Analicemos cómo seleccionar filas aleatoriamente de Pandas DataFrame . Una selección aleatoria de filas de un DataFrame se puede lograr de diferentes maneras.
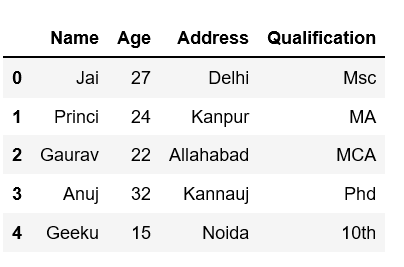
Cree un marco de datos simple con un diccionario de listas.
Python3
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# select all columns
df
Método #1: Usar el método sample()
El método de muestra devuelve una muestra aleatoria de elementos de un eje de objeto y este objeto del mismo tipo que la persona que llama.
Ejemplo 1:
Python3
# Selects one row randomly using sample()
# without give any parameters.
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Select one row randomly using sample()
# without give any parameters
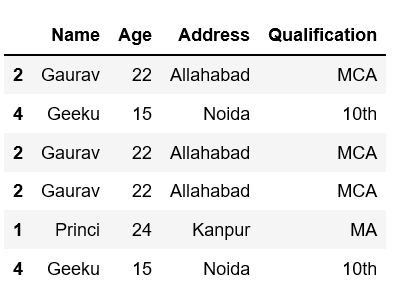
df.sample()
Producción:

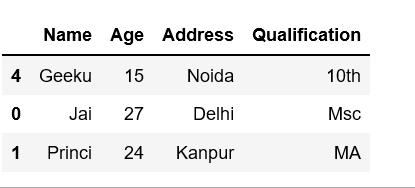
Ejemplo 2: Uso del parámetro n , que selecciona n números de filas al azar.
Seleccione n números de filas al azar usando muestra (n) o muestra (n = n). Cada vez que ejecuta esto, obtiene n filas diferentes.
Python3
# To get 3 random rows # each time it gives 3 different rows # df.sample(3) or df.sample(n = 3)
Producción:
Ejemplo 3: Uso del parámetro frac.
Uno puede hacer fracciones de elementos de eje y obtener filas. Por ejemplo, si frac= .5, el método de muestra devuelve el 50 % de las filas.
Python3
# Fraction of rows # here you get .50 % of the rows df.sample(frac = 0.5)
Producción:

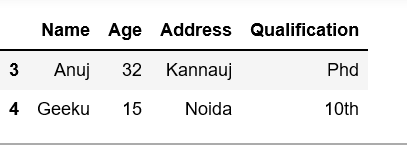
Ejemplo 4:
primero selecciona el 70 % de las filas de todo el marco de datos df y coloca otro marco de datos df1 , luego seleccionamos el 50 % de frac de df1 .
Python3
# fraction of rows # here you get 70 % row from the df # make put into another dataframe df1 df1 = df.sample(frac =.7) # Now select 50 % rows from df1 df1.sample(frac =.50)
Producción:
Ejemplo 5: seleccione algunas filas al azar con replace = false
El parámetro replace da permiso para seleccionar una fila muchas veces (como). El valor predeterminado del parámetro de reemplazo del método sample() es Falso, por lo que nunca selecciona más del número total de filas.
Python3
# Dataframe df has only 4 rows # if we try to select more than 4 row then will come error # Cannot take a larger sample than population when 'replace = False' df1.sample(n = 3, replace = False)
Producción:
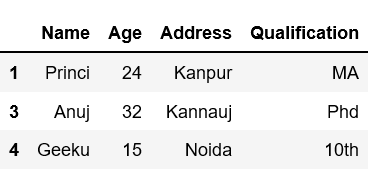
Ejemplo 6: seleccione más de n filas donde n es el número total de filas con la ayuda de replace.
Python3
# Select more than rows with using replace # default it is False df1.sample(n = 6, replace = True)
Producción:
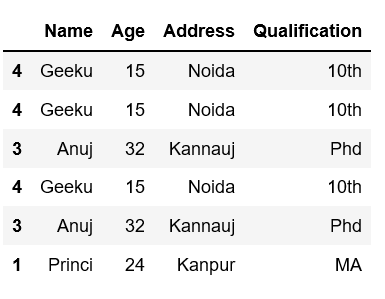
Ejemplo 7: Uso de pesos
Python3
# Weights will be re-normalized automatically test_weights = [0.2, 0.2, 0.2, 0.4] df1.sample(n = 3, weights = test_weights)
Producción:
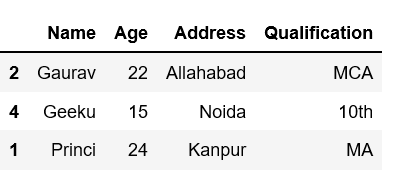
Ejemplo 8: Uso del eje
El eje acepta número o nombre. El método sample() también permite a los usuarios muestrear columnas en lugar de filas usando el argumento del eje.
Python3
# Accepts axis number or name. # sample also allows users to sample columns # instead of rows using the axis argument. df1.sample(axis = 0)
Producción:

Ejemplo 9: Uso de random_state
Con un DataFrame dado, la muestra siempre obtendrá las mismas filas. Si random_state es None o np.random, se devuelve un objeto RandomState inicializado aleatoriamente.
Python3
# With a given seed, the sample will always draw the same rows. # If random_state is None or np.random, # then a randomly-initialized # RandomState object is returned. df1.sample(n = 2, random_state = 2)
Producción:

Método n.º 2: con NumPy
Numpy, elija cuántos índices se incluyen para la selección aleatoria y podemos permitir el reemplazo.
Python3
# Import pandas & Numpy package
import numpy as np
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Choose how many index include for random selection
chosen_idx = np.random.choice(4, replace = True, size = 6)
df2 = df.iloc[chosen_idx]
df2
Producción: