En el lenguaje de programación R, para seleccionar la fila con el valor máximo en cada grupo de un marco de datos, podemos usar varios enfoques, como se explica a continuación.
Considere el siguiente conjunto de datos con múltiples observaciones en la subcolumna. Este conjunto de datos contiene tres columnas como sr_no, sub y marcas.
Creación de conjunto de datos:
Aquí estamos creando un marco de datos para demostración.
Bloque de código
Producción:
roll sub marks 1 1 A 2 2 2 A 3 3 3 B 5 4 4 B 2 5 5 B 5 6 6 C 8 7 7 C 17 8 8 A 3 9 9 C 5 10 10 C 5
Aquí, roll y las marcas son valores enteros y sub es el valor categórico (char) tienen categoría A, B, C. En este conjunto de datos, A, B, C representan diferentes temas y las marcas son marcas obtenidas en el sub correspondiente.
Como podemos ver el sujeto A, B, C tiene el valor máximo (puntos) de 3,5,17 respectivamente en el grupo. Podemos seleccionar la fila máxima en el grupo usando los siguientes dos enfoques.
Métodos 1: Usando la base R.
Paso 1: Cargue el conjunto de datos en una variable (grupo).
R
# Creating a dataset.
no <- c( 1 : 10)
subject <- c('A', 'A', 'B', 'B', 'B',
'C', 'C', 'A', 'C', 'C')
mark <- c(2, 3, 5, 2, 5, 8, 17, 3, 5, 5)
group <- data.frame(roll = no, sub = subject,
marks = mark )
group
Producción:
roll sub marks 1 1 A 2 2 2 A 3 3 3 B 5 4 4 B 2 5 5 B 5 6 6 C 8 7 7 C 17 8 8 A 3 9 9 C 5 10 10 C 5
Paso 2: Ordenó las marcas en orden descendente para cada grupo (A, B, C).
R
# Creating a dataset.
no <- c( 1 : 10)
subject <- c('A', 'A', 'B', 'B', 'B',
'C', 'C', 'A', 'C', 'C')
mark <- c(2, 3, 5, 2, 5, 8, 17, 3, 5, 5)
group <- data.frame(roll = no, sub = subject,
marks = mark )
# sorting the sub and marks.
sorted_group <- group[order(group$sub, -group$marks),]
sorted_group
Producción:
roll sub marks 2 2 A 3 8 8 A 3 1 1 A 2 3 3 B 5 5 5 B 5 4 4 B 2 7 7 C 17 6 6 C 8 9 9 C 5 10 10 C 5
Como nuestro sub está ahora en orden ascendente y estamos listos para seleccionar la fila con el valor máximo en cada grupo, aquí los grupos son A, B, C.
Paso 3: elimine las filas duplicadas de la columna de asunto ordenado.
R
# Creating a dataset.
no <- c( 1 : 10)
subject <- c('A', 'A', 'B', 'B', 'B',
'C', 'C', 'A', 'C', 'C')
mark <- c(2, 3, 5, 2, 5, 8, 17, 3, 5, 5)
group <- data.frame(roll = no, sub = subject,
marks = mark )
# sorting the sub and marks.
sorted_group <- group[order(group$sub, -group$marks),]
# removing duplicates from the sorted sub column
ans <- sorted_group[!duplicated(sorted_group$sub),]
ans
Producción:
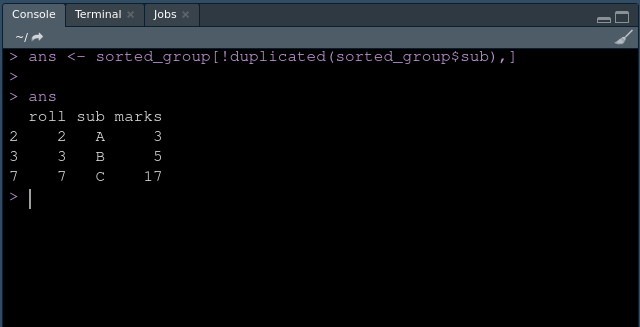
Estas son la fila seleccionada con el valor máximo en cada grupo.
Métodos 2: Uso del paquete dplyr
dplyr es un paquete n R que se usa más comúnmente para manipular el marco de datos. dplyr proporciona varios verbos (funciones) para la manipulación de datos, como filtrar, organizar, seleccionar, renombrar, mutar, etc.
Para instalar el paquete dplyr tenemos que ejecutar el siguiente comando en la consola R.
install.packages("dplyr")
Paso 1: Cargue el conjunto de datos y la biblioteca.
R
# Creating a dataset.
no <- c( 1 : 10)
subject <- c('A', 'A', 'B', 'B', 'B',
'C', 'C', 'A', 'C', 'C')
mark <- c(2, 3, 5, 2, 5, 8, 17, 3, 5, 5)
group <- data.frame(roll = no, sub = subject,
marks = mark )
# loading library
library("dplyr")
Paso 2: ahora agrupe el submarco de datos usando group_ by verb (función) y seleccione la fila que tiene marcas máximas usando which.max() .
R
# Creating a dataset.
no <- c( 1 : 10)
subject <- c('A', 'A', 'B', 'B', 'B',
'C', 'C', 'A', 'C', 'C')
mark <- c(2, 3, 5, 2, 5,
8, 17, 3, 5, 5)
group <- data.frame(roll = no, sub = subject,
marks = mark )
# loading library
library("dplyr")
group %>% group_by(sub) %>% slice(which.max(marks))
Producción:
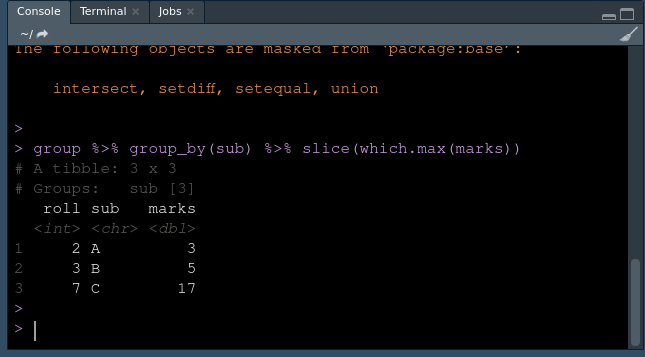
Como podemos ver, estas son la fila seleccionada con el valor máximo en cada grupo.
Publicación traducida automáticamente
Artículo escrito por amnindersingh1414 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA