A veces, en el marco de datos, cuando los datos de la columna contienen el contenido largo o la oración grande, PySpark SQL muestra el marco de datos en forma comprimida, lo que significa que se muestran las primeras palabras de la oración y otras son seguidas por puntos que indican que hay más datos disponibles.
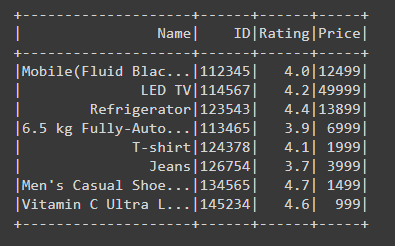
Del marco de datos de muestra anterior, podemos ver fácilmente que el contenido de la columna Nombre no se muestra completamente. PySpark hace esto automáticamente para mostrar el marco de datos sistemáticamente de esta manera, el marco de datos no se ve desordenado, pero en algunos casos, debemos leer o ver el contenido completo de la columna en particular.
Entonces, en este artículo, vamos a aprender cómo mostrar el contenido completo de la columna en PySpark Dataframe. La única manera de mostrar el contenido completo de la columna es usando la función show().
Sintaxis: df.show(n, truncar=Verdadero)
Donde df es el marco de datos
- show(): la función se usa para mostrar el marco de datos.
- n: Número de filas a mostrar.
- truncar: a través de este parámetro, podemos decirle al receptor de salida que muestre el contenido completo de la columna configurando la opción truncar en falso, por defecto este valor es verdadero.
Ejemplo 1: Mostrar el contenido completo de la columna de PySpark Dataframe.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Product_details.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Mobile(Fluid Black, 8GB RAM, 128GB Storage)",
112345, 4.0, 12499),
("LED TV", 114567, 4.2, 49999),
("Refrigerator", 123543, 4.4, 13899),
("6.5 kg Fully-Automatic Top Loading Washing Machine \
(WA65A4002VS/TL, Imperial Silver, Center Jet Technology)",
113465, 3.9, 6999),
("T-shirt", 124378, 4.1, 1999),
("Jeans", 126754, 3.7, 3999),
("Men's Casual Shoes in White Sneakers for Outdoor and\
Daily use", 134565, 4.7, 1499),
("Vitamin C Ultra Light Gel Oil-Free Moisturizer",
145234, 4.6, 999),
]
schema = ["Name", "ID", "Rating", "Price"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# visualizing full content of the Dataframe
# by setting truncate to False
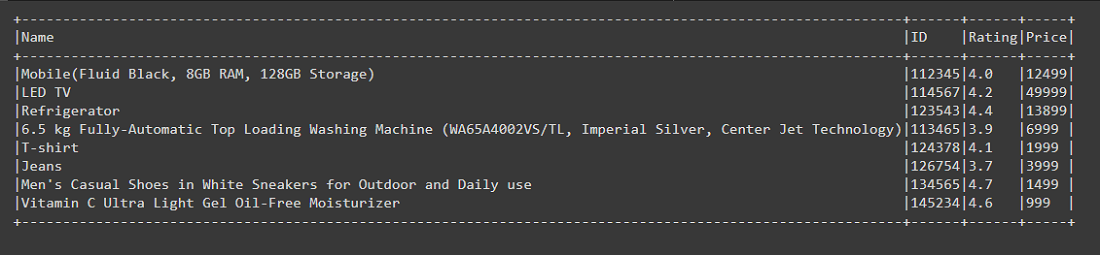
df.show(truncate=False)
Producción:
Ejemplo 2: mostrar el contenido de la columna completa del marco de datos estableciendo truncar en 0.
En el ejemplo, estamos configurando el parámetro truncar = 0, aquí si configuramos cualquier número entero desde 1 en adelante como 3, entonces mostrará el contenido de la columna hasta tres caracteres o lugares enteros, no más que eso como se muestra a continuación. higo. Pero aquí, en lugar de Falso, si pasamos 0, esto también actuará como Falso, como en el número binario 0 se refiere a falso y muestra el contenido completo de la columna en el marco de datos.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",80,"Good Performance"),
(2,"Arpita","Female",18,"Have to work hard otherwise \
result will not improve"),
(3,"Raj","Male",21,"Work hard can do better"),
(4,"Swati","Female",69,"Good performance can do more better"),
(5,"Arpit","Male",20,"Focus on some subject to improve"),
(6,"Swaroop","Male",65,"Good performance"),
(7,"Reshabh","Male",70,"Good performance"),
(8,"Dinesh","Male",65,"Can do better"),
(9,"Rohit","Male",55,"Can do better"),
(10,"Sanjana","Female",67,"Have to work hard")]
schema = ["ID","Name","Gender","Percentage","Remark"]
# calling function to create dataframe
df = create_df(spark,input_data,schema)
# visualizing full column content of the dataframe by setting truncate to 0
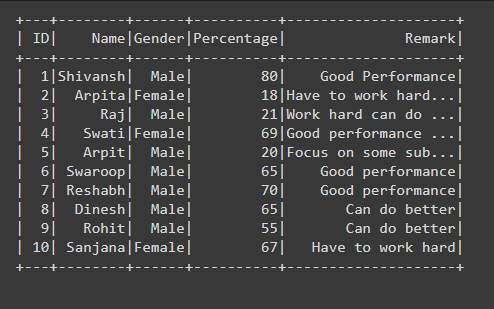
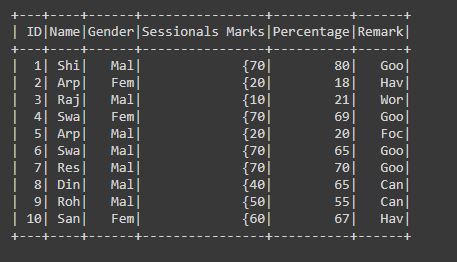
df.show(truncate=0)
Producción:
Ejemplo 3: Mostrar el contenido completo de la columna de PySpark Dataframe usando la función show().
En el código para mostrar el contenido completo de la columna, usamos la función show() al pasar el parámetro df.count(),truncate=False, podemos escribir como df.show(df.count(), truncate=False) , aquí se muestra La función toma el primer parámetro como n, es decir, el número de filas a mostrar, ya que df.count() devuelve el recuento del número total de filas presentes en el marco de datos, como en el caso anterior, el número total de filas es 10, por lo que en La función show() n se pasa como 10, que no es más que el número total de filas para mostrar.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1, "Shivansh", "Male", (70, 66, 78, 70, 71, 50), 80,
"Good Performance"),
(2, "Arpita", "Female", (20, 16, 8, 40, 11, 20), 18,
"Have to work hard otherwise result will not improve"),
(3, "Raj", "Male", (10, 26, 28, 10, 31, 20),
21, "Work hard can do better"),
(4, "Swati", "Female", (70, 66, 78, 70, 71, 50),
69, "Good performance can do more better"),
(5, "Arpit", "Male", (20, 46, 18, 20, 31, 10),
20, "Focus on some subject to improve"),
(6, "Swaroop", "Male", (70, 66, 48, 30, 61, 50),
65, "Good performance"),
(7, "Reshabh", "Male", (70, 66, 78, 70, 71, 50),
70, "Good performance"),
(8, "Dinesh", "Male", (40, 66, 68, 70, 71, 50),
65, "Can do better"),
(9, "Rohit", "Male", (50, 66, 58, 50, 51, 50),
55, "Can do better"),
(10, "Sanjana", "Female", (60, 66, 68, 60, 61, 50),
67, "Have to work hard")]
schema = ["ID", "Name", "Gender",
"Sessionals Marks", "Percentage", "Remark"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# visualizing full column content of the
# dataframe by setting n and truncate to
# False
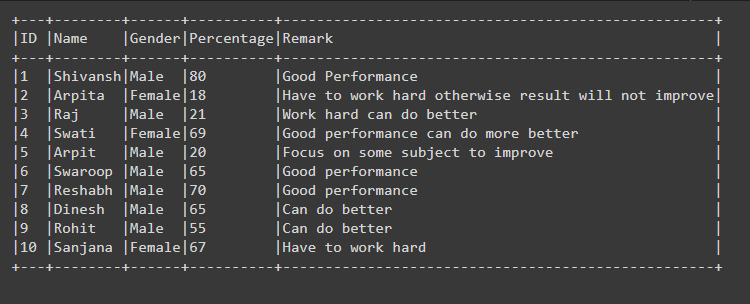
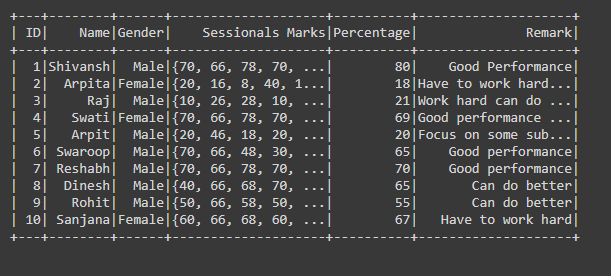
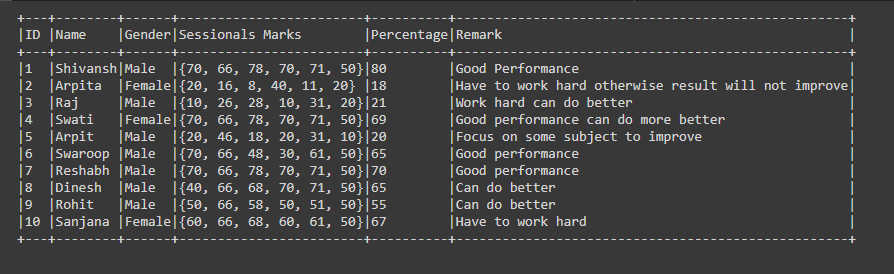
df.show(df.count(), truncate=False)
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA