En este artículo, veremos qué es la interacción y si debemos usar la interacción en nuestro modelo para obtener mejores resultados o no.
Incluir interacción en regresión usando R
Digamos que X1 y X2 son características de un conjunto de datos e Y es la etiqueta de clase o el resultado que estamos tratando de predecir. Entonces, si X1 y X2 interactúan, esto significa que el efecto de X1 en Y depende del valor de X2 y viceversa, entonces, ¿dónde está la interacción entre las características del conjunto de datos? Ahora que sabemos si nuestro conjunto de datos contiene interacción o no. También debemos saber cuándo tener en cuenta la interacción en nuestro modelo para una mejor precisión o exactitud. Vamos a implementar esto usando el lenguaje R.
¿Deberíamos incluir la interacción en nuestro modelo?
Hay dos preguntas que debe hacerse antes de incluir la interacción en su modelo:
- ¿Esta interacción tiene sentido conceptualmente?
- ¿Es el término de interacción estadísticamente significativo? O creamos o no que las pendientes de las líneas de regresión son significativamente diferentes.
Implementación en R
Veamos la interacción en el modelo de regresión lineal a través de un ejemplo.
- conjunto de datos
- Parámetros/Variables:
- Variable independiente (Y): LungCap
- Variable Dependiente(X1): Humo(Si/No)
- Variable dependiente (X2): Edad
Ejemplo
Paso 1: Cargue el conjunto de datos
R
# Read in the Lung Cap Data LungCapData <- read.table(file.choose(), header = T, sep = "\t") # Attach LungCapData attach(LungCapData)
Paso 2: Grafique los datos, usando diferentes colores para humo (rojo) / no fumador (azul)
R
# Plot the data, using different # colours for smoke(red)/non-smoke(blue) # First, plot the data for # the Non-Smokers, in Blue plot(Age[Smoke == "no"], LungCap[Smoke == "no"], col = "blue", ylim = c(0, 15), xlim = c(0, 20), xlab = "Age", ylab = "LungCap", main = "LungCap vs. Age,Smoke")
Producción:
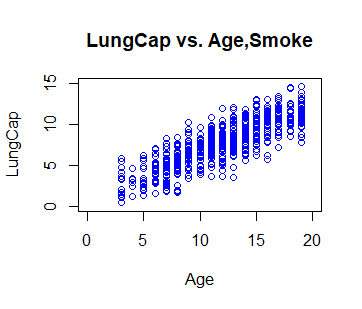
R
# Now, add in the points for # the Smokers, in Solid Red Circles points(Age[Smoke == "yes"], LungCap[Smoke == "yes"], col = "red", pch = 16)
Producción:
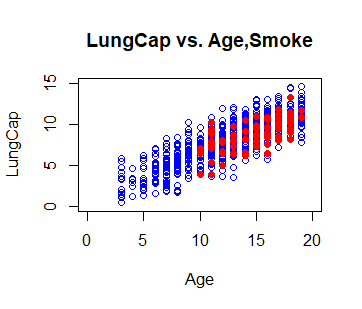
R
# And, add in a legend
legend(1, 15,
legend = c("NonSmoker", "Smoker"),
col = c("blue", "red"),
pch = c(1, 16), bty = "n")
Producción:
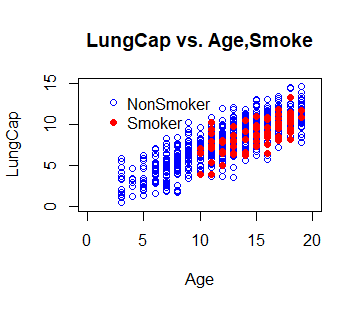
Paso 3. Ajuste un Modelo Reg, usando Edad, Humo y su INTERACCIÓN y Agregue las líneas de regresión
R
# Fit a Reg Model, using Age, # Smoke, and their INTERACTION model1 <- lm(LungCap ~ Age*Smoke) coef(model1)
Producción:
(Intercept) Age Smokeyes Age:Smokeyes 1.05157244 0.55823350 0.22601390 -0.05970463
R
# Note, that the "*" fits a model with # Age, Smoke and AgeXSmoke INT. # Note, also that the same model # can be fit using the ":" model1 <- lm(LungCap ~ Age + Smoke + Age:Smoke) # Ask for a summary of the model summary(model1)
Producción:
Llamar:
lm(fórmula = LungCap ~ Edad + Humo + Edad:Humo)
Derechos residuales de autor:
Mín. 1T Mediana 3T Máx.
-4,8586 -1,0174 -0,0251 1,0004 4,1996
Coeficientes:
Estimación estándar Error valor t Pr(>|t|)
(Intersección) 1.05157 0.18706 5.622 2.7e-08 ***
Edad 0,55823 0,01473 37,885 < 2e-16 ***
Ojos ahumados 0,22601 1,00755 0,224 0,823
Edad:Smokeyes -0.05970 0.06759 -0.883 0.377
—
signif. códigos: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
Error estándar residual: 1,515 en 721 grados de libertad
R-cuadrado múltiple: 0,6776, R-cuadrado ajustado: 0,6763
Estadístico F: 505,1 en 3 y 721 DF, valor p: < 2,2e-16
Paso 4: agreguemos las líneas de regresión de nuestro modelo usando el comando abline
R
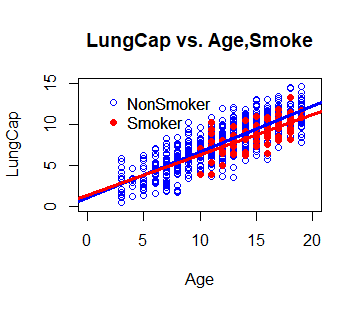
# Now, let's add in the regression # lines from our mode using the # abline command for the Non-Smokers, in Blue abline(a = 1.052, b = 0.558, col = "blue", lwd = 3)
Producción:
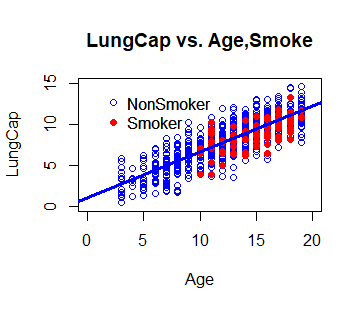
R
# And now, add in the line for Smokers, in Red abline(a = 1.278, b = 0.498, col = "red", lwd = 3)
Producción:
R
# Ask for that model summary again summary(model1) # Fit the model that does # NOT include INTERACTION model2 <- lm(LungCap ~ Age + Smoke) summary(model2)
Producción:
> summary(model1)
Call:
lm(formula = LungCap ~ Age + Smoke + Age:Smoke)
Residuals:
Min 1Q Median 3Q Max
-4.8586 -1.0174 -0.0251 1.0004 4.1996
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.05157 0.18706 5.622 2.7e-08 ***
Age 0.55823 0.01473 37.885 < 2e-16 ***
Smokeyes 0.22601 1.00755 0.224 0.823
Age:Smokeyes -0.05970 0.06759 -0.883 0.377
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.515 on 721 degrees of freedom
Multiple R-squared: 0.6776, Adjusted R-squared: 0.6763
F-statistic: 505.1 on 3 and 721 DF, p-value: < 2.2e-16
> summary(model2)
Call:
lm(formula = LungCap ~ Age + Smoke)
Residuals:
Min 1Q Median 3Q Max
-4.8559 -1.0289 -0.0363 1.0083 4.1995
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.08572 0.18299 5.933 4.61e-09 ***
Age 0.55540 0.01438 38.628 < 2e-16 ***
Smokeyes -0.64859 0.18676 -3.473 0.000546 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.514 on 722 degrees of freedom
Multiple R-squared: 0.6773, Adjusted R-squared: 0.6764
F-statistic: 757.5 on 2 and 722 DF, p-value: < 2.2e-16
Publicación traducida automáticamente
Artículo escrito por samrat2825 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA