Una array generalmente consta de una combinación de ceros y no ceros. Cuando una array se compone principalmente de ceros, dicha array se denomina array dispersa. Una array que consta de un máximo de números distintos de cero, dicha array se denomina array densa. La array dispersa encuentra su aplicación en problemas de aprendizaje profundo y aprendizaje automático de alta dimensión. En otras palabras, cuando una array tiene muchos de sus coeficientes como cero, se dice que dicha array es escasa.
El área común donde nos encontramos con problemas de dimensionalidad tan escasos es
- Procesamiento del lenguaje natural : es obvio que la mayoría de los elementos vectoriales del documento serán 0 en los modelos de lenguaje.
- Visión por computadora : a veces una imagen puede estar ocupada por un color similar (por ejemplo, blanco que puede ser un fondo) que no nos brinda ninguna información útil.
En tales casos, no podemos darnos el lujo de tener una array de array dimensional grande, ya que puede aumentar la complejidad espacial y temporal del problema, por lo que se recomienda reducir la dimensionalidad de la array dispersa. En este artículo, discutamos la implementación de cómo reducir la dimensionalidad de la array dispersa en Python.
La dimensionalidad de la array dispersa se puede reducir representando primero la array densa como una representación de fila dispersa comprimida en la que la array dispersa se representa utilizando tres arrays unidimensionales para los valores distintos de cero, la extensión de las filas y la columna. índices Luego, mediante el uso de TruncatedSVD de scikit-learn, es posible reducir la dimensionalidad de la array dispersa.
Ejemplo:
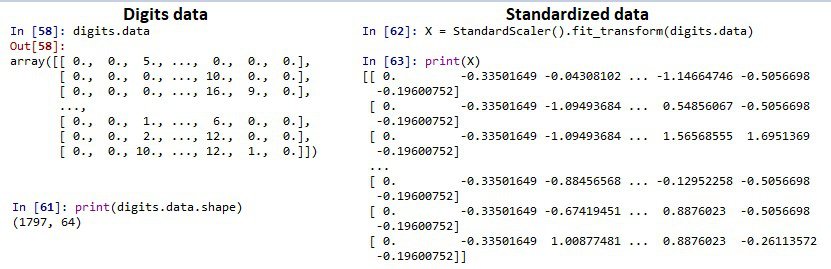
Primero, cargue el conjunto de datos de dígitos incorporado del paquete scikit-learn, estandarice cada punto de datos usando el escalador estándar. Representa la array estandarizada en su forma dispersa usando csr_matrix como se muestra. Ahora importe el TruncatedSVD de sklearn y especifique el no. de dimensiones requeridas en el resultado final Finalmente verifique la forma de la array reducida
Python3
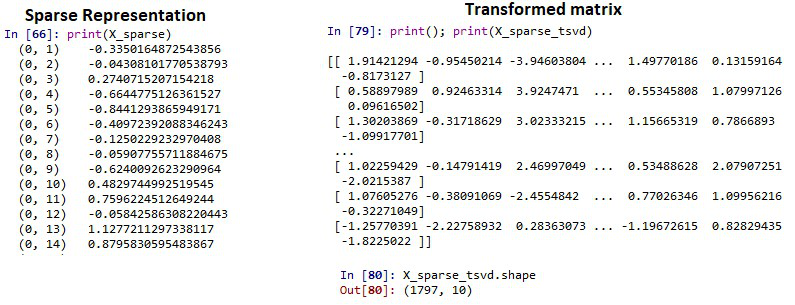
from sklearn.preprocessing import StandardScaler from sklearn.decomposition import TruncatedSVD from scipy.sparse import csr_matrix from sklearn import datasets from numpy import count_nonzero # load the inbuild digits dataset digits = datasets.load_digits() print(digits.data) # shape of the dense matrix print(digits.data.shape) # standardizing the data points X = StandardScaler().fit_transform(digits.data) print(X) # representing in CSR form X_sparse = csr_matrix(X) print(X_sparse) # specify the no of output features tsvd = TruncatedSVD(n_components=10) # apply the truncatedSVD function X_sparse_tsvd = tsvd.fit(X_sparse).transform(X_sparse) print(X_sparse_tsvd) # shape of the reduced matrix print(X_sparse_tsvd.shape)
Producción:
Código:
Verifiquemos de forma cruzada la dimensión original y la dimensión transformada.
Python3
print("Original number of features:", X.shape[1])
print("Reduced number of features:", X_sparse_tsvd.shape[1])
Producción:

Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA