En general, cuando trabajábamos en marcos de datos más grandes, solo nos interesaría una pequeña parte de ellos para analizarlos en lugar de considerar todas las filas y columnas presentes en el marco de datos.
Creación de un conjunto de datos de muestra
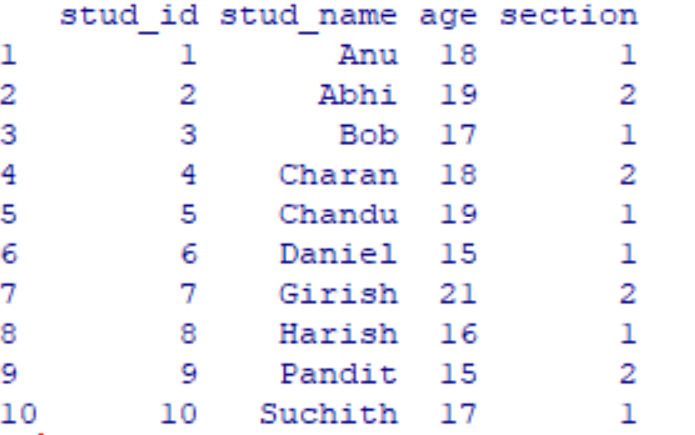
Vamos a crear un marco de datos de muestra de Estudiantes de la siguiente manera
R
student_details < -data.frame(
stud_id=c(1: 10),
stud_name=c("Anu", "Abhi", "Bob",
"Charan", "Chandu",
"Daniel", "Girish", "Harish",
"Pandit", "Suchith"),
age=c(18, 19, 17, 18, 19, 15, 21,
16, 15, 17),
section=c(1, 2, 1, 2, 1, 1, 2, 1,
2, 1)
)
print(student_details)
Producción:
Método 1. Uso de corte de índice
Este método se usa cuando el analista conocía los números de fila/columna para extraer del conjunto de datos principal y crear un subconjunto a partir de ellos para facilitar el análisis. Los números asignados a esas filas o columnas se denominan Índice(s).
Sintaxis: marco de datos [filas, columnas]
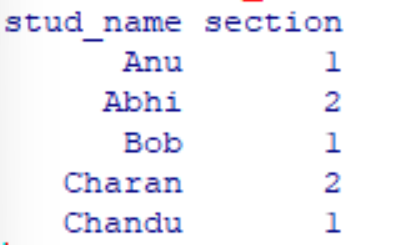
Ejemplo: Para hacer un subconjunto del marco de datos de las primeras cinco filas y la segunda y cuarta columna
R
subset_1<-student_details[c(1:5),c(2,4)] print(subset_1)
Producción:
Método 2. Usar la función subconjunto()
Cuando el analista conoce los nombres de las filas y las columnas, se utiliza el método subset(). Simplemente, esta función se usa cuando queremos derivar un subconjunto de un marco de datos basado en implantar algunas condiciones en las filas y columnas del marco de datos. Este método es más eficiente y fácil de usar que el método Index.
Sintaxis: subconjunto (marco de datos, filas_condición, columna_condición)
Ejemplo: Extraer nombres de alumnos pertenecientes a la sección1
R
subset_2=subset(student_details,section==1,stud_name) print(subset_2)
Producción:

Método 3. Uso de las funciones del paquete dplyr
En el filtro() – esta función se usa cuando queremos derivar un subconjunto del marco de datos basado en una condición específica.
Este método se usa cuando los analistas quieren derivar un subconjunto basado en alguna condición en filas o columnas o ambos usando nombres de fila y columna. Entre los tres métodos mencionados anteriormente, este método es más eficiente que los otros dos.
Sintaxis: filtro (marco de datos, condición)
Nota: asegúrese de haber instalado el paquete dplyr en el entorno del espacio de trabajo mediante comandos
install.packages("dplyr") -To install
library(dplyr) - To load
Ejemplo: extraigamos filas que contengan nombres de estudiantes que comiencen con la letra C.
R
library(dplyr) subset_3 < -filter(student_details, startsWith(stud_name, 'C')) print(subset_3)
Producción:

Publicación traducida automáticamente
Artículo escrito por sri06harsha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA