Requisito previo: Pandas.Dataframes en Python
En este artículo, cubriremos cómo seleccionamos filas de un DataFrame en función de los valores de columna en Python .
Las filas de un marco de datos se pueden seleccionar según las condiciones, ya que usamos las consultas SQL. Los diversos métodos para lograr esto se explican en este artículo con ejemplos.
Importación de conjuntos de datos para demostración
Para explicar el método, se ha creado un conjunto de datos que contiene datos de puntos anotados por 10 personas en varios juegos. El conjunto de datos se carga en el marco de datos y se visualiza primero. Diez personas con una identificación de jugador única ( Pid ) han jugado diferentes juegos con una identificación de juego diferente ( game_id ) y los puntos obtenidos en cada juego se agregan como una entrada a la tabla. Algunos de los puntos del jugador no se registran y, por lo tanto, el valor de NaN aparece en la tabla.
Nota: Para usar el archivo CSV, haga clic aquí .
Python3
import pandas as pd df = pd.read_csv(r"__your file path__\example2.csv") print(df)
Producción:
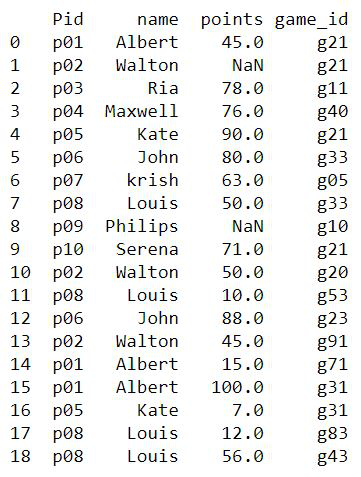
conjunto de datos ejemplo2.csv
Seleccionaremos filas de Dataframe según el valor de la columna usando:
- Método de indexación booleana
- Método de indexación posicional
- Usando el método isin()
- Usando el método Numpy.where()
- Comparación con otros métodos
Método 1: método de indexación booleana
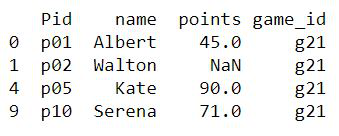
En este método, para una condición de columna específica, cada fila se comprueba si es verdadero/falso. Las filas que produzcan True se considerarán para la salida. Esto se puede lograr de varias maneras. La consulta utilizada es Seleccionar filas donde la columna Pid=’p01′
Ejemplo 1: seleccionar filas de un marco de datos de Pandas en función de los valores de una columna
En este ejemplo, estamos tratando de seleccionar aquellas filas que tienen el valor p01 en su columna usando el operador de igualdad.
Python3
# Choose entries with id p01 df_new = df[df['Pid'] == 'p01'] print(df_new)
Producción

Ejemplo 2: Especificación de la variable de condición ‘máscara’
Aquí, veremos que Pandas selecciona filas por condición, las filas seleccionadas se asignan a un nuevo Dataframe con el índice de filas del antiguo Dataframe como un índice en el nuevo y las columnas permanecen iguales.
Python3
# condition mask mask = df['Pid'] == 'p01' # new dataframe with selected rows df_new = pd.DataFrame(df[mask]) print(df_new)
Producción

Ejemplo 3: Combinación de la máscara y la propiedad dataframes.values
La consulta aquí es Seleccionar las filas con game_id ‘g21’ .
Python3
# condition with df.values property mask = df['game_id'].values == 'g21' # new dataframe df_new = df[mask] print(df_new)
Producción
Método 2: método de indexación posicional
Los métodos loc() e iloc() se pueden usar para dividir los marcos de datos en Python. Entre las diferencias entre loc() e iloc() , lo importante a tener en cuenta es que iloc() solo toma índices enteros, mientras que loc() también puede tomar índices booleanos.
Ejemplo 1: Pandas selecciona filas por el método loc() basado en valores de columna
La máscara proporciona el valor booleano como un índice para cada fila y las filas que se evalúen como verdaderas aparecerán en el resultado. Aquí, la consulta es seleccionar las filas donde game_id es g21 .
Python3
# for boolean indexing mask = df['game_id'].values == 'g21' # using loc() method df_new = df.loc[mask] print(df_new)
Producción
Ejemplo 2: los pandas seleccionan filas mediante el método iloc() en función de los valores de las columnas
La consulta es la misma que la anterior. El iloc() solo toma números enteros como argumento y, por lo tanto, la array de máscaras se pasa como un parámetro a la función flatnonzero() de Numpy que devuelve el índice en la lista donde el valor no es cero (falso)
Python3
# condition mask
mask = df['game_id'].values == 'g21'
print("Mask array :", mask)
# getting non zero indices
pos = np.flatnonzero(mask)
print("\nRows selected :", pos)
# selecting rows
df.iloc[pos]
Producción

Método 3: Usar el método dataframe.query()
El método query() toma la expresión que devuelve un valor booleano, procesa todas las filas en el marco de datos y devuelve el marco de datos resultante con las filas seleccionadas.
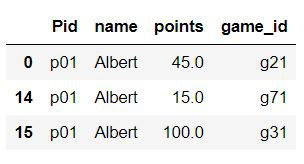
Ejemplo 1: Pandas selecciona filas mediante el método Dataframe.query() en función de los valores de columna
Seleccione filas donde el nombre = «Albert»
Python3
df.query('name=="Albert"')
Producción
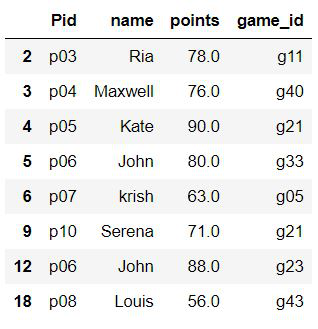
Ejemplo 2: seleccionar filas en función de las condiciones de la columna iple
Este ejemplo es para demostrar que los operadores lógicos como AND/OR se pueden usar para verificar múltiples condiciones. estamos tratando de seleccionar filas donde los puntos> 50 y el jugador no es Albert.
Python3
df.query('points>50 & name!="Albert"')
Producción
Método 3: Usar el método isin()
Este método de Dataframe toma un iterable o una serie u otro Dataframe como parámetro y verifica si existen elementos del Dataframe en él. Las filas que se evalúan como verdaderas se consideran para la resultante.
Ejemplo 1: Pandas selecciona filas por el método isin() basado en valores de columna
Seleccione filas cuyo valor de columna esté en una array iterable
Seleccione las filas donde los jugadores son Albert, Louis y John.
Python3
# Players to be selected li = ['Albert', 'Louis', 'John'] df[df.name.isin(li)]
Producción
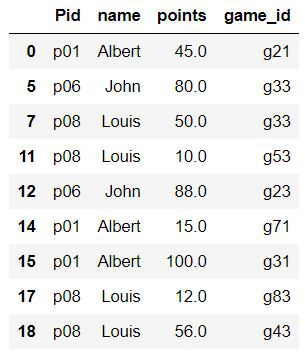
Ejemplo 2: Seleccionar filas donde la columna no es igual a un valor
El símbolo de mosaico (~) proporciona la negación de la expresión evaluada. Aquí, estamos seleccionando filas donde los puntos son> 50 y los jugadores no son Albert, Louis y John.
Python3
# values to be present in selected rows li = ['Albert', 'Louis', 'John'] # selecting rows from dataframe df[(df.points > 50) & (~df.name.isin(li))]
Producción
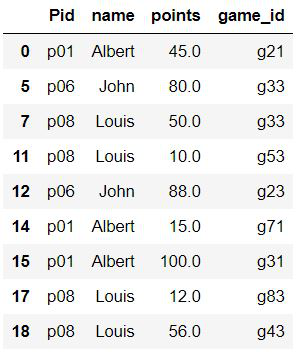
Método 4: Usar el método Numpy.where()
La función where() de Numpy se puede combinar con la función isin() de pandas para producir un resultado más rápido. Se ha demostrado que numpy.where () produce resultados más rápido que los métodos normales utilizados anteriormente.
Ejemplo: los pandas seleccionan filas con el método np.where() según los valores de las columnas
Python3
import numpy as np df_new = df.iloc[np.where(df.name.isin(li))]
Producción:
Método 5: Comparación con otros métodos
Ejemplo 1
En este ejemplo, estamos usando una combinación de métodos NumPy y pandas.
Python3
# to calculate timing import numpy as np % % timeit # using mixture of numpy and pandas method df_new = df.iloc[np.where(df.name.isin(li))]
Producción:
756 µs ± 132 µs por bucle (media ± desviación estándar de 7 ejecuciones, 1000 bucles cada una)
Ejemplo 2
En este ejemplo, estamos usando solo el método Pandas
Python3
# to calculate time %%timeit li=['Albert','Louis','John'] # Pandas method only df[(df.points>50)&(~df.name.isin(li))]
Producción
1,7 ms ± 307 µs por bucle (media ± desviación estándar de 7 ejecuciones, 1000 bucles cada una)
Publicación traducida automáticamente
Artículo escrito por erakshaya485 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA