Errorbar es el gráfico trazado que se refiere a los errores contenidos en el marco de datos, que muestra la confianza y precisión en un conjunto de medidas o valores calculados. Las barras de error ayudan a mostrar las partes faltantes reales y exactas, así como a mostrar visualmente los errores en diferentes áreas del marco de datos. Las barras de error son el comportamiento descriptivo que contiene información sobre las variaciones en los datos, así como consejos para realizar los cambios adecuados para generar datos más perspicaces e impactantes para los usuarios.
Aquí discutimos cómo trazamos la barra de error con la media y la desviación estándar después de agrupar el marco de datos con ciertas condiciones aplicadas de modo que los errores se vuelvan más veraces para que sea necesario obtener los mejores resultados y visualizaciones.
Módulos necesarios:
pip install numpy pip install pandas pip install matplotlib
Aquí está el DataFrame desde el cual ilustramos las barras de error con la media y la estándar:
Python3
# Import the necessary libraries to read
# dataset and work on that
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Make the dataframe for evaluation on Errorbars
df = pd.DataFrame({
'insert': [0.0, 0.1, 0.3, 0.5, 1.0],
'mean': [0.009905, 0.45019, 0.376818, 0.801856, 0.643859],
'quality': ['good', 'good', 'poor', 'good', 'poor'],
'std': [0.003662, 0.281895, 0.306806, 0.243288, 0.322378]})
print(df)
Producción:
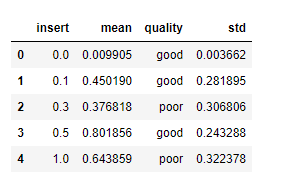
Marco de datos de muestra
groupby las subparcelas con mean y std para obtener barras de error:
Python3
# Subplots as having two types of quality
fig, ax = plt.subplots()
for key, group in df.groupby('quality'):
group.plot('insert', 'mean', yerr='std',
label=key, ax=ax)
plt.show()
Producción:
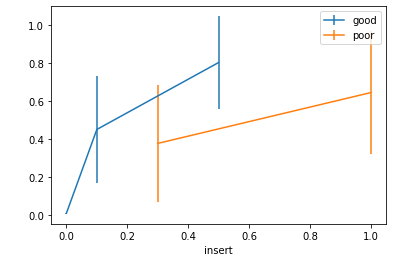
Ejemplo 1: ErrorBar con gráfico de grupo
Ahora vemos barras de error usando las palabras clave de NumPy de mean y std:
Python3
# Groupby the quality column using aggregate
# value of mean and std
qual = df.groupby("quality").agg([np.mean, np.std])
qual = qual['insert']
qual.plot(kind = "barh", y = "mean", legend = False,
xerr = "std", title = "Quality", color='green')
Producción:
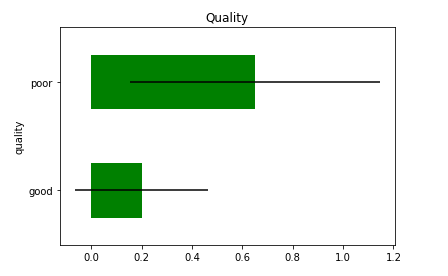
Ejemplo 2: ErrorBar con gráfico de barras
Con el ejemplo anterior, podemos ver que los errores en mala calidad son más altos que buenos en lugar de más buenos valores en el marco de datos.
Ahora, pasamos a otro ejemplo con marco de datos a continuación:
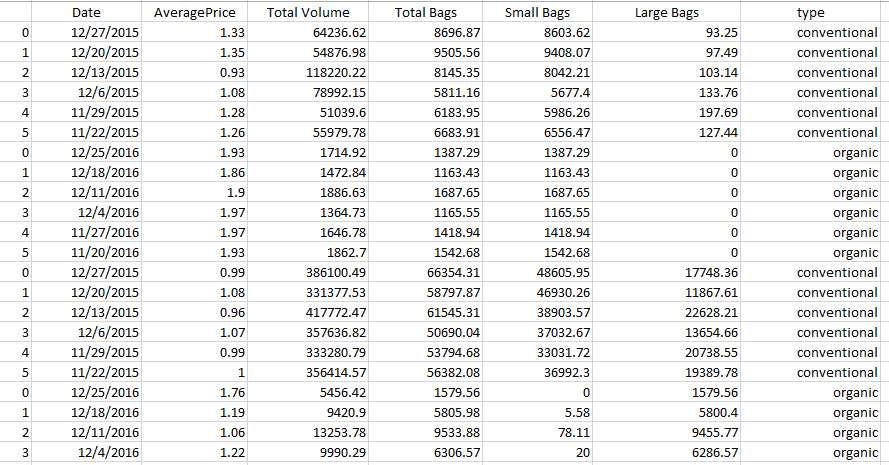
Conjunto de datos: tostadas
Por el marco de datos anterior, tenemos que manipular este marco de datos para obtener las barras de error usando la columna ‘tipo’ que tiene diferentes precios de las bolsas. Para manipular y realizar cálculos, debemos usar una función df.groupby que tiene un prototipo para verificar el campo y ejecutar la función para evaluar el resultado.
Estamos usando dos funciones incorporadas de mean y std:
df.groupby("col_to_group_by").agg([func_1, func_2, func_3, .....])
Python3
# reading the dataset
df = pd.read_csv('Toast.csv')
df_prices = df.groupby("type").agg([np.mean, np.std])
Como tenemos que evaluar el precio promedio, aplique este grupo en ‘Precio promedio’. Además, verifique el resultado de los precios y con la visualización muestre las barras de error.
Python3
prices = df_prices['AveragePrice'] # checking for results prices.head()
Producción:
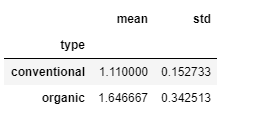
Resultado: el valor agregado de groupby()
Barra de error usando la media:
Python3
prices.plot(kind = "barh", y = "mean", legend = False, title = "Average Prices")
Producción:
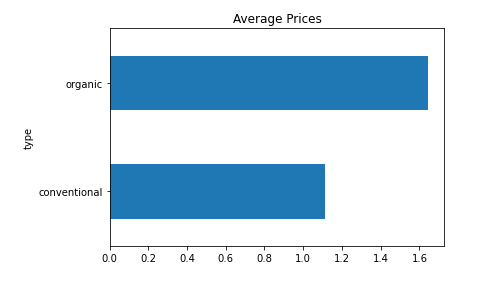
Ejemplo 3: barra de error con media
Por la visualización anterior, está claro que lo orgánico tiene un precio medio más alto que lo convencional .
Barra de error usando la desviación estándar (std):
Python3
prices.plot(kind = "barh", y = "mean", legend = False, title = "Average Prices", xerr = "std")
Producción:
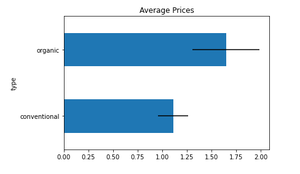
Ejemplo 4: Barra de error con Std
Ventajas de las barras de error:
- Las barras de error son más obstáculos.
- Son fáciles de ejecutar con buenos valores de estimación.
- Relativamente uniforme debido al poder de interpretación complejo con un marco de datos.
Publicación traducida automáticamente
Artículo escrito por night_fury1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA