En este artículo, utilizaremos Scrapy para extraer datos, presentarlos en páginas web vinculadas y recopilar los mismos. Extraeremos datos del sitio web ‘https://quotes.toscrape.com/’.
Creación de un proyecto Scrapy
Scrapy viene con una herramienta de línea de comandos eficiente, también llamada ‘herramienta Scrapy’. Los comandos se utilizan para diferentes propósitos y aceptan un conjunto diferente de argumentos y opciones. Para escribir el código Spider, comenzamos creando un proyecto Scrapy, ejecutando el siguiente comando en la terminal:
scrapy startproject gfg_spiderfollowlink
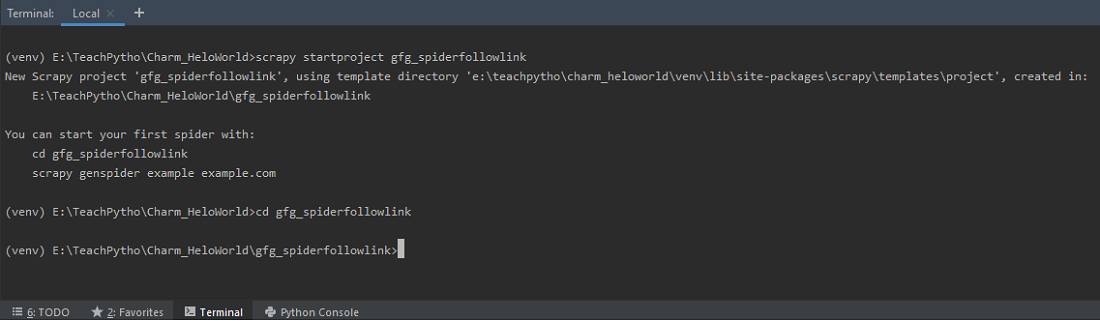
Use el comando ‘startproject’ para crear un Proyecto Scrapy
Esto debería crear una carpeta ‘gfg_spiderfollowlink’ en su directorio actual. Contiene un ‘scrapy.cfg’, que es un archivo de configuración del proyecto. La estructura de carpetas es como se muestra a continuación:

La estructura de carpetas de la carpeta ‘gfg_spiderfollowlink’
La carpeta contiene items.py, middlerwares.py y otros archivos de configuración, junto con la carpeta ‘spiders’.
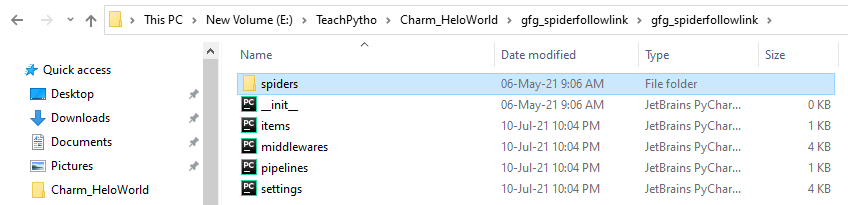
La estructura de carpetas de la carpeta ‘gfg_spiderfollowlink’
Mantenga el contenido de los archivos de configuración tal como están actualmente.
Extraer datos de una página web
El código para web scraping está escrito en el archivo de código spider. Para crear el archivo spider, haremos uso del comando ‘genspider’. Tenga en cuenta que este comando se ejecuta en el mismo nivel donde está presente el archivo scrapy.cfg.
Estamos recopilando todas las citas presentes en ‘http://quotes.toscrape.com/’. Por lo tanto, ejecutaremos el comando como:
scrapy genspider gfg_spilink "quotes.toscrape.com"
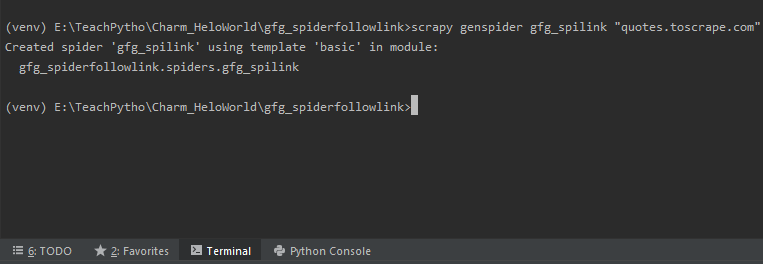
Ejecute el comando ‘genspider’ para crear un archivo Spider
El comando anterior creará un archivo araña, “gfg_spilink.py” en la carpeta ‘arañas’. El código por defecto, para el mismo, es el siguiente:
Python3
# Import the required libraries import scrapy # Spider class name class GfgSpilinkSpider(scrapy.Spider): # Name of the spider name = 'gfg_spilink' # The domain to be scraped allowed_domains = ['quotes.toscrape.com'] # The URLs to be scraped from the domain start_urls = ['http://quotes.toscrape.com/'] # Default callback method def parse(self, response): pass
Extraeremos todos los títulos, autores y etiquetas de las citas del sitio web «quotes.toscrape.com». La página de inicio del sitio web se ve como se muestra a continuación:
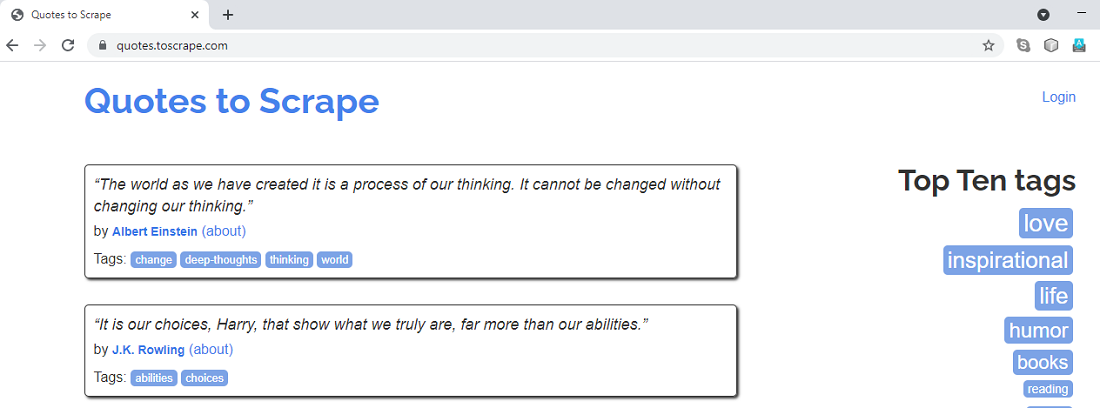
La página de inicio de «quotes.toscrape.com»
Scrapy nos proporciona, con Selectores, para “seleccionar” partes de la página web, deseadas. Los selectores son expresiones CSS o XPath, escritas para extraer datos de documentos HTML. En este tutorial, haremos uso de expresiones XPath para seleccionar los detalles que necesitamos.
Comprendamos los pasos para escribir la sintaxis del selector en el código spider:
- En primer lugar, escribiremos el código en el método parse(). Este es el método de devolución de llamada por defecto, presente en la clase spider, responsable de procesar la respuesta recibida. El código de extracción de datos, utilizando Selectores, se escribirá aquí.
- Para escribir las expresiones XPath, seleccionaremos el elemento en la página web, haremos clic derecho y elegiremos la opción Inspeccionar. Esto nos permitirá ver sus atributos CSS.
- Cuando hacemos clic con el botón derecho en la primera Cotización y elegimos Inspeccionar, podemos ver que tiene el atributo de ‘clase’ de CSS «cita». Del mismo modo, todas las demás citas en la página web tienen el mismo atributo de ‘clase’ de CSS. Se puede ver a continuación:
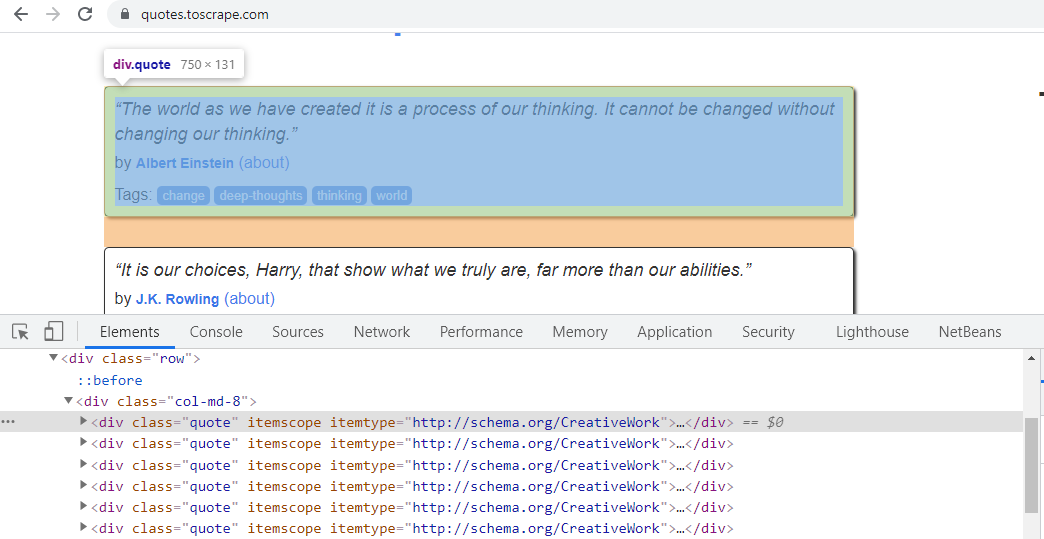
Haga clic derecho en la primera cita y verifique su atributo de «clase» CSS
Por lo tanto, la expresión XPath, por lo mismo, puede escribirse como – comillas = respuesta.xpath(‘//*[@class=”quote”]’). Esta sintaxis recuperará todos los elementos que tengan «comillas» como el atributo ‘clase’ de CSS. Las citas presentes en otras páginas tienen el mismo atributo CSS. Por ejemplo, las citas presentes en la página 3 del sitio web pertenecen al atributo ‘clase’, como se muestra a continuación:
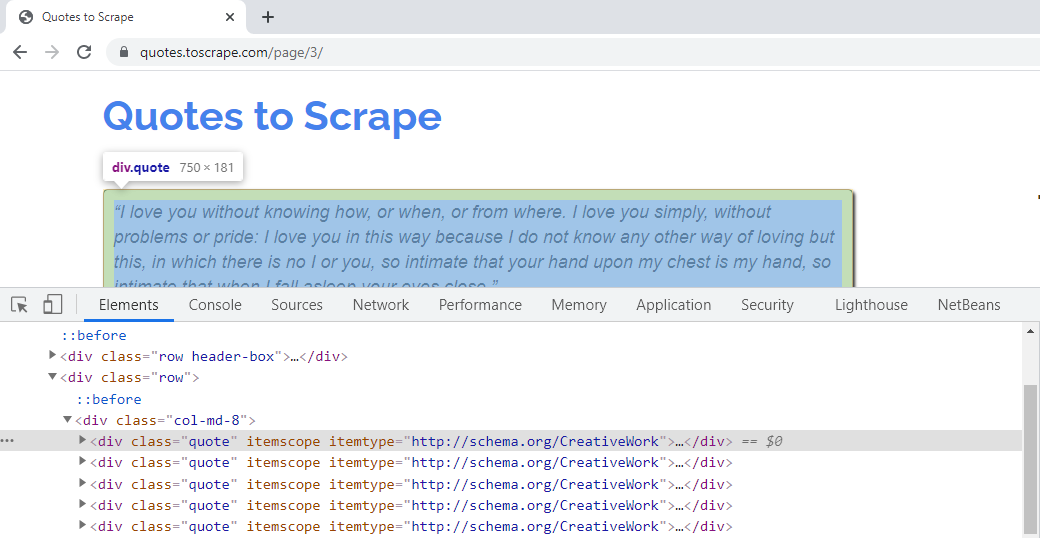
Las cotizaciones en otras páginas del sitio web pertenecen al mismo atributo de clase CSS
Necesitamos obtener el título de la cita, el autor y las etiquetas de todas las citas. Por lo tanto, escribiremos expresiones XPath para extraerlas, en un bucle.
- El atributo de ‘clase’ de CSS, para Título de cotización, es «texto». Por lo tanto, la expresión XPath, por lo mismo, sería – quote.xpath(‘.//*[@class=”text”]/text()’).extract_first(). El método text() extraerá el texto del título de la cita. El método extract_first() dará el primer valor coincidente, con el atributo CSS «texto». El operador punto ‘.’ en el inicio, indica extraer datos, de una comilla simple.
- Los atributos CSS, «clase» y «itemprop», para el elemento autor, es «autor». Podemos usar, cualquiera de estos, en la expresión XPath. La sintaxis sería: quote.xpath(‘.//*[@itemprop=”author”]/text()’).extract(). Esto extraerá el nombre del autor, donde el atributo ‘itemprop’ de CSS es ‘autor’.
- Los atributos CSS, «clase» y «itemprop», para el elemento de etiquetas, son «palabras clave». Podemos usar, cualquiera de estos, en la expresión XPath. Dado que hay muchas etiquetas, para cualquier cita, recorrerlas será tedioso. Por lo tanto, extraeremos el atributo CSS «contenido» de cada cita. La expresión XPath para el mismo es – quote.xpath(‘.//*[@itemprop=”keywords”]/@content’).extract(). Esto extraerá, todos los valores de las etiquetas, del atributo «contenido», para las comillas.
- Usamos la sintaxis de ‘rendimiento’ para obtener los datos. Podemos recopilar y transferir datos a CSV, JSON y otros formatos de archivo mediante el uso de ‘rendimiento’.
Si observamos el código hasta aquí, rastreará y extraerá datos para una página web. El código es el siguiente –
Python3
# Import the required libraries
import scrapy
# Spider class name
class GfgSpilinkSpider(scrapy.Spider):
# Name of the spider
name = 'gfg_spilink'
# The domain to be scraped
allowed_domains = ['quotes.toscrape.com']
# The URLs to be scraped from the domain
start_urls = ['http://quotes.toscrape.com/']
# Default callback method
def parse(self, response):
# All quotes have CSS 'class 'attribute as 'quote'
quotes = response.xpath('//*[@class="quote"]')
# Loop through the quotes
# selectors to fetch data for every quote
for quote in quotes:
# XPath expression to fetch
# text of the Quote title
# note the 'dot' operator since
# we are extracting from single 'quote' element
title = quote.xpath(
'.//*[@class="text"]/text()').extract_first()
# XPath expression to fetch author of the Quote
authors = quote.xpath('.//*[@itemprop="author"]/text()').extract()
# XPath expression to fetch tags of the Quote
tags = quote.xpath('.//*[@itemprop="keywords"]/@content').extract()
# Yield the data desired
yield {"Quote Text ": title, "Authors ": authors, "Tags ": tags}
Siguiendo enlaces
Hasta ahora, hemos visto el código, para extraer datos, de una sola página web. Nuestro objetivo final es obtener los datos relacionados con la cotización de todas las páginas web. Para hacerlo, necesitamos hacer que nuestra araña siga los enlaces, para que pueda navegar a las páginas siguientes. Los hipervínculos generalmente se definen escribiendo etiquetas <a>. El atributo “href”, de las etiquetas <a>, indica el destino del enlace. Necesitamos extraer, el atributo «href», para recorrer, de una página a otra. Estudiemos, cómo implementar lo mismo –
- Para pasar a la página siguiente, verifique el atributo CSS del hipervínculo «Siguiente».
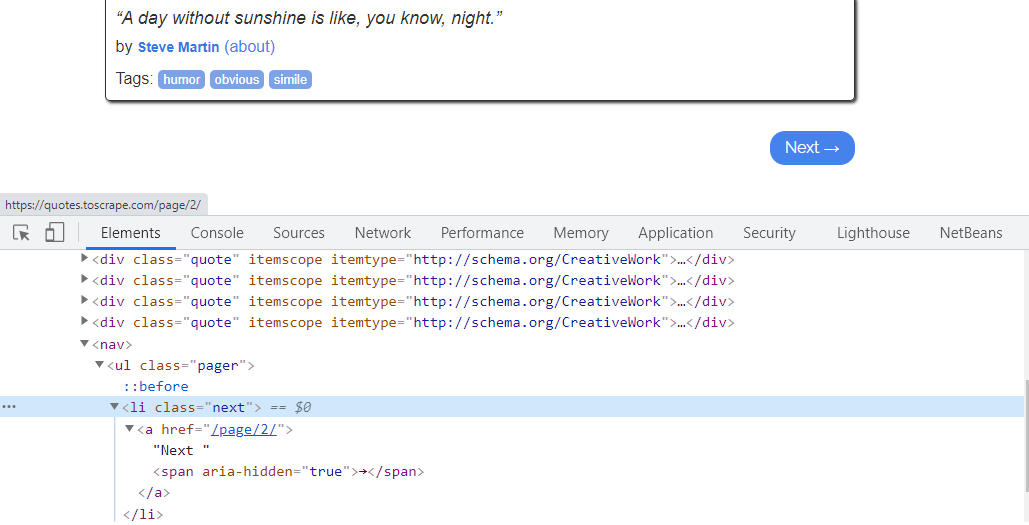
El atributo de clase CSS del hipervínculo «Siguiente ->» es «siguiente»
Necesitamos extraer, el atributo “href”, de la etiqueta <a> de HTML. El atributo «href» indica la URL de la página a la que se dirige el enlace. Por lo tanto, necesitamos obtener lo mismo y unirnos a nuestra ruta actual para que la araña navegue a otras páginas sin problemas. Para la primera página, el valor «href» de la etiqueta <a> es «/página/2», lo que significa que enlaza con la segunda página.
Si hace clic y observa el enlace «Siguiente» de la segunda página web, tiene un atributo CSS como «siguiente». Para esta página, el valor «href» de la etiqueta <a> es «/página/3», lo que significa que enlaza con la tercera página, y así sucesivamente.
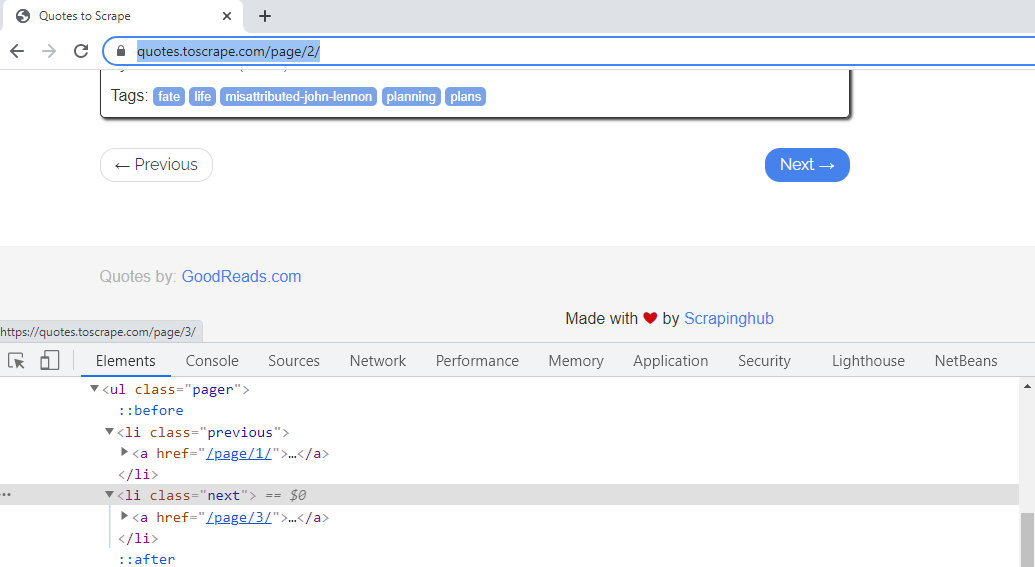
El atributo «href» del vínculo «Siguiente» en la página 2, vincula a la tercera página web
Por lo tanto, la expresión XPath, para el enlace de la página siguiente, se puede recuperar escribiendo expresión como: URL_página_ulterior = respuesta.xpath(‘//*[@class=”siguiente”]/a/@href’).extract_first(). Esto nos dará el valor de “@href”, que es “/página/2” para la primera página.
La URL anterior no es suficiente para hacer que la araña se arrastre a la página siguiente. Necesitamos formar una URL absoluta fusionando la URL del objeto de respuesta con la URL relativa anterior. Para ello, utilizaremos el método urljoin().
La URL del objeto de respuesta es «https://quotes.toscrape.com/». Para viajar, a la página siguiente, necesitamos unirnos a ella, con la URL relativa “/página/2”. La sintaxis, por lo mismo, es: complete_url_next_page = response.urljoin(further_page_url). Esta sintaxis nos dará la ruta completa como «https://quotes.toscrape.com/page/2/». De igual forma, para la segunda página, se modificará, según el número de la página web, como “https://quotes.toscrape.com/page/3/” y así sucesivamente.
El método parse ahora hará una nueva solicitud, utilizando esta URL ‘complete_url_next_page’.
Por lo tanto, nuestro objeto de Solicitud final, para navegar a la segunda página y rastrearla, será: yield scrapy.Request(complete_url_next_page). El código completo de la araña será el siguiente:
Python3
# Import the required libraries
import scrapy
# Spider class name
class GfgSpilinkSpider(scrapy.Spider):
# Name of the spider
name = 'gfg_spilink'
# The domain to be scraped
allowed_domains = ['quotes.toscrape.com']
# The URLs to be scraped from the domain
start_urls = ['http://quotes.toscrape.com/']
# Default callback method
def parse(self, response):
quotes = response.xpath('//*[@class="quote"]')
for quote in quotes:
# XPath expression to fetch
# text of the Quote title
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
# XPath expression to fetch
# author of the Quote
authors = quote.xpath('.//*[@itemprop="author"]/text()').extract()
tags = quote.xpath('.//*[@itemprop="keywords"]/@content').extract()
yield {"Quote Text ": title, "Authors ": authors, "Tags ": tags}
# Check CSS attribute of the "Next"
# hyperlink and extract its "href" value
further_page_url = response.xpath(
'//*[@class="next"]/a/@href').extract_first()
# Append the "href" value, to the current page,
# to form a complete URL, of next page
complete_url_next_page = response.urljoin(further_page_url)
# Make the spider crawl, to the next page,
# and extract the same data
# A new Request with the URL is made
yield scrapy.Request(complete_url_next_page)
Ejecute Spider, en la terminal, usando el comando ‘rastrear’. La sintaxis es la siguiente: scrapy crawl spider_name. Por lo tanto, podemos ejecutar nuestra araña como: scrapy crawl gfg_spilink. Rastreará todo el sitio web siguiendo los enlaces y generará los datos de Cotizaciones. La salida es como se ve a continuación:
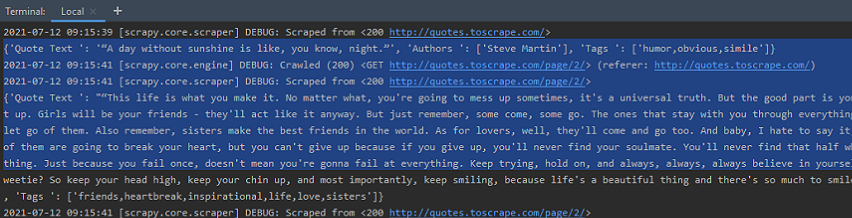
The Spider genera citas de la página web 1, 2 y el resto de ellas
Si revisamos las estadísticas de salida de Spider, podemos ver que Spider ha rastreado, más de diez páginas web, siguiendo los enlaces. Además, el número de Cotizaciones es cercano a 100.
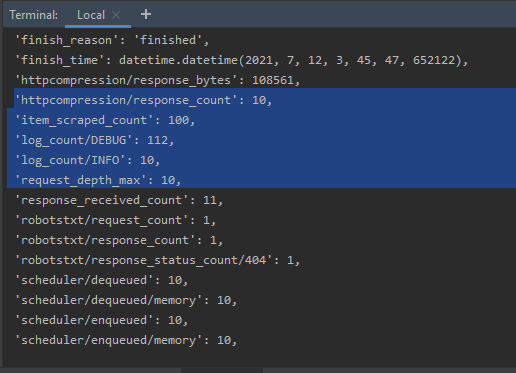
Las estadísticas de Spider, en el terminal, indicando el número de páginas rastreadas
Podemos recopilar datos, en cualquier formato de archivo, para su almacenamiento o análisis. Para recopilar lo mismo, en un archivo JSON, podemos mencionar el nombre del archivo, en el ‘rastreo’, sintaxis de la siguiente manera:
scrapy crawl gfg_spilink -o spiderlinks.json
El comando anterior recopilará todos los datos de cotizaciones raspados, en un archivo JSON «spiderlinks.json». El contenido del archivo es como se ve a continuación:
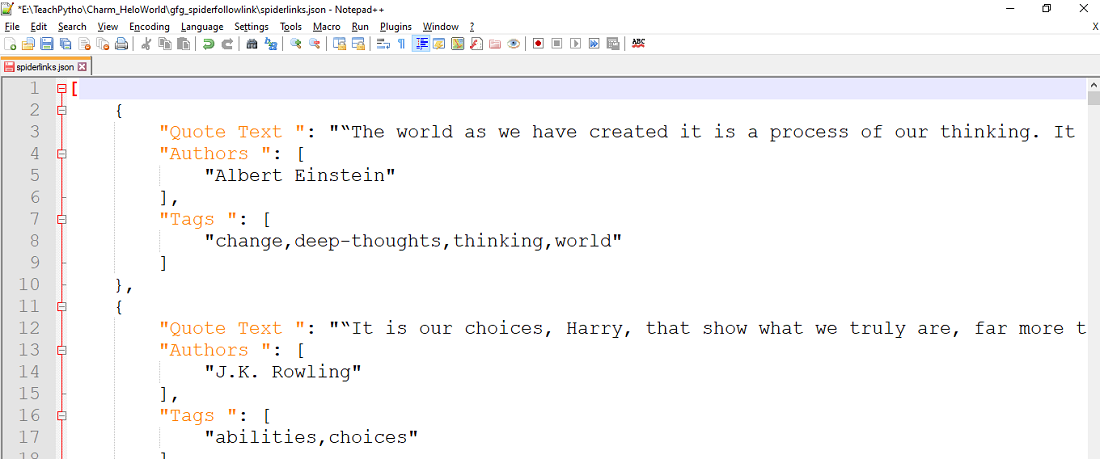
Todas las cotizaciones se recopilan en un archivo JSON
Publicación traducida automáticamente
Artículo escrito por phadnispradnya y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA