En este artículo, vamos a ver cómo solucionarlo: solo se pueden comparar objetos de series con etiquetas idénticas en Python.
Motivo del error
Solo se pueden comparar objetos de series con etiquetas idénticas: se trata de un error de valor , que se produjo cuando comparamos 2 marcos de datos diferentes (estructura de datos 2-D de Pandas). Si comparamos marcos de datos que tienen etiquetas o índices diferentes, se puede generar este error.
Cómo reproducir el error
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs': [150, 170, 160],
'Weight in KGs': [70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs': [150, 170, 160],
'Weight in KGs': [70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1 == hostelCandidates2
Producción:
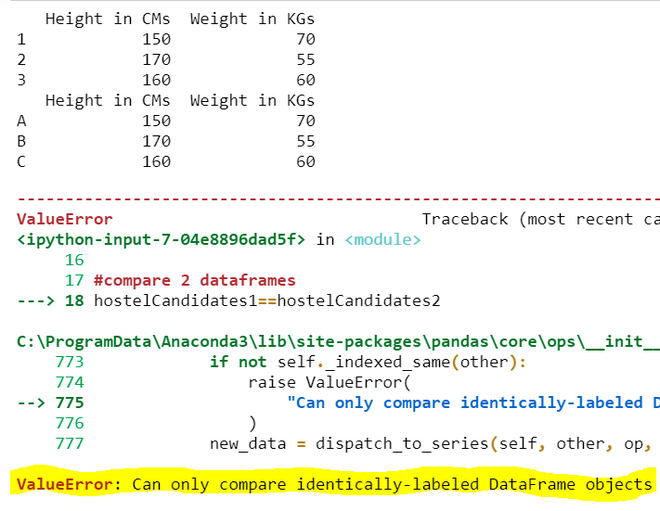
Aunque los datos en los 2 DataFrames son los mismos, los índices de estos son diferentes. Entonces, para comparar los datos de 2 DataFrames si son iguales o no, debemos seguir los siguientes enfoques/soluciones
Método 1: Con consideración de índices
Aquí comparamos datos junto con etiquetas de índice entre DataFrames para especificar si son iguales o no. Entonces, en lugar de ‘==’, use el método equals mientras realiza la comparación.
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.equals(hostelCandidates2)
Producción:
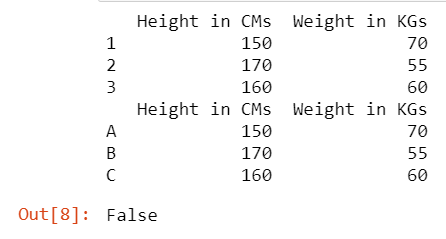
Como los datos son los mismos pero las etiquetas de índice de estos 2 marcos de datos son diferentes, devuelve falso en lugar de un error.
Método 2: Sin consideración de índices
Para eliminar índices de DataFrame, use el método reset_index. Al eliminar los índices, se facilita la tarea de que los intérpretes simplemente verifiquen los datos independientemente de los valores del índice.
Sintaxis: dataframeName.reset_index(drop=True)
Hay 2 formas de comparar datos:
- Marco de datos completo
- Fila por fila
Ejemplo 1: Comparación de toda la trama de datos
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(drop=True).equals(
hostelCandidates2.reset_index(drop=True))
Producción:
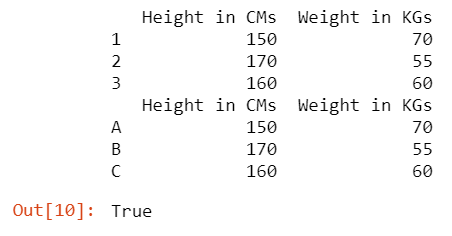
Aquí los datos son los mismos y, aunque los índices son diferentes, estamos comparando los DataFrames eliminando las etiquetas de índice para que devuelva verdadero.
Ejemplo 2: Comparación fila por fila
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(
drop=True) == hostelCandidates2.reset_index(drop=True)
Producción:
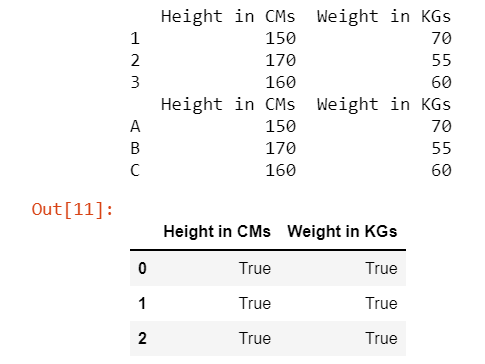
Este enfoque nos ayuda a identificar dónde hay diferencias entre 2 DataFrames y no comparar sus etiquetas de índice, ya que sus etiquetas de índice se eliminan durante la comparación.
Publicación traducida automáticamente
Artículo escrito por akhilvasabhaktula03 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA