El análisis de conglomerados o agrupamiento es una técnica para encontrar subgrupos de puntos de datos dentro de un conjunto de datos. Los puntos de datos que pertenecen al mismo subgrupo tienen características o propiedades similares. La agrupación en clústeres es un enfoque de aprendizaje automático no supervisado y tiene una amplia variedad de aplicaciones, como estudios de mercado, reconocimiento de patrones, sistemas de recomendación, etc. Los algoritmos más comunes utilizados para el agrupamiento son el agrupamiento de K-medias y el análisis de conglomerados jerárquicos. En este artículo, aprenderemos sobre el análisis de conglomerados jerárquicos y su implementación en la programación R.
El análisis de conglomerados jerárquicos (también conocido como conglomerado jerárquico) es una técnica de conglomerado en la que los conglomerados tienen una jerarquía o un orden predeterminado. El agrupamiento jerárquico se puede representar mediante una estructura similar a un árbol llamada dendrograma . Hay dos tipos de agrupamiento jerárquico:
- Agrupación jerárquica aglomerativa : este es un enfoque de abajo hacia arriba en el que cada punto de datos comienza en su propio grupo y, a medida que uno asciende en la jerarquía, se fusionan pares de grupos similares.
- Agrupación jerárquica divisiva : este es un enfoque de arriba hacia abajo en el que todos los puntos de datos comienzan en un grupo y, a medida que se desciende en la jerarquía, los grupos se dividen recursivamente.
Para medir la similitud o diferencia entre un par de puntos de datos, usamos medidas de distancia (distancia euclidiana, distancia de Manhattan, etc.). Sin embargo, para encontrar la disimilitud entre dos grupos de observaciones, usamos métodos de aglomeración. Los métodos de aglomeración más comunes son:
- Agrupamiento de enlace completo : calcula todas las diferencias por pares entre las observaciones en dos grupos y considera la distancia más larga (máxima) entre dos puntos como la distancia entre dos grupos.
- Agrupamiento de enlace simple : calcula todas las diferencias por pares entre las observaciones en dos grupos y considera la distancia más corta (mínima) como la distancia entre dos grupos.
- Agrupamiento de vinculación promedio : calcula todas las diferencias por pares entre las observaciones en dos grupos y considera la distancia promedio como la distancia entre dos grupos.
Realización de análisis de conglomerados jerárquicos con R
Para calcular el agrupamiento jerárquico en R, las funciones comúnmente utilizadas son las siguientes:
- hclust en el paquete stats y agnes en el paquete cluster para el agrupamiento jerárquico aglomerativo.
- diana en el paquete cluster para clustering jerárquico divisivo.
Usaremos el conjunto de datos de flores de Iris del paquete de conjuntos de datos en nuestra implementación. Usaremos la columna de ancho de sépalo, longitud de sépalo, ancho de pétalo y longitud de pétalo como nuestros puntos de datos. Primero, cargamos y normalizamos los datos. Luego, los valores de disimilitud se calculan con la función dist y estos valores se alimentan a las funciones de agrupación para realizar la agrupación jerárquica.
R
# Load required packages library(datasets) # contains iris dataset library(cluster) # clustering algorithms library(factoextra) # visualization library(purrr) # to use map_dbl() function # Load and preprocess the dataset df <- iris[, 1:4] df <- na.omit(df) df <- scale(df) # Dissimilarity matrix d <- dist(df, method = "euclidean")
Implementación de agrupamiento jerárquico aglomerativo
La array de disimilitud obtenida se alimenta a hclust . El parámetro de método de hclust especifica el método de aglomeración que se utilizará (es decir, completo, promedio, único). Entonces podemos trazar el dendograma.
R
# Hierarchical clustering using Complete Linkage hc1 <- hclust(d, method = "complete" ) # Plot the obtained dendrogram plot(hc1, cex = 0.6, hang = -1)
Producción:
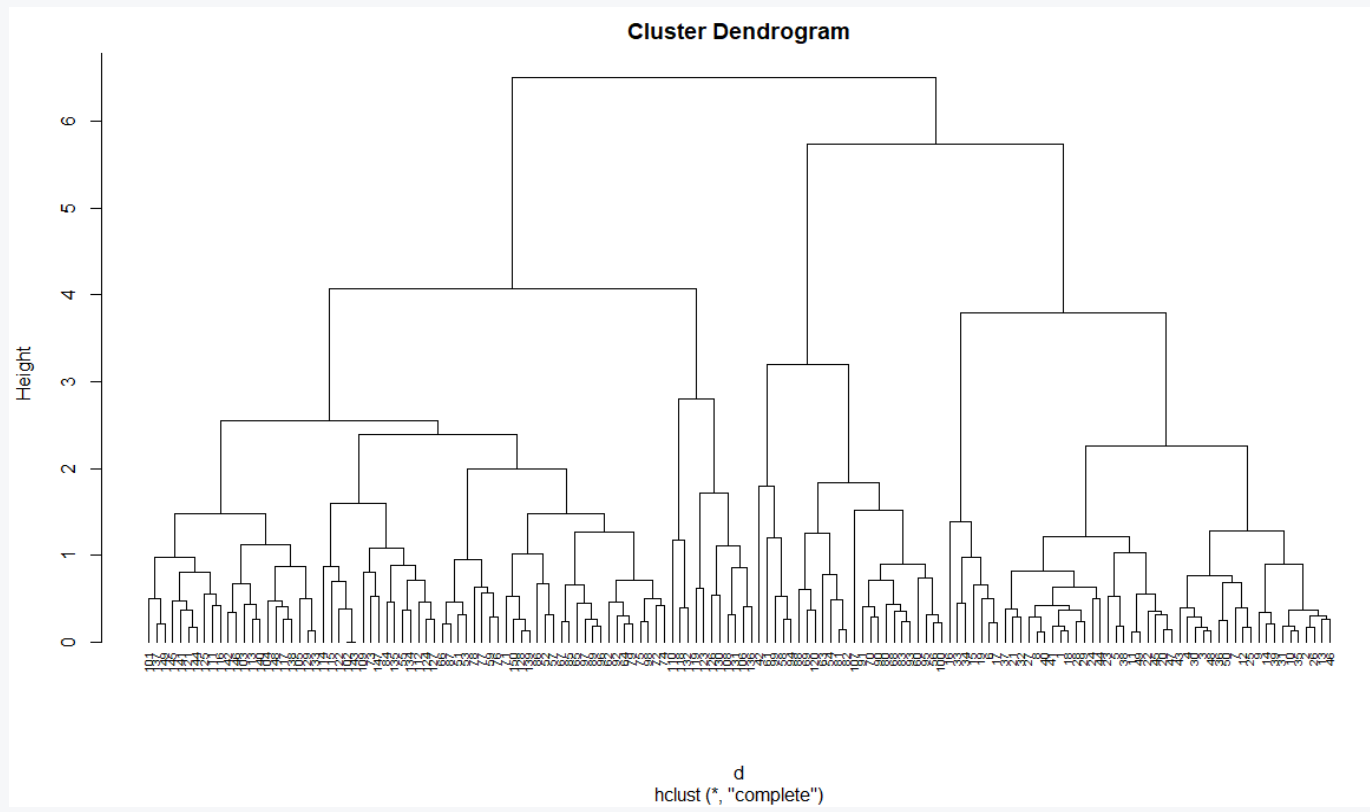
Observe que en el dendrograma anterior, una hoja corresponde a una observación y, a medida que avanzamos en el árbol, las observaciones similares se fusionan a mayor altura. La altura del dendrograma determina los grupos. Para identificar los clusters, podemos cortar el dendrograma con cutree . Luego visualice el resultado en un diagrama de dispersión utilizando la función fviz_cluster del paquete factoextra .
R
# Cut tree into 3 groups sub_grps <- cutree(hc1, k = 3) # Visualize the result in a scatter plot fviz_cluster(list(data = df, cluster = sub_grps))
Producción:
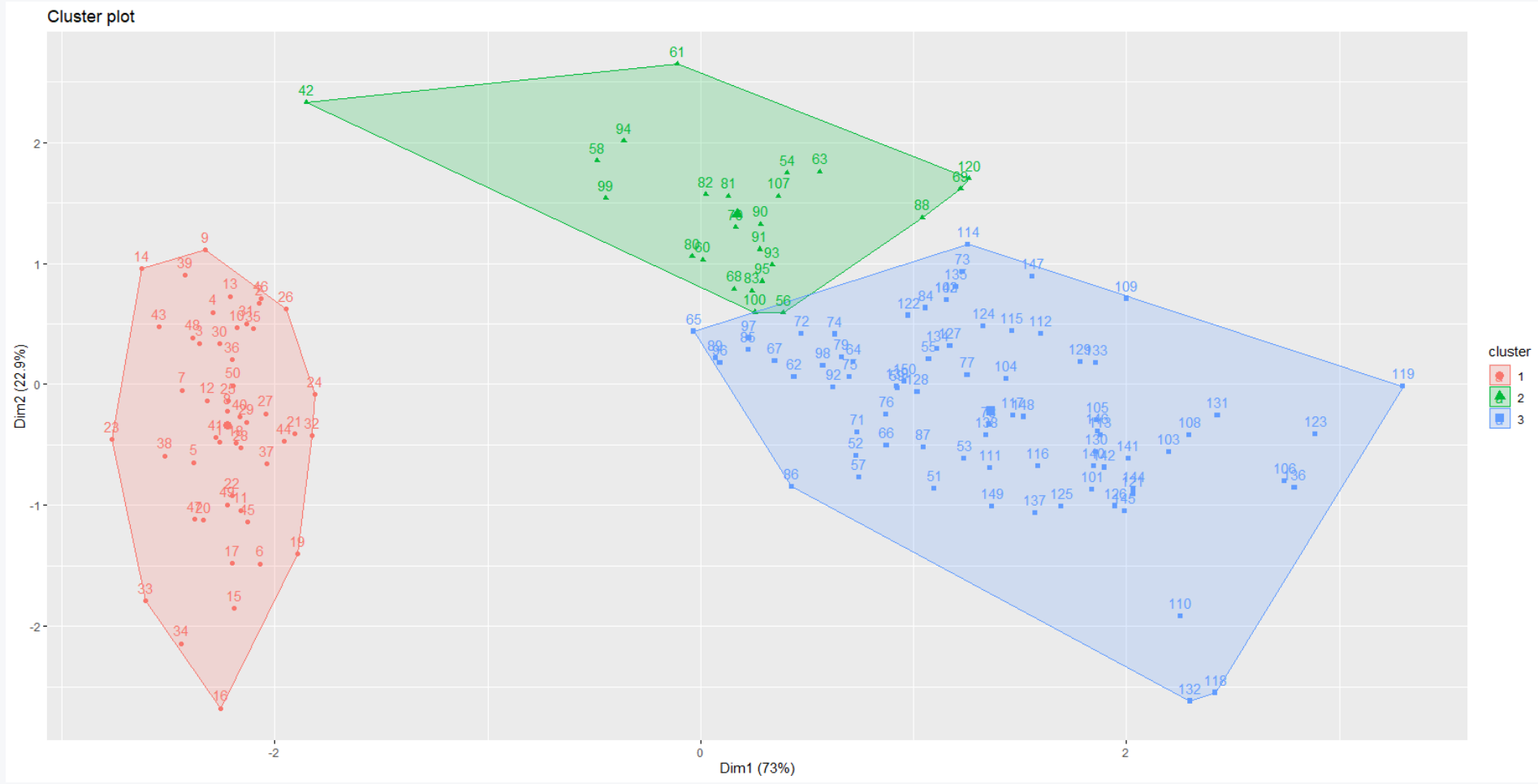
También podemos proporcionar un borde al dendrograma alrededor de los 3 grupos como se muestra a continuación.
R
# Plot the obtained dendrogram with # rectangle borders for k clusters plot(hc1, cex = 0.6, hang = -1) rect.hclust(hc1, k = 3, border = 2:4)
Producción:
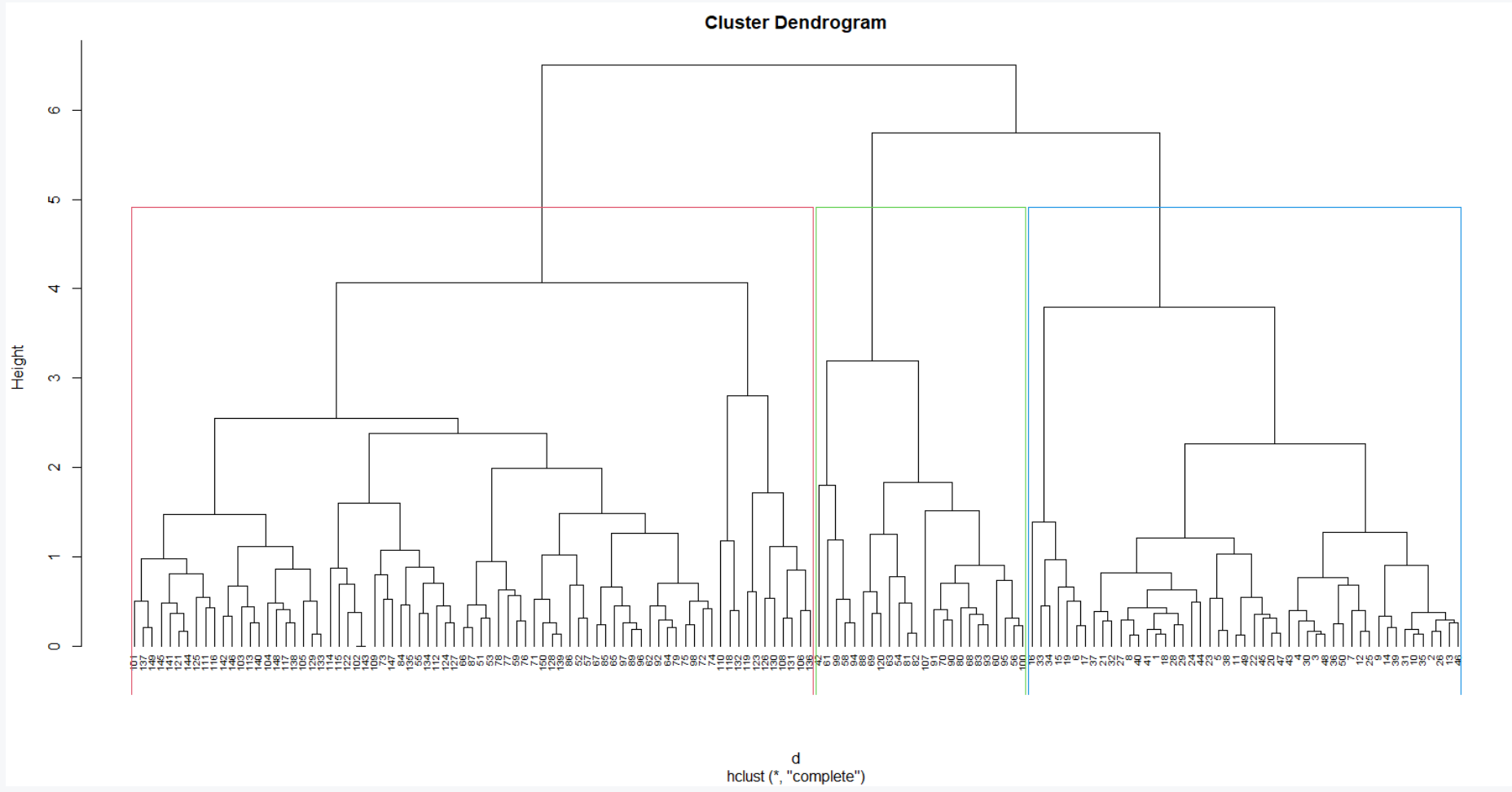
Alternativamente, podemos usar la función agnes para realizar el agrupamiento jerárquico. A diferencia de hclust , la función agnes proporciona el coeficiente de aglomeración, que mide la cantidad de estructura de agrupamiento encontrada (los valores más cercanos a 1 sugieren una estructura de agrupamiento fuerte).
R
# agglomeration methods to assess
m <- c("average", "single", "complete")
names(m) <- c("average", "single", "complete")
# function to compute hierarchical
# clustering coefficient
ac <- function(x) {
agnes(df, method = x)$ac
}
map_dbl(m, ac)
Producción:
average single complete 0.9035705 0.8023794 0.9438858
El enlace completo da una estructura de agrupamiento más fuerte. Entonces, usamos este método de aglomeración para realizar un agrupamiento jerárquico con la función agnes como se muestra a continuación.
R
# Hierarchical clustering hc2 <- agnes(df, method = "complete") # Plot the obtained dendrogram pltree(hc2, cex = 0.6, hang = -1, main = "Dendrogram of agnes")
Producción:
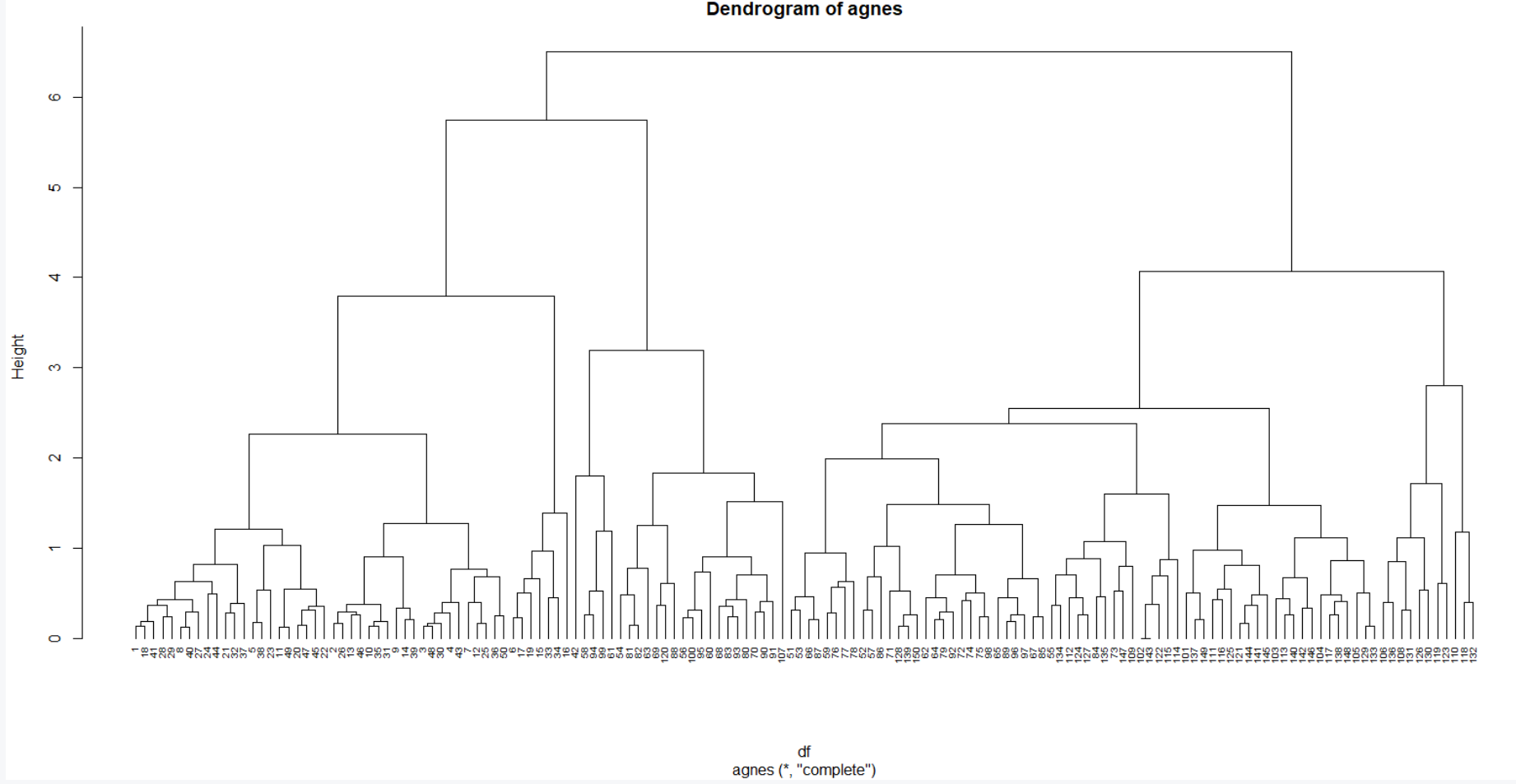
Implementación de agrupamiento divisivo
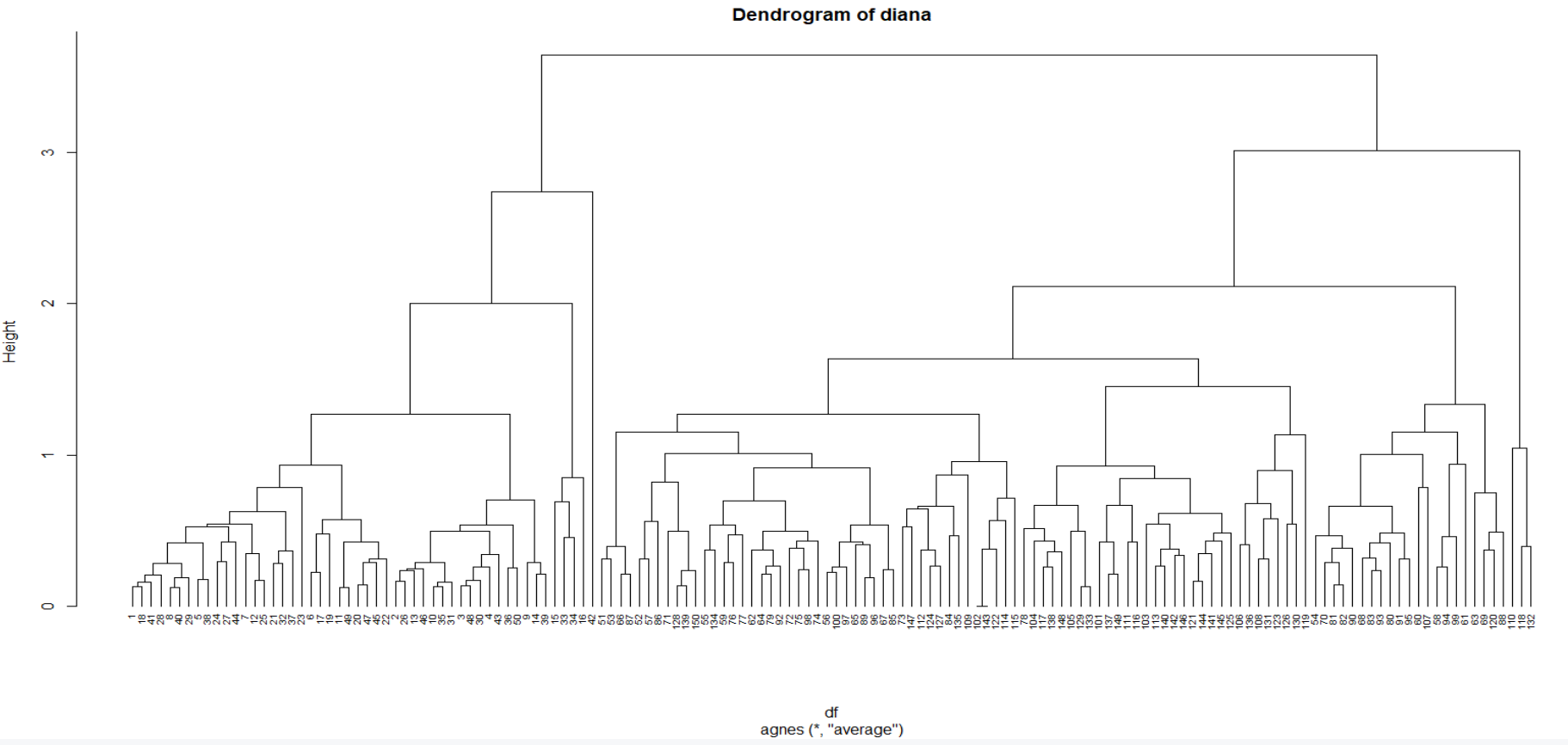
La función diana , que funciona de manera similar a agnes , nos permite realizar un agrupamiento jerárquico divisivo. Sin embargo, no hay ningún método para proporcionar.
R
# Compute divisive hierarchical clustering hc3 <- diana(df) # Divise coefficient hc3$dc # Plot obtained dendrogram pltree(hc3, cex = 0.6, hang = -1, main = "Dendrogram of diana")
Producción:
[1] 0.9397208
Publicación traducida automáticamente
Artículo escrito por akshisaxena y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA