Python es un buen lenguaje para realizar análisis de datos debido al increíble ecosistema de paquetes de Python centrados en datos. El paquete Pandas es uno de ellos y facilita mucho la importación y el análisis de datos.
Aquí, discutiremos cómo omitir filas al leer el archivo csv. Usaremos el método read_csv() de la biblioteca Pandas para esta tarea.
Sintaxis:pd.read_csv(filepath_or_buffer, sep=’, ‘, delimitador=Ninguno, encabezado=’inferir’, nombres=Ninguno, index_col=Ninguno, usecols=Ninguno, squeeze=False, prefix=Ninguno, mangle_dupe_cols=True, dtype=Ninguno, motor=Ninguno, convertidores=Ninguno, valores_verdaderos=Ninguno, valores_falsos=Ninguno, skipinitialspace=False, skiprows=Ninguno, nrows=Ninguno, na_values=Ninguno, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates= Falso, infer_datetime_format=False, keep_date_col=False, date_parser=Ninguno, dayfirst=False, iterator=False, chunksize=Ninguno,pression=’infer’, miles=Ninguno, decimal=b’.’, lineterminator=Ninguno, quotechar=’ ”’, comillas=0, escapechar=Ninguna, comentario=Ninguna, codificación=Ninguna, dialecto=Ninguna, tupleize_cols=Ninguna, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True , memory_map=Falso,float_precision=Ninguno)
Algunos parámetros útiles se dan a continuación:
| Parámetro | Usar |
|---|---|
| ruta_archivo_o_búfer | Ubicación URL o directorio del archivo |
| sep | Significa separador, el valor predeterminado es ‘,’ como en csv (valores separados por comas) |
| index_col | Este parámetro se usa para hacer que la columna pasada sea un índice en lugar de 0, 1, 2, 3…r |
| encabezamiento | Este parámetro se usa para pasar la fila/s[int/int list] como encabezado |
| use_cols | Este parámetro solo usa la columna pasada [lista de strings] para crear un marco de datos |
| estrujar | Si es Verdadero y solo se pasa una columna, devuelve la serie pandas |
| salteadores | Este parámetro se usa para omitir las filas pasadas en el nuevo marco de datos |
| saltarín | Este parámetro se usa para omitir Número de líneas al final del archivo |
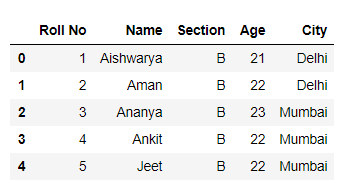
Para descargar el archivo student.csv Haga clic aquí
Método 1: Saltarse N filas desde el principio mientras se lee un archivo csv.
Código:
Python3
# Importing Pandas library
import pandas as pd
# Skipping 2 rows from start in csv
# and initialize it to a dataframe
df = pd.read_csv("students.csv",
skiprows = 2)
# Show the dataframe
df
Producción :
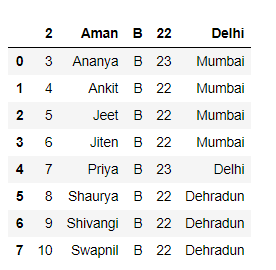
Método 2: saltar filas en posiciones específicas al leer un archivo csv.
Código:
Python3
# Importing Pandas library
import pandas as pd
# Skipping rows at specific position
df = pd.read_csv("students.csv",
skiprows = [0, 2, 5])
# Show the dataframe
df
Producción :
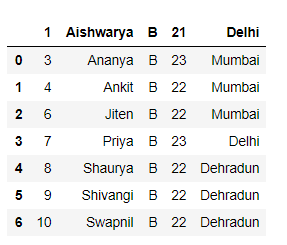
Método 3: Saltarse N filas desde el principio, excepto los nombres de las columnas mientras se lee un archivo csv.
Código:
Python3
# Importing Pandas library
import pandas as pd
# Skipping 2 rows from start
# except the column names
df = pd.read_csv("students.csv",
skiprows = [i for i in range(1, 3) ])
# Show the dataframe
df
Producción :
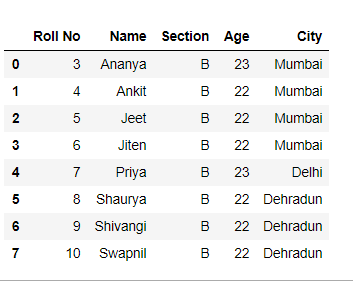
Método 4: omita filas según una condición mientras lee un archivo csv.
Código:
Python3
# Importing Pandas library
import pandas as pd
# function for checking and
# skipping every 3rd line
def logic(index):
if index % 3 == 0:
return True
return False
# Skipping rows based on a condition
df = pd.read_csv("students.csv",
skiprows = lambda x: logic(x) )
# Show the dataframe
df
Producción :
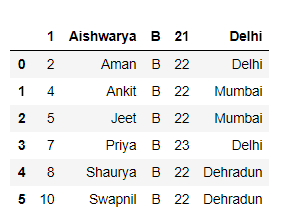
Método 5: salte N filas desde el final mientras lee un archivo csv.
Código:
Python3
# Importing Pandas library
import pandas as pd
# Skipping 2 rows from end
df = pd.read_csv("students.csv",
skipfooter = 5,
engine = 'python')
# Show the dataframe
df
Producción :