MapReduce se puede usar para trabajar con una sola llamada de método: enviar() en un objeto de trabajo (también puede llamar a waitForCompletion() , que presenta la actividad en caso de que no se haya enviado correctamente, entonces se sienta firme para que termine).
Entendamos los componentes:
- Cliente: Envío del trabajo de MapReduce.
- Administrador de Nodes de Yarn: en un clúster, supervisa e inicia los contenedores de cómputo en las máquinas.
- Administrador de recursos de hilo: maneja la asignación de la coordinación de recursos informáticos en el clúster.
- Maestro de la aplicación MapReduce Facilita las tareas que ejecutan el trabajo de MapReduce.
- Sistema de archivos distribuido: comparte archivos de trabajo con otras entidades.
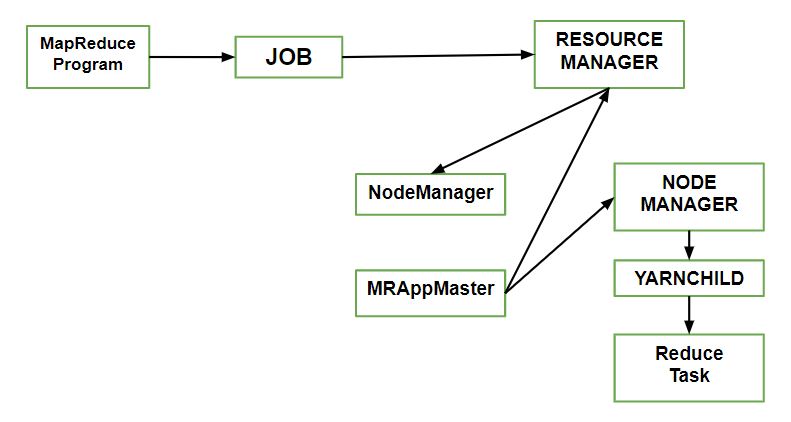
¿Cómo enviar trabajo?
Para crear una instancia interna de JobSubmitter, use la función de envío() que llama además a submitJobInternal() en ella. Habiendo enviado el trabajo,
waitForCompletion() sondea el progreso del trabajo después de enviar el trabajo una vez por segundo. Si los informes han cambiado desde el último informe, informa más sobre el progreso a la consola. Los contadores de trabajos se muestran cuando el trabajo se completa correctamente. De lo contrario, el error (que provocó que el trabajo fallara) se registra en la consola.
Procesos implementados por JobSubmitter para enviar el trabajo:
- El administrador de recursos solicita una nueva ID de aplicación que se utiliza para la ID de trabajo de MapReduce.
- Se comprueba la especificación de salida del trabajo. Por ejemplo, se lanza un error al programa MapReduce o el trabajo no se envía o el directorio de salida ya existe o no se ha especificado.
- Si no se pueden calcular las divisiones, calcula las divisiones de entrada para el trabajo. Esto puede deberse a que el trabajo no se envía y se genera un error en el programa MapReduce.
- Los recursos necesarios para ejecutar el trabajo se copian, incluido el archivo JAR del trabajo y las divisiones de entrada calculadas, en el sistema de archivos compartido en un directorio con el nombre del ID del trabajo y el archivo de configuración.
- Copia JAR de trabajo con un alto factor de replicación, que está controlado por la propiedad mapreduce.client.submit.file.replication . AS hay una cantidad de copias en todo el clúster para que accedan los administradores de Nodes.
- Al llamar a submitApplication() , envía el trabajo al administrador de recursos.
Publicación traducida automáticamente
Artículo escrito por mayank5326 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA