El método Pandas dataframe.sort_index()ordena los objetos por etiquetas a lo largo del eje dado. Básicamente, el algoritmo de clasificación se aplica en las etiquetas de los ejes en lugar de los datos reales en el marco de datos y, en función de eso, los datos se reorganizan. Tenemos la libertad de elegir qué algoritmo de clasificación nos gustaría aplicar. Hay tres posibles algoritmos de clasificación que podemos usar ‘quicksort’, ‘mergesort’ y ‘heapsort’.
Sintaxis: DataFrame.sort_index(axis=0, level=Ninguno, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’, sort_remaining=True, by=Ninguno)
Parámetros:
eje: p para el índice, 1 para las columnas para dirigir el nivel de clasificación :
si no es Ninguno , ordenar los valores en los niveles de índice especificados. marco de datos real de lo contrario, devuelve un marco de datos ordenado. tipo: {‘clasificación rápida’, ‘clasificación combinada’, ‘clasificación en montón’}, por defecto ‘clasificación rápida’. Elección del algoritmo de clasificación. Consulte también ndarray.np.sort para obtener más información. mergesort es el único algoritmo estable. Para DataFrames, esta opción solo se aplica cuando se ordena en una sola columna o etiqueta. posición_na :
[{‘first’, ‘last’}, default ‘last’] First pone NaNs al principio, last pone NaNs al final. No implementado para MultiIndex.
sort_remaining : si es verdadero y la ordenación por nivel e índice es multinivel, ordenar por otros niveles también (en orden) después de ordenar por nivel especificadoRetorno: sorted_obj: DataFrame
Cree un marco de datos simple con un diccionario de listas, digamos que los nombres de las columnas son: ‘Nombre’, ‘Edad’, ‘Lugar’ y ‘Colegio’.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f', 'g',
'i', 'j', 'k', 'd'])
# show the dataframe
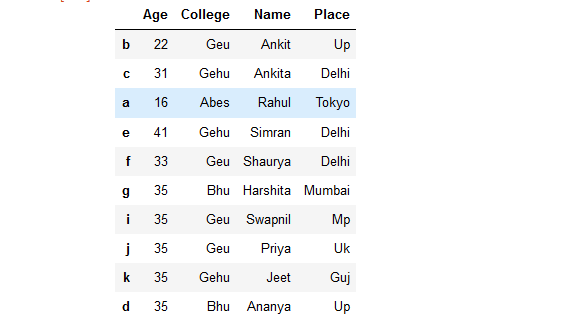
details
Producción: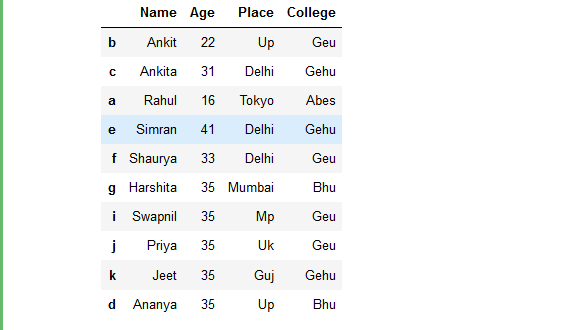
Ejemplo 1: ordenar las filas del marco de datos según los nombres de las etiquetas de índice de fila.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort the rows of dataframe
# based on row index
rslt_df = details.sort_index()
# show the resultant Dataframe
rslt_df
Producción: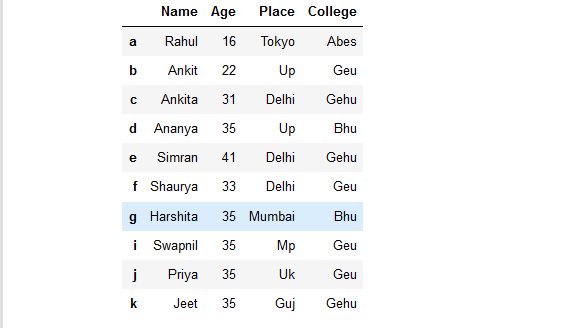
Ejemplo 2: ordenar las filas de un marco de datos en orden descendente en función de las etiquetas de índice de fila.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort the rows of dataframe in descending
# order based on row index
rslt_df = details.sort_index(ascending = False)
# show the resultant Dataframe
rslt_df
Producción: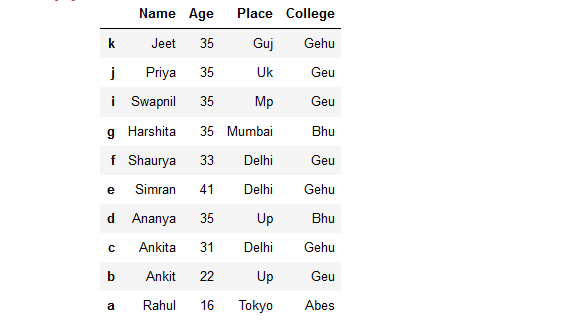
Ejemplo 3: ordenar filas de un marco de datos en función de las etiquetas de índice de fila en el lugar.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort the rows of dataframe in Place
# based on row index
details.sort_index(inplace = True)
# show the resultant Dataframe
details
Producción: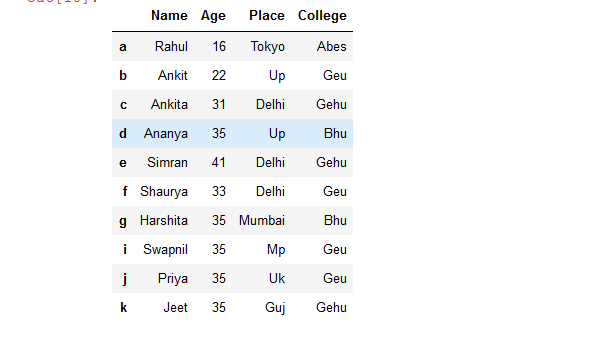
Ejemplo 4: ordenar las columnas de un marco de datos en función de los nombres de las columnas.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort a dataframe based on column names
rslt_df = details.sort_index(axis = 1)
# show the resultant Dataframe
rslt_df
Producción: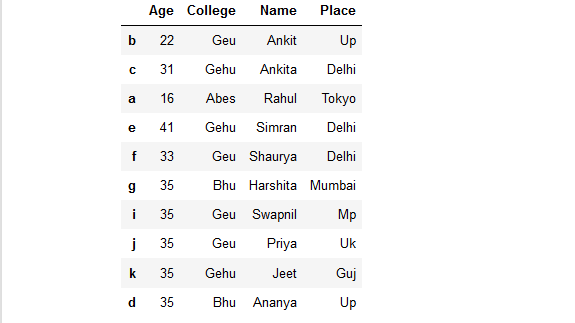
Ejemplo 5: ordenar un marco de datos en orden descendente según los nombres de las columnas.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort a dataframe in descending
# order based on column names
rslt_df = details.sort_index(ascending = False, axis = 1)
# show the resultant Dataframe
rslt_df
Producción: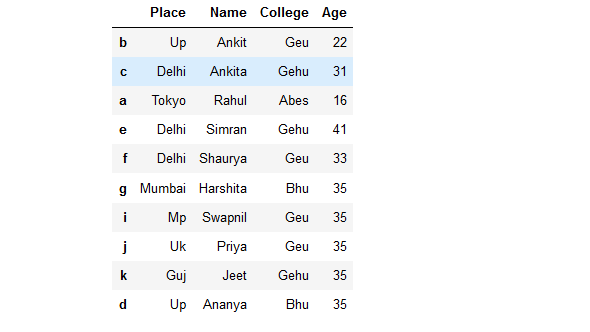
Ejemplo 6: ordenar un marco de datos en su lugar según los nombres de las columnas.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort a dataframe in place
# based on column names
details.sort_index(inplace = True, axis = 1)
# show the resultant Dataframe
details
Producción: