Machine Learning es el campo de estudio que le da a las computadoras la capacidad de aprender sin ser programadas explícitamente. A menudo nos encontramos con conjuntos de datos en los que faltan algunos valores en las columnas. Esto causa problemas cuando aplicamos un modelo de aprendizaje automático al conjunto de datos. Esto aumenta las posibilidades de error cuando estamos entrenando el modelo de aprendizaje automático.
El conjunto de datos que estamos usando es:
Python3
# import modules
import pandas as pd
import numpy as np
# assign dataset
df = pd.read_csv("train.csv", header=None)
df.head
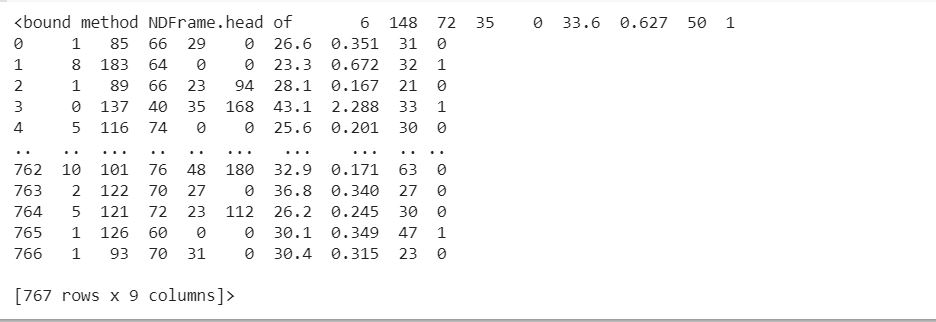
Contando los datos faltantes:
Python3
# counting number of values of all the columns cnt_missing = (df[[1, 2, 3, 4, 5, 6, 7, 8]] == 0).sum() print(cnt_missing)

Vemos que para la columna 1,2,3,4,5 faltan los datos. Ahora reemplazaremos todos los valores 0 con NaN.
Python
from numpy import nan df[[1, 2, 3, 4, 5]] = df[[1, 2, 3, 4, 5]].replace(0, nan) df.head(10)
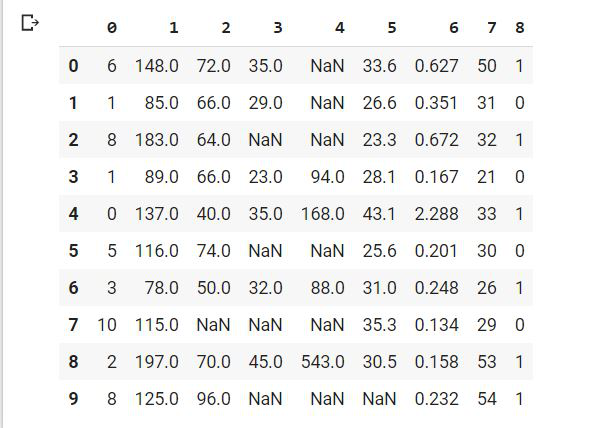
El manejo de los datos faltantes es importante, por lo que eliminaremos este problema siguiendo los siguientes enfoques:
Enfoque #1
El primer método es simplemente eliminar las filas que tienen los datos que faltan.
Python3
# printing initial shape print(df.shape) df.dropna(inplace=True) # final shape of the data with # missing rows removed print(df.shape)

Pero en esto, el problema que surge es que cuando tenemos conjuntos de datos pequeños y si eliminamos filas con datos faltantes, el conjunto de datos se vuelve muy pequeño y el modelo de aprendizaje automático no dará buenos resultados en un conjunto de datos pequeño.
Así que para evitar este problema tenemos un segundo método. El siguiente método es ingresar los valores que faltan. Hacemos esto reemplazando el valor faltante con algún valor aleatorio o con la mediana/media del resto de los datos.
Enfoque #2
Primero imputamos los valores faltantes por la media de los datos.
Python3
# filling missing values # with mean column values df.fillna(df.mean(), inplace=True) df.sample(10)
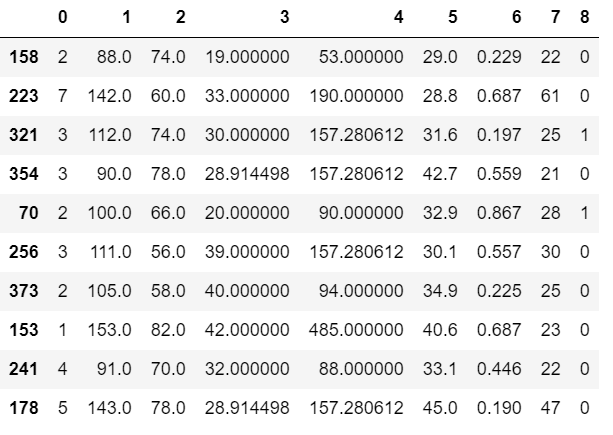
También podemos hacer esto usando la clase SimpleImputer. SimpleImputer es una clase de scikit-learn que es útil para manejar los datos que faltan en el conjunto de datos del modelo predictivo. Reemplaza los valores de NaN con un marcador de posición específico. Se implementa mediante el uso del método SimpleImputer() que toma los siguientes argumentos:
SimpleImputer(missing_values, estrategia, fill_value)
- valores_perdidos : El marcador de posición de valores_perdidos que se debe imputar. Por defecto es NaN.
- estrategia : los datos que reemplazarán los valores de NaN del conjunto de datos. El argumento de la estrategia puede tomar los valores: ‘media’ (predeterminado), ‘mediana’, ‘más_frecuente’ y ‘constante’.
- fill_value : El valor constante que se le dará a los datos de NaN usando la estrategia constante.
Python3
# import modules
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
# defining the imputer
imputer = SimpleImputer(missing_values=nan,
strategy='mean')
# transform the dataset
transformed_values = imputer.fit_transform(value)
# count the number of NaN values in each column
print("Missing:", isnan(transformed_values).sum())

Enfoque #3
Primero imputamos los valores perdidos por la mediana de los datos. La mediana es el valor medio de un conjunto de datos. Para determinar el valor de la mediana en una secuencia de números, primero se deben ordenar los números en orden ascendente.
Python3
# filling missing values # with mean column values df.fillna(df.median(), inplace=True) df.head(10)
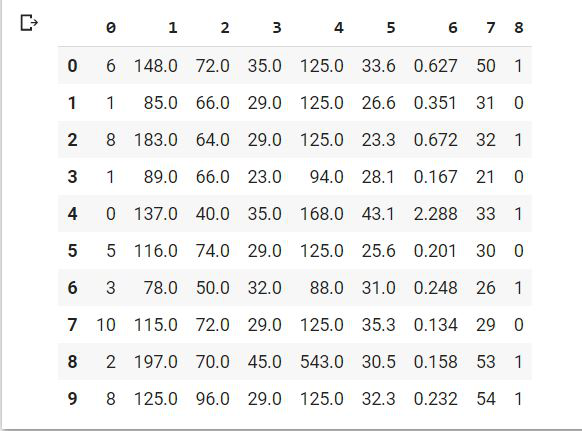
También podemos hacer esto usando la clase SimpleImputer .
Python3
# import modules
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
# defining the imputer
imputer = SimpleImputer(missing_values=nan,
strategy='median')
# transform the dataset
transformed_values = imputer.fit_transform(value)
# count the number of NaN values in each column
print("Missing:", isnan(transformed_values).sum())
Enfoque #4
Primero imputamos los valores faltantes por la moda de los datos. La moda es el valor que ocurre con mayor frecuencia en un conjunto de observaciones. Por ejemplo, {6, 3, 9, 6, 6, 5, 9, 3} la Moda es 6, ya que ocurre con mayor frecuencia.
Python3
# filling missing values # with mean column values df.fillna(df.mode(), inplace=True) df.sample(10)
También podemos hacer esto usando la clase SimpleImputer .
Python3
# import modules
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
# defining the imputer
imputer = SimpleImputer(missing_values=nan,
strategy='most_frequent')
# transform the dataset
transformed_values = imputer.fit_transform(value)
# count the number of NaN values in each column
print("Missing:", isnan(transformed_values).sum())
Publicación traducida automáticamente
Artículo escrito por vanisinghal0201 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA