El intervalo de confianza es un tipo de estimación calculada a partir de las estadísticas de los datos observados que proporciona un rango de valores que es probable que contenga un parámetro de población con un nivel particular de confianza.
Un intervalo de confianza para la media es un rango de valores entre los cuales posiblemente se encuentre la media de la población. Si hiciera una predicción meteorológica para mañana entre -100 y +100 grados, puedo estar 100 % seguro de que será correcta. Sin embargo, si hago la predicción entre 20,4 y 20,5 grados centígrados, tengo menos confianza. Observe cómo disminuye la confianza a medida que disminuye el intervalo. Lo mismo se aplica a los intervalos de confianza estadísticos, pero también dependen de otros factores.
Un intervalo de confianza del 95 % me dirá que si tomamos un número infinito de muestras de mi población, calculamos el intervalo cada vez, entonces en el 95 % de esos intervalos, el intervalo contendrá la verdadera media de la población. Entonces, con una muestra podemos calcular la media de la muestra y, a partir de ahí, obtener un intervalo a su alrededor, que muy probablemente contendrá la verdadera media de la población.
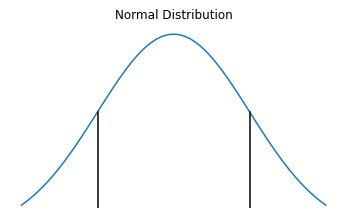
El área debajo de las dos líneas negras muestra el intervalo de confianza del 95 %
Intervalo de confianza como concepto fue presentado por Jerzy Neyman en un artículo publicado en 1937. Hay varios tipos de intervalo de confianza, algunos de los más utilizados son: IC para la media, IC para la mediana, IC para la diferencia entre medias, IC para una proporción e IC para la diferencia de proporciones.
Echemos un vistazo a cómo va esto con Python.
Cálculo de CI dada la distribución subyacente usando lineplot()
La función lineplot() que está disponible en Seaborn, una biblioteca de visualización de datos para Python, es la mejor para mostrar tendencias durante un período de tiempo; sin embargo, también ayuda a trazar el intervalo de confianza.
Sintaxis:
sns.lineplot(x=Ninguno, y=Ninguno, tono=Ninguno, tamaño=Ninguno, estilo=Ninguno, datos=Ninguno, paleta=Ninguno, hue_order=Ninguno, hue_norm=Ninguno, tamaños=Ninguno, size_order=Ninguno, size_norm= Ninguno, guiones=Verdadero, marcadores=Ninguno, estilo_orden=Ninguno, unidades=Ninguno, estimador=’media’, ci=95, n_boot=1000, sort=Verdadero, err_style=’banda’, err_kws=Ninguno, leyenda=’breve ‘, ax=Ninguno, **kwargs,)
Parámetros:
- x, y: variables de datos de entrada; debe ser numérico. Puede pasar datos directamente o hacer referencia a columnas en los datos.
- matiz: variable de agrupación que producirá líneas con diferentes colores. Puede ser categórico o numérico, aunque el mapeo de colores se comportará de manera diferente en el último caso.
- estilo: variable de agrupación que producirá líneas con diferentes guiones y/o marcadores. Puede tener un tipo numérico pero siempre será tratado como categórico.
- datos: marco de datos ordenado («formato largo») donde cada columna es una variable y cada fila es una observación.
- marcadores: Objeto que determina cómo dibujar los marcadores para diferentes niveles de la variable de estilo.
- leyenda: Cómo dibujar la leyenda. Si es «breve», las variables numéricas de «tono» y «tamaño» se representarán con una muestra de valores espaciados uniformemente.
Retorno: El objeto Axes que contiene el gráfico.
De forma predeterminada, la gráfica agrega varios valores de y en cada valor de x y muestra una estimación de la tendencia central y un intervalo de confianza para esa estimación.
Ejemplo:
Python3
# import libraries import numpy as np import seaborn as sns import matplotlib.pyplot as plt # generate random data np.random.seed(0) x = np.random.randint(0, 30, 100) y = x+np.random.normal(0, 1, 100) # create lineplot ax = sns.lineplot(x, y)
En el código anterior, la variable x almacenará 100 números enteros aleatorios desde 0 (inclusive) hasta 30 (exclusivo) y la variable y almacenará 100 muestras de la distribución gaussiana (normal) que está centrada en 0 con desviación estándar/spread 1. Operaciones NumPy generalmente se realizan en pares de arrays elemento por elemento. En el caso más simple, las dos arrays deben tener exactamente la misma forma, como en el ejemplo anterior. Finalmente, se crea un gráfico lineal con la ayuda de la biblioteca Seaborn con un intervalo de confianza del 95 % de forma predeterminada. El intervalo de confianza se puede cambiar fácilmente cambiando el valor del parámetro ‘ci’ que se encuentra dentro del rango de [0, 100], aquí no he pasado este parámetro, por lo que considera el valor predeterminado 95.
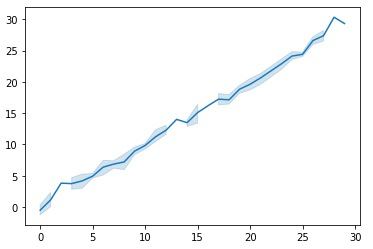
La sombra azul claro indica el nivel de confianza alrededor de ese punto, si tiene una confianza más alta, la línea sombreada será más gruesa.
Cálculo de CI dada la distribución subyacente usando replot()
El seaborn.regplot() ayuda a trazar datos y un ajuste de modelo de regresión lineal. Esta función también permite graficar el intervalo de confianza.
Sintaxis:
seaborn.regplot( x, y, data=Ninguno, x_estimator=Ninguno, x_bins=Ninguno, x_ci=’ci’, scatter=True, fit_reg=True, ci=95, n_boot=1000, units=Ninguno, order=1, logistic=falso, lowess=falso, robusto=falso, logx=falso, x_partial=ninguno, y_partial=ninguno, truncate=falso, dropna=verdadero, x_jitter=ninguno, y_jitter=ninguno, label=ninguno, color=ninguno, marcador= ‘o’, scatter_kws=Ninguno, line_kws=Ninguno, ax=Ninguno)
Parámetros: La descripción de algunos parámetros principales se da a continuación:
- x, y: estas son variables de entrada. Si son strings, estas deben corresponder con los nombres de las columnas en «datos». Cuando se utilizan objetos pandas, los ejes se etiquetarán con el nombre de la serie.
- datos: este es un marco de datos donde cada columna es una variable y cada fila es una observación.
- lowess: (opcional) Este parámetro toma valor booleano. Si es «Verdadero», use «modelos estadísticos» para estimar un modelo de valor mínimo no paramétrico (regresión lineal ponderada localmente).
- color: (opcional) Color para aplicar a todos los elementos de la trama.
- marcador: (opcional) Marcador que se usará para los glifos del diagrama de dispersión.
Retorno: El objeto Axes que contiene el gráfico.
Básicamente, incluye una línea de regresión en el diagrama de dispersión y ayuda a ver cualquier relación lineal entre dos variables. El siguiente ejemplo mostrará cómo se puede usar para trazar el intervalo de confianza también.
Ejemplo:
Python3
# import libraries import numpy as np import seaborn as sns import matplotlib.pyplot as plt # create random data np.random.seed(0) x = np.random.randint(0, 10, 10) y = x+np.random.normal(0, 1, 10) # create regression plot ax = sns.regplot(x, y, ci=80)
La función regplot() funciona de la misma manera que lineplot() con un intervalo de confianza del 95 % de forma predeterminada. El intervalo de confianza se puede cambiar fácilmente cambiando el valor del parámetro ‘ci’ que se encuentra en el rango de [0, 100]. Aquí he pasado ci=80, lo que significa que en lugar del intervalo de confianza predeterminado del 95 %, se traza un intervalo de confianza del 80 %.
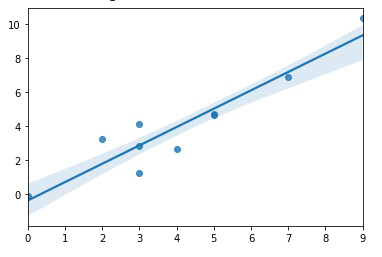
El ancho del tono de color azul claro indica el nivel de confianza alrededor de la línea de regresión.
Cálculo de CI usando Bootstrapping
Bootstrapping es una prueba/métrica que utiliza muestreo aleatorio con reemplazo. Proporciona la medida de precisión (sesgo, varianza, intervalos de confianza, error de predicción, etc.) para las estimaciones de la muestra. Permite la estimación de la distribución muestral para la mayoría de las estadísticas utilizando métodos de muestreo aleatorio. También se puede utilizar para construir pruebas de hipótesis.
Ejemplo:
Python3
# import libraries
import pandas
import numpy
from sklearn.utils import resample
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
# load dataset
x = numpy.array([180,162,158,172,168,150,171,183,165,176])
# configure bootstrap
n_iterations = 1000 # here k=no. of bootstrapped samples
n_size = int(len(x))
# run bootstrap
medians = list()
for i in range(n_iterations):
s = resample(x, n_samples=n_size);
m = numpy.median(s);
medians.append(m)
# plot scores
plt.hist(medians)
plt.show()
# confidence intervals
alpha = 0.95
p = ((1.0-alpha)/2.0) * 100
lower = numpy.percentile(medians, p)
p = (alpha+((1.0-alpha)/2.0)) * 100
upper = numpy.percentile(medians, p)
print(f"\n{alpha*100} confidence interval {lower} and {upper}")
Después de importar todas las bibliotecas necesarias, cree una muestra S con tamaño n=10 y guárdela en una variable x. Usando un bucle simple, genere 1000 muestras artificiales (=k) con cada tamaño de muestra m=10 (ya que m<=n). Estas muestras se denominan muestras de arranque. Sus medianas se calculan y almacenan en una lista de ‘medianas’. El histograma de las medianas de 1000 muestras de arranque se traza con la ayuda de la biblioteca matplotlib y, utilizando la fórmula, se calcula el intervalo de confianza de una estadística de muestra, se calcula un límite superior e inferior para el valor de población de la estadística en un nivel específico de confianza basado en datos de muestra. .
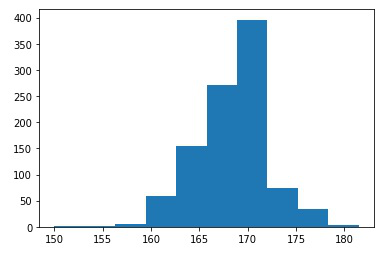
El intervalo de confianza de 95,0 se encuentra entre 161,5 y 176,0
Publicación traducida automáticamente
Artículo escrito por swapnilvishwakarma7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA