El índice es como una dirección, así es como se puede acceder a cualquier punto de datos en el marco de datos o serie. Las filas y las columnas tienen índices, los índices de las filas se denominan índice y las columnas, son los nombres generales de las columnas.
Índices jerárquicos
Los índices jerárquicos también se conocen como indexación múltiple y establece más de un nombre de columna como índice. En este artículo, vamos a utilizar el archivo homelessness.csv .
Python3
# importing pandas library as alias pd
import pandas as pd
# calling the pandas read_csv() function.
# and storing the result in DataFrame df
df = pd.read_csv('homelessness.csv')
print(df.head())
Producción:

En el siguiente marco de datos, no hay indexación.
Columnas en el marco de datos:
Python3
# using the pandas columns attribute. col = df.columns print(col)
Producción:
Índice ([‘Sin nombre: 0’, ‘región’, ‘estado’, ‘individuos’, ‘miembros de la familia’,
‘pop_estado’],
dtype=’objeto’)
Para convertir la columna en un índice, usamos la función Set_index() de pandas. Si queremos convertir una columna en un índice, simplemente podemos pasar el nombre de la columna como una string en set_index(). Si queremos hacer indexación múltiple o indexación jerárquica, pasamos la lista de nombres de columna en set_index().
El siguiente código demuestra la indexación jerárquica en pandas:
Python3
# using the pandas set_index() function. df_ind3 = df.set_index(['region', 'state', 'individuals']) # we can sort the data by using sort_index() df_ind3.sort_index() print(df_ind3.head(10))
Producción:
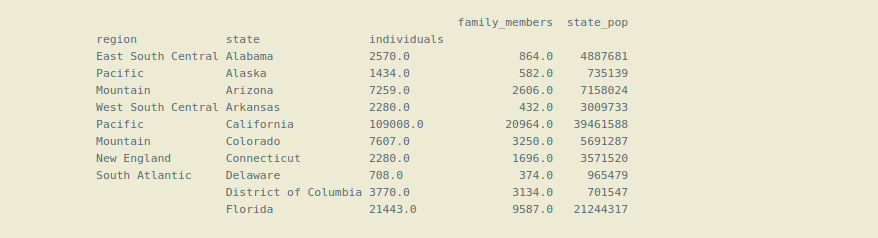
Ahora el marco de datos está utilizando la indexación jerárquica o la indexación múltiple.
Tenga en cuenta que aquí hemos creado 3 columnas como índice (‘región’, ‘estado’, ‘individuos’). El primer índice ‘región’ se llama índice de nivel (0), que está en la parte superior de la jerarquía de índices, el siguiente índice ‘estado’ es el índice de nivel (1) que está debajo del índice principal o de nivel (0), y así sucesivamente . Entonces, se forma la jerarquía de índices, por eso se llama indexación jerárquica .
A veces es posible que necesitemos hacer una columna como índice, o queremos convertir una columna de índice en la columna normal, por lo que hay una función pandas reset_index (inplace = True) , que hace que la columna de índice sea la columna normal.
Selección de datos en un índice jerárquico o uso de la indexación jerárquica:
Para seleccionar los datos del dataframe usando el método .loc() tenemos que pasar el nombre de los índices en una lista.
Python3
# selecting the 'Pacific' and 'Mountain' # region from the dataframe. # selecting data using level(0) index or main index. df_ind3_region = df_ind3.loc[['Pacific', 'Mountain']] print(df_ind3_region.head(10))
Producción:
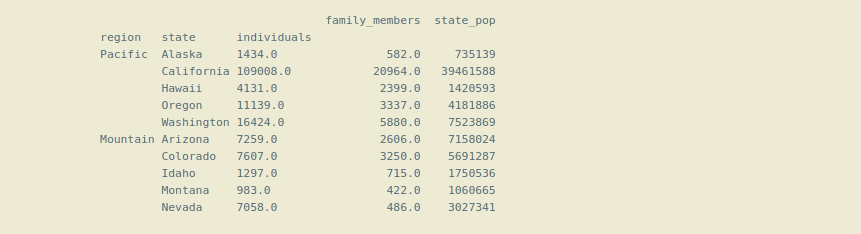
No podemos usar solo el índice de nivel (1) para obtener datos del marco de datos, si lo hacemos, dará un error. Solo podemos usar el índice de nivel (1) o los índices internos con el nivel (0) o el índice principal con la lista de ayuda de tuplas.
Python3
# using the inner index 'state' for getting data. df_ind3_state = df_ind3.loc[['Alaska', 'California', 'Idaho']] print(df_ind3_state.head(10))
Producción:
Usando índices de niveles internos con la ayuda de una lista de tuplas:
Sintaxis:
df.loc[[ ( level( 0 ) , level( 1 ) , level( 2 ) ) ]]
Python3
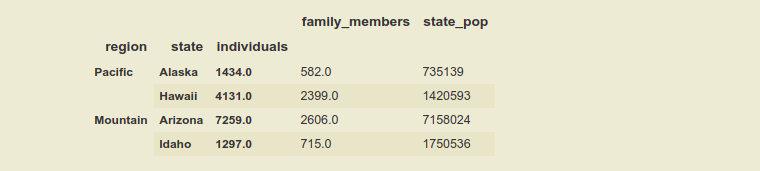
# selecting data by passing all levels index.
df_ind3_region_state = df_ind3.loc[[("Pacific", "Alaska", 1434),
("Pacific", "Hawaii", 4131),
("Mountain", "Arizona", 7259),
("Mountain", "Idaho", 1297)]]
df_ind3_region_state
Producción:
Publicación traducida automáticamente
Artículo escrito por pawanagrawalp847 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA