En este artículo, discutiremos cómo ordenar datos agrupados según el tamaño del grupo en Pandas.
Funciones utilizadas
Aquí pasaremos las entradas a través de la lista como una estructura de datos de diccionario.
- groupby(): groupby() se utiliza para agrupar los datos en función de los valores de la columna.
- size(): Esto se usa para obtener el tamaño del marco de datos.
- sort_values(): esta función ordena un marco de datos en orden ascendente o descendente de la columna pasada.
La tarea es sencilla, para un marco de datos dado, primero debemos agrupar por cualquier columna según el requisito y luego organizar los valores agrupados de la columna según su tamaño. Por tamaño aquí nos referimos a cuántas veces ha aparecido un valor en una columna o su frecuencia.
Ejemplo 1:
Python3
# importing pandas module for dataframe
import pandas as pd
# creating a dataframe with student
# name and subject
dataframe1 = pd.DataFrame({'student_name': ['bobby', 'ojaswi', 'gnanesh',
'rohith', 'karthik', 'sudheer',
'vani'],
'subjects': ['dbms', 'python', 'dbms', 'oops',
'oops', 'oops', 'dbms']})
# display dataframe
print(dataframe1)
# group the data on subjects column based on
# size and sort in descending order
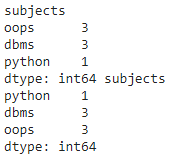
a = dataframe1.groupby('subjects').size().sort_values(ascending=False)
# group the data on subjects column based on
# size and sort in ascending order
b = dataframe1.groupby('subjects').size().sort_values(ascending=True)
print(a, b)
Producción:

Ejemplo 2:
Python3
# importing pandas module for dataframe
import pandas as pd
# creating a dataframe with student name
# , subject and address
dataframe1 = pd.DataFrame({'student_name': ['bobby', 'ojaswi', 'gnanesh',
'rohith', 'karthik', 'sudheer',
'vani'],
'subjects': ['dbms', 'python', 'dbms', 'oops',
'oops', 'oops', 'dbms'],
'address': ['ponnur', 'ponnur', 'hyd', 'tenali',
'tenali', 'hyd', 'patna']})
# display dataframe
print(dataframe1)
# group the data on address column based
# on size and sort in descending order
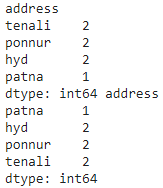
a = dataframe1.groupby('address').size().sort_values(ascending=False)
# group the data on address column based
# on size and sort in ascending order
b = dataframe1.groupby('address').size().sort_values(ascending=True)
print(a, b)
Producción:

También podemos agrupar las múltiples columnas. La sintaxis sigue siendo la misma, pero necesitamos pasar las columnas múltiples en una lista y pasar la lista en groupby()
Sintaxis:
dataframe.groupby([columna1,columna2,.columna n]).size().sort_values(ascending=True)
Ejemplo 3:
Python3
# importing pandas module for dataframe
import pandas as pd
# creating a dataframe with student
# name , subject and address
dataframe1 = pd.DataFrame({'student_name': ['bobby', 'ojaswi', 'gnanesh',
'rohith', 'karthik', 'sudheer',
'vani'],
'subjects': ['dbms', 'python', 'dbms', 'oops',
'oops', 'oops', 'dbms'],
'address': ['ponnur', 'ponnur', 'hyd', 'tenali',
'tenali', 'hyd', 'patna']})
# display dataframe
print(dataframe1)
# group the data on address and subjects
# column based on size and sort in descending
# order
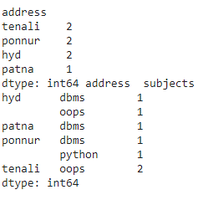
a = dataframe1.groupby(['address', 'subjects']
).size().sort_values(ascending=False)
# group the data on address and subjects
# column based on size and sort in ascending
# order
b = dataframe1.groupby(['address', 'subjects']
).size().sort_values(ascending=True)
print(a, b)
Producción:

Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA