requisitos previos:
Con el módulo Pandas, es posible seleccionar filas de un marco de datos utilizando índices de otro marco de datos. Este artículo trata eso en detalle. Se recomienda implementar todos los códigos en jupyter notebook para una fácil implementación.
Acercarse:
- Módulo de importación
- Crear el primer marco de datos. En el ejemplo dado a continuación , choice() , randint() y random(), todos pertenecientes al módulo aleatorio, se utilizan para generar un marco de datos.
1) Choice() – Choice() es una función incorporada en el lenguaje de programación Python que devuelve un elemento aleatorio de una lista, tupla o string.
Sintaxis: random.choice(secuencia)
Parámetros: la secuencia es un parámetro obligatorio que puede ser una lista, una tupla o una string.
Devoluciones: la opción() devuelve un elemento aleatorio.
2) randint()- Esta función se usa para generar números aleatorios
Sintaxis: randint (inicio, final)
Parámetros:
(inicio, fin) : ambos deben ser valores de tipo entero.
Devoluciones :
Un número entero aleatorio en el rango [inicio, final] que incluye los puntos finales.
3) random()- Se utiliza para generar números flotantes entre 0 y 1.
- Cree otro marco de datos usando la función random() y seleccionando aleatoriamente las filas del primer conjunto de datos.
- Ahora usaremos la función dataframe.loc[] para seleccionar los valores de fila del primer marco de datos usando los índices del segundo marco de datos. El atributo PandasDataFrame.loc[] accede a un grupo de filas y columnas por etiqueta(s) o una array booleana en el DataFrame dado.
Sintaxis: DataFrame.loc
Parámetro: Ninguno
Devoluciones: escalar, serie, marco de datos
- Mostrar filas seleccionadas
La implementación utilizando el concepto anterior se da a continuación:
Programa:
Python3
# Importing Required Libraries
import pandas as pd
import random
# Creating data for main dataframe
col1 = [random.randint(1, 9) for i in range(15)]
col2 = [random.random() for i in range(15)]
col3 = [random.choice(['Geeks', 'of', 'Computer', 'Science'])
for i in range(15)]
col4 = [random.randint(1, 9) for i in range(15)]
col5 = [random.randint(1, 9) for i in range(15)]
# Defining Column name for main dataframe
data_generated = {
'value1': col1,
'value2': col2,
'value3': col3,
'value4': col4,
'value5': col5
}
# Creating the dataframe using DataFrame() function
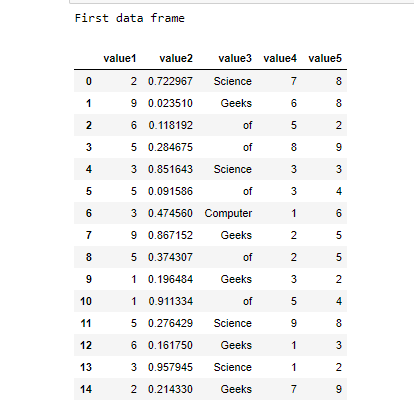
print("First data frame")
dataframe = pd.DataFrame(data_generated)
display(dataframe)
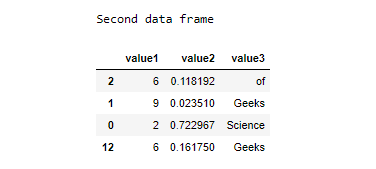
# Creating a second dataframe that will be the subset of main dataframe
print("Second data frame")
dataframe_second = dataframe[['value1', 'value2', 'value3']].sample(n=4)
display(dataframe_second)
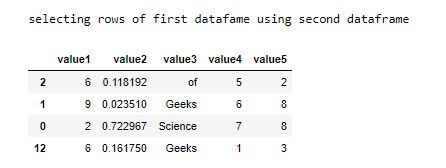
# Rows of a dataframe using the indices of another dataframe
print("selecting rows of first dataframe using second dataframe")
display(dataframe.loc[dataframe_second.index])
Producción: