En este artículo, vamos a obtener los datos distintos del marco de datos pyspark en Python, por lo que vamos a crear el marco de datos utilizando una lista anidada y obtener los datos distintos.
Vamos a crear un marco de datos a partir de la lista pyspark sin pasar por la lista al método createDataFrame() de pyspark, luego, al usar la función distintiva() obtendremos las filas distintas del marco de datos.
Sintaxis: dataframe.distinct()
Donde dataframe es el nombre del marco de datos creado a partir de las listas anidadas usando pyspark
Ejemplo 1 : código de Python para obtener los datos distintos de los datos de la universidad en un marco de datos creado por una lista de listas.
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of college data
data = [["1", "bobby", "vvit"],
["2", "sravan", "jntuk"],
["3", "rohith", "AU"],
["4", "sridevi", "GVRS"],
["1", "bobby", "vvit"]]
# specify column names
columns = ['ID', 'NAME', 'COLLEGE']
# creating a dataframe from the
# lists of data
dataframe = spark.createDataFrame(data, columns)
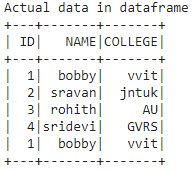
print('Actual data in dataframe')
dataframe.show()
Producción:
Ahora obtenga las filas distintas en el marco de datos:
Python3
print('distinct data')
# display distinct data
dataframe.distinct().show()
Producción:

Ejemplo 2: programa de Python para encontrar valores distintos de 1 fila
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of college data
data = [["1", "bobby", "vvit"]]
# specify column names
columns = ['ID', 'NAME', 'COLLEGE']
# creating a dataframe from the
# list of data
dataframe = spark.createDataFrame(data, columns)
print('Actual data in dataframe')
dataframe.show()
Producción:

Ahora obtenga las filas distintas en el marco de datos:
Python3
print('distinct data')
# display distinct data from
# the dataframe
dataframe.distinct().show()
Producción:

Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA