En este artículo, vamos a ver cómo usar Pandas apply() en su lugar en Python.
En Python, esta función es equivalente a la función map() . Toma una función como entrada y la aplica a un DataFrame como un todo. Si está tratando con datos en forma de tablas, deberá elegir en qué eje debe actuar su función (0 para columnas y 1 para filas).
¿El método pandas apply() tiene un parámetro en el lugar?
No, el método apply() no contiene un parámetro en el lugar, a diferencia de estos métodos de pandas que tienen un parámetro en el lugar:
- df.soltar()
- df.rename(inplace=True)
- relleno()
- dropna()
- ordenar_valores()
- reset_index()
- sort_index()
- rebautizar()
¿Qué significa realmente el parámetro inplace?
Los datos se editan en el lugar cuando inplace = True, lo que significa que no devolverá nada y se actualizará el marco de datos. Cuando inplace = False, que es el predeterminado, se realiza la operación y se devuelve una copia del objeto.
Ejemplo 1: aplicar() en su lugar para una columna
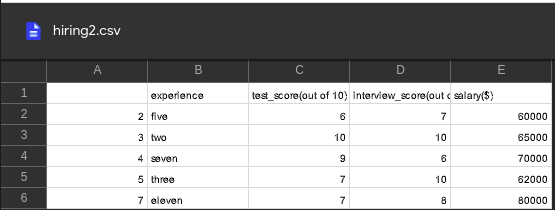
en el siguiente código. primero importamos el paquete pandas e importamos nuestro archivo CSV usando pd.read_csv() . después de importar, usamos la función de aplicación en la columna ‘experiencia’ de nuestro marco de datos. convertimos las strings de esa columna a mayúsculas.
Archivo CSV usado:
Python3
# code
import pandas as pd
# importing our dataset
df = pd.read_csv('hiring.csv')
# viewing the dataFrame
print(df)
# we change the case of all the strings
# in experience column to uppercase
df['experience'] = df['experience'].apply(str.upper)
# viewing the modified column
print(df['experience'])
Producción:
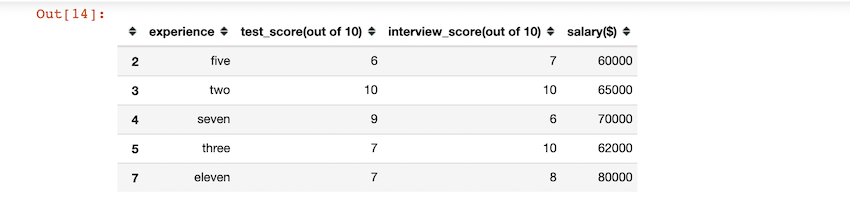
0 FIVE 1 TWO 2 SEVEN 3 THREE 4 ELEVEN Name: experience, dtype: object
Ejemplo 2: aplicar() en su lugar para varias columnas
En este ejemplo, usamos el método apply() en varias columnas. cambiamos el tipo de datos de las columnas de float a int. Archivo CSV usado haga clic aquí .
Python3
import pandas as pd
import numpy as np
# importing our dataset
data = pd.read_csv('cluster_blobs.csv')
# viewing the dataFrame
print(df)
# we convert the datatype of columns from float to int.
data[['X1', 'X2']] = data[['X1', 'X2']].apply(np.int64)
# viewing the modified column
print(data[['X1', 'X2']])
Producción:
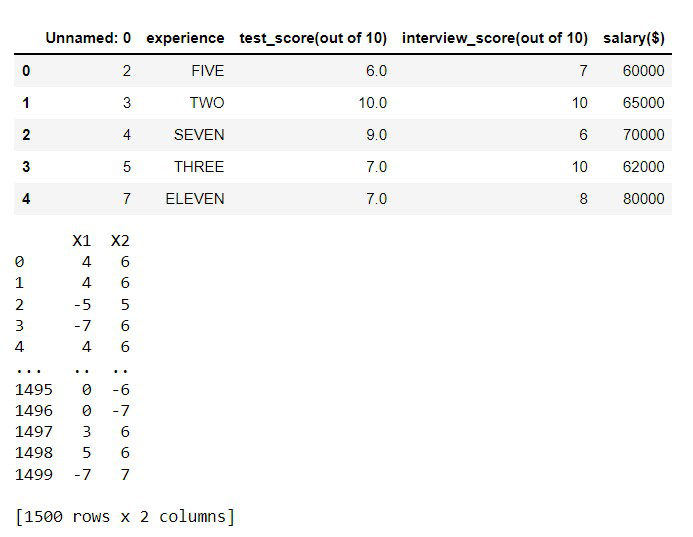
Ejemplo 3: apply() en su lugar para todas las columnas.
en este ejemplo, usamos el mismo archivo CSV que antes. aquí usamos el método apply() en todo el marco de datos. cambiamos el tipo de datos de las columnas de float a int.
Python3
import pandas as pd
import numpy as np
# importing our dataset
data = pd.read_csv('cluster_blobs.csv')
# viewing the dataFrame
print(data)
# we convert the datatype of
# columns from float to int.
data = data.apply(np.int64)
# viewing the modified column
print(data)
Producción:

Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA