Es un proceso bastante obligatorio modificar los datos que tenemos, ya que la computadora le mostrará un error de entrada no válida , ya que es bastante imposible procesar los datos que tienen ‘NaN’ y no es prácticamente posible cambiar manualmente el ‘ NaN’ a su media. Por lo tanto, para resolver este problema, procesamos los datos y usamos varias funciones mediante las cuales el ‘NaN’ se elimina de nuestros datos y se reemplaza con el medio particular y listo para ser procesado por el sistema.
Principalmente hay dos pasos para eliminar ‘NaN’ de los datos:
- Usando Dataframe.fillna() de la biblioteca de pandas.
- Usando SimpleImputer de sklearn.impute (esto solo es útil si los datos están presentes en forma de archivo csv)
Usando Dataframe.fillna() de la biblioteca de pandas
Con la ayuda de Dataframe.fillna() de la biblioteca de pandas, podemos reemplazar fácilmente el ‘NaN’ en el marco de datos.
Procedimiento:
- Para calcular la mean() usamos la función media de la columna en particular
- Ahora, con la ayuda de la función fillna(), cambiaremos todos los ‘NaN’ de esa columna en particular para la que tenemos su media.
- Imprimiremos la columna actualizada.
Sintaxis: df.fillna(valor=Ninguno, método=Ninguno, eje=Ninguno, inplace=False, limit=Ninguno, downcast=Ninguno, **kwargs)
Parámetro:
- value : Valor a utilizar para rellenar huecos
- método : Método a utilizar para rellenar orificios en serie reindexada pad/fill
- eje: {0 o ‘índice’}
- inplace : si es verdadero, complete el lugar.
- límite: si se especifica el método, este es el número máximo de valores de NaN consecutivos para completar hacia adelante/hacia atrás
- downcast: dict, el valor predeterminado es Ninguno
Ejemplo 1:
- Para calcular la mean() usamos la función media de la columna en particular
- Luego aplique la función fillna(), cambiaremos todos los ‘NaN’ de esa columna en particular para la cual tenemos su media e imprimiremos el marco de datos actualizado.
Python3
import numpy as np
import pandas as pd
# A dictionary with list as values
GFG_dict = { 'G1': [10, 20,30,40],
'G2': [25, np.NaN, np.NaN, 29],
'G3': [15, 14, 17, 11],
'G4': [21, 22, 23, 25]}
# Create a DataFrame from dictionary
gfg = pd.DataFrame(GFG_dict)
#Finding the mean of the column having NaN
mean_value=gfg['G2'].mean()
# Replace NaNs in column S2 with the
# mean of values in the same column
gfg['G2'].fillna(value=mean_value, inplace=True)
print('Updated Dataframe:')
print(gfg)
Producción:
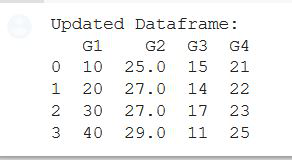
Ejemplo 2:
Python3
import pandas as pd
import numpy as np
df = pd.DataFrame({
'ID': [10, np.nan, 20, 30, np.nan, 50, np.nan,
150, 200, 102, np.nan, 130],
'Sale': [10, 20, np.nan, 11, 90, np.nan,
55, 14, np.nan, 25, 75, 35],
'Date': ['2020-10-05', '2020-09-10', np.nan,
'2020-08-17', '2020-09-10', '2020-07-27',
'2020-09-10', '2020-10-10', '2020-10-10',
'2020-06-27', '2020-08-17', '2020-04-25'],
})
df['Sale'].fillna(int(df['Sale'].mean()), inplace=True)
print(df)
Producción:
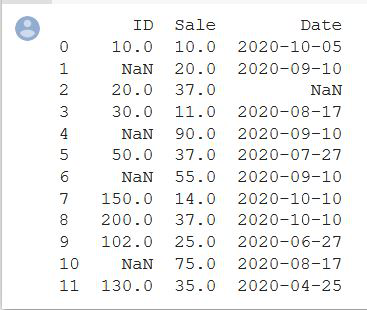
Usando SimpleImputer() de sklearn.impute
Esta función Transformador de imputación para completar valores faltantes que proporciona estrategias básicas para imputar valores faltantes. Estos valores se pueden imputar con un valor constante proporcionado o utilizando las estadísticas (media, mediana o más frecuente) de cada columna en la que se encuentran los valores faltantes. Esta clase también permite la codificación de valores perdidos diferentes.
Sintaxis: class sklearn.impute.SimpleImputer(*, valores_faltantes=nan, estrategia=’media’, valor_relleno=Ninguno, detallado=0, copia=Verdadero, indicador_añadido=Falso)
Parámetros:
- valores_faltantes: int float, str, np.nan o Ninguno, predeterminado=np.nan
- string de estrategia: default=’mean’
- fill_valuestring o valor numérico: predeterminado=Ninguno
- detallado: entero, predeterminado = 0
- copia: booleano, predeterminado = Verdadero
- add_indicator: booleano, predeterminado=Falso
Nota: Los datos utilizados en los siguientes ejemplos están aquí
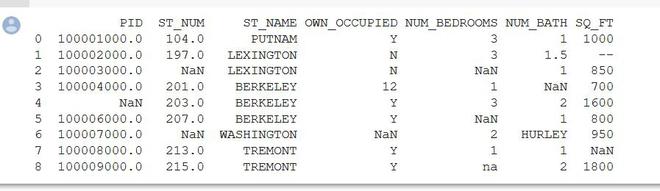
Ejemplo 1: (Cálculo en la columna PID)
Python3
import pandas as pd
import numpy as np
Dataset= pd.read_csv("property data.csv")
X = Dataset.iloc[:,0].values
# To calculate mean use imputer class
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X)
X = imputer.transform(X)
print(X)
Producción:
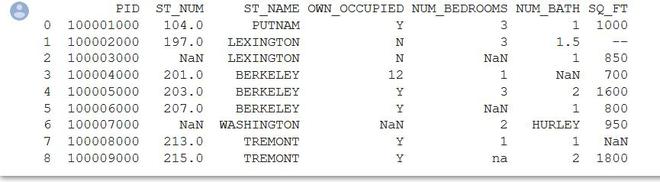
Ejemplo 2: (Cálculo en la columna ST_NUM)
Python3
from sklearn.impute import SimpleImputer
import pandas as pd
import numpy as np
Dataset = pd.read_csv("property data.csv")
X = Dataset.iloc[:, 1].values
# To calculate mean use imputer class
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X)
X = imputer.transform(X)
print(X)
Producción:

Publicación traducida automáticamente
Artículo escrito por geetansh044 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA