la primera fila indica el valor de la columna y la siguiente indica sus frecuencias correspondientes.
frq-table <- table (x), where x is the data.table object
La distribución de frecuencia acumulada de un conjunto de datos dado es la suma de todas las clases, incluida esta clase debajo de ella, en una tabla de distribución de frecuencia obtenida. El valor en cualquier posición de celda se obtiene sumando todos los valores anteriores y el valor actual encontrado hasta ahora. La función cumsum() se puede utilizar para calcular esto.
cumsum( frq-table)
La frecuencia relativa, también conocida como distribución de probabilidad, es la frecuencia del valor correspondiente dividida por el número total de elementos. Esto se puede calcular mediante el método prop.table() aplicado sobre la tabla de frecuencia.
prop.table (frq-table) OR frq-table / total observations
Ejemplo 1: Realización de una tabla de distribución de frecuencias.
R
library ('data.table')
# creating a dataframe
data_table <- data.table(col1 = sample(6 : 9, 9 ,
replace = TRUE),
col2 = letters[1 : 3],
col3 = c(1, 4, 1, 2, 2,
2, 1, 2, 2))
print ("Original DataFrame")
print (data_table)
freq <- table(data_table$col1)
print ("Modified Frequency Table")
print (freq)
print ("Cumulative Frequency Table")
cumsum <- cumsum(freq)
print (cumsum)
print ("Relative Frequency Table")
prob <- prop.table(freq)
print (prob)
Producción
[1] "Original DataFrame" col1 col2 col3 1: 9 a 1 2: 6 b 4 3: 6 c 1 4: 6 a 2 5: 8 b 2 6: 7 c 2 7: 6 a 1 8: 6 b 2 9: 8 c 2 [1] "Modified Frequency Table" 6 7 8 9 5 1 2 1 [1] "Cumulative Frequency Table" 6 7 8 9 5 6 8 9 [1] "Relative Frequency Table" 6 7 8 9 0.5556 0.1111 0.2222 0.1111
Ejemplo 2:
El método table() puede aceptar múltiples argumentos como sus parámetros. Todas las combinaciones se generan mediante la unión cruzada de los valores de la columna y luego se extraen los elementos únicos, y también se cuenta su frecuencia correspondiente. El resultado se obtiene en forma de array 2D con el número de filas y columnas equivalente a todas las combinaciones y valores de celda de array como sus cuentas.
R
library ('data.table')
# creating a dataframe
data_table <- data.table(col1 = sample(6 : 9, 9 ,
replace = TRUE),
col2 = letters[1 : 3],
col3 = c(1, 4, 1, 2, 2,
2, 1, 2, 2))
print ("Original DataFrame")
print (data_table)
freq <- table(data_table$col1, data_table$col3)
print ("Modified Frequency Table")
print (freq)
Producción
[1] "Original DataFrame" col1 col2 col3 1: 7 a 1 2: 7 b 4 3: 7 c 1 4: 8 a 2 5: 9 b 2 6: 9 c 2 7: 9 a 1 8: 7 b 2 9: 9 c 2 [1] "Modified Frequency Table" 1 2 4 6 2 1 0 7 1 0 0 8 0 1 1 9 0 3 0
Ejemplo 3:
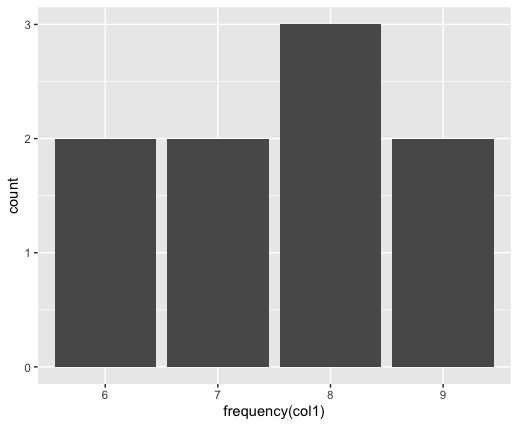
Las tablas de frecuencia de datos y frecuencia acumulada también se pueden visualizar importando el conjunto de datos al espacio de trabajo. La tabla de frecuencia se traza para tener en cuenta col1 del marco de datos. Los recuentos de frecuencia de cada uno de los valores se trazan indicando el número total de ocurrencias.
R
# import libraries
library("ggplot2")
# creating a dataframe
data_table <- data.frame(col1 = sample(6 : 9, 9 ,
replace = TRUE),
col2 = letters[1:3],
col3 = c(1, 4, 1, 2,
2, 2, 1, 2, 2))
print ("Original DataFrame")
print (data_table)
# computing frequency
freq_tbl <- table(data_table$col1)
print ("Frequency count")
print (freq_tbl)
# re-order levels
frequency <- function(x) {
factor(x, levels = names(table(x)))
}
# plotting the data with the help of ggplot
ggplot(data_table, aes(x = frequency(`col1`))) +
geom_bar()
Producción
[1] "Original DataFrame" col1 col2 col3 1 6 a 1 2 9 b 4 3 6 c 1 4 9 a 2 5 8 b 2 6 8 c 2 7 8 a 1 8 7 b 2 9 7 c 2
Publicación traducida automáticamente
Artículo escrito por yashkumar0457 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA