Python es un buen lenguaje para realizar análisis de datos debido al increíble ecosistema de paquetes de Python centrados en datos. El paquete pandas es uno de ellos y facilita mucho la importación y el análisis de datos.
Aquí, discutiremos cómo cargar un archivo csv en un marco de datos. Se hace usando un método pandas.read_csv() . Tenemos que importar la biblioteca de pandas para usar este método.
Sintaxis:pd.read_csv(filepath_or_buffer, sep=’, ‘, delimitador=Ninguno, encabezado=’inferir’, nombres=Ninguno, index_col=Ninguno, usecols=Ninguno, squeeze=False, prefix=Ninguno, mangle_dupe_cols=True, dtype=Ninguno, motor=Ninguno, convertidores=Ninguno, valores_verdaderos=Ninguno, valores_falsos=Ninguno, skipinitialspace=False, skiprows=Ninguno, nrows=Ninguno, na_values=Ninguno, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates= Falso, infer_datetime_format=False, keep_date_col=False, date_parser=Ninguno, dayfirst=False, iterator=False, chunksize=Ninguno,pression=’infer’, miles=Ninguno, decimal=b’.’, lineterminator=Ninguno, quotechar=’ ”’, comillas=0, escapechar=Ninguna, comentario=Ninguna, codificación=Ninguna, dialecto=Ninguna, tupleize_cols=Ninguna, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True , memory_map=Falso,float_precision=Ninguno)
Algunos parámetros útiles se dan a continuación:
| Parámetro | Usar |
|---|---|
| ruta_archivo_o_búfer | Ubicación URL o directorio del archivo |
| sep | Significa separador, el valor predeterminado es ‘,’ como en csv (valores separados por comas) |
| index_col | Este parámetro se usa para hacer que la columna pasada sea un índice en lugar de 0, 1, 2, 3…r |
| encabezamiento | Este parámetro se usa para pasar la fila/s[int/int list] como encabezado |
| use_cols | Este parámetro solo usa la columna pasada [lista de strings] para crear un marco de datos |
| estrujar | Si es Verdadero y solo se pasa una columna, devuelve la serie pandas |
| salteadores | Este parámetro se usa para omitir las filas pasadas en el nuevo marco de datos |
| saltarín | Este parámetro se usa para omitir Número de líneas al final del archivo |
Este método usa la coma ‘,’ como delimitador predeterminado, pero también podemos usar un delimitador personalizado o una expresión regular como separador.
Para descargar los archivos csv, haga clic aquí
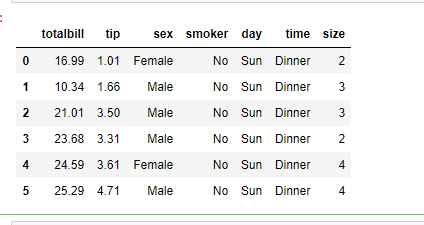
. Ejemplo 1: Uso del método read_csv() con un separador predeterminado, es decir, coma (,)
Python3
# Importing pandas library
import pandas as pd
# Using the function to load
# the data of example.csv
# into a Dataframe df
df = pd.read_csv('example1.csv')
# Print the Dataframe
df
Producción:
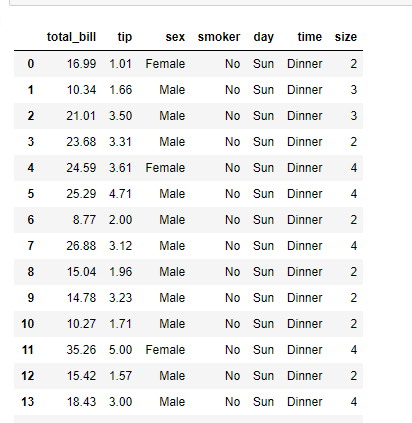
Ejemplo 2: Uso del método read_csv() con ‘_’ como delimitador personalizado.
Python3
# Importing pandas library
import pandas as pd
# Load the data of example.csv
# with '_' as custom delimiter
# into a Dataframe df
df = pd.read_csv('example2.csv',
sep = '_',
engine = 'python')
# Print the Dataframe
df
Producción:
Nota: al proporcionar un especificador personalizado, debemos especificar engine=’python’; de lo contrario, podemos recibir una advertencia como la que se muestra a continuación:

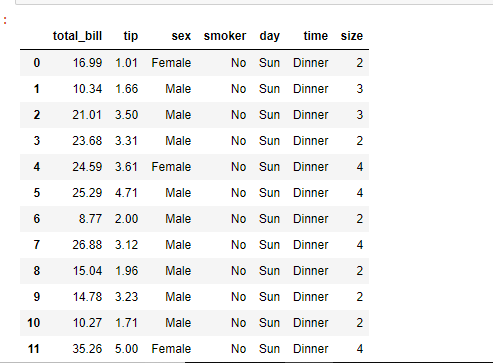
Ejemplo 3: Uso del método read_csv() con tabulador como delimitador personalizado.
Python3
# Importing pandas library
import pandas as pd
# Load the data of example.csv
# with tab as custom delimiter
# into a Dataframe df
df = pd.read_csv('example3.csv',
sep = '\t',
engine = 'python')
# Print the Dataframe
df
Producción:
Ejemplo 4: Uso del método read_csv() con una expresión regular como delimitador personalizado.
Supongamos que tenemos un archivo csv con varios tipos de delimitadores, como se indica a continuación.
totalbill_tip, sexo:fumador, día_hora, tamaño
16,99, 1,01:Mujer|No, Dom, Cena, 2
10,34, 1,66, Hombre, No|Dom:Cena, 3
21,01:3,5_Hombre, No:Dom, Cena, 3
23,68, 3,31 , Hombre|No, Dom_Cena, 2
24,59:3,61, Mujer_No, Dom, Cena, 4
25,29, 4,71|Hombre, No:Dom, Cena, 4
Para cargar dicho archivo en un marco de datos, usamos una expresión regular como separador.
Python3
# Importing pandas library
import pandas as pd
# Load the data of example.csv
# with regular expression as
# custom delimiter into a
# Dataframe df
df = pd.read_csv('example4.csv',
sep = '[:, |_]',
engine = 'python')
# Print the Dataframe
df
Producción: