La API Vision de Google Cloud tiene múltiples funcionalidades. En este artículo veremos cómo acceder a ellos. Antes de usar la API, debe abrir una cuenta de desarrollador de Google, crear una instancia de máquina virtual y configurar una API. Para eso, consulte este artículo.
Necesitamos descargar los siguientes paquetes:
pip install google.cloud.vision
Los diversos servicios realizados por Google Vision API son:
Detección facial:
Puede detectar varios rostros en una imagen y expresar el estado emocional de los rostros.
Guarde el archivo ‘credentials.json’ en la misma carpeta que el archivo .py con el código de Python. Necesitamos guardar la ruta de ‘credentials.json’ (C:\Users\…) como ‘GOOGLE_APPLICATION_CREDENTIALS’, lo cual se hizo en la línea 7 del siguiente código.
Python3
import os
import io
from google.cloud import vision
from matplotlib import pyplot as plt
from matplotlib import patches as pch
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] =
os.path.join(os.curdir, 'credentials.json')
client = vision.ImageAnnotatorClient()
f = 'image_filename.jpg'
with io.open(f, 'rb') as image:
content = image.read()
image = vision.types.Image(content = content)
response = client.face_detection(image = image)
faces = response.face_annotations
possibility = ('UNKNOWN', 'VERY_UNLIKELY', 'UNLIKELY',
'POSSIBLE', 'LIKELY', 'VERY_LIKELY')
a = plt.imread(f)
fig, ax = plt.subplots(1)
ax.imshow(a)
for face in faces:
print('Possibility of anger: {}'.format(possibility[face.anger_likelihood]))
print('Possibility of joy: {}'.format(possibility[face.joy_likelihood]))
print('Possibility of surprise: {}'.format(possibility[face.surprise_likelihood]))
print('Possibility of sorrow: {}'.format(possibility[face.sorrow_likelihood]))
vertices = ([(vertex.x, vertex.y)
for vertex in face.bounding_poly.vertices])
print('Vertices covering face: {}\n\n'.format(vertices))
rect = pch.Rectangle(vertices[0], (vertices[1][0] - vertices[0][0]),
(vertices[2][1] - vertices[0][1]), linewidth = 1,
edgecolor ='r', facecolor ='none')
ax.add_patch(rect)
print('Confidence in Detection: {}%'.format(
face.detection_confidence * 100))
plt.show()
El código anterior detecta varios rostros en una imagen y determina las expresiones emocionales exhibidas por los rostros y si alguno de los rostros lleva un casco. También devuelve los vértices que forman un rectángulo alrededor de las caras individuales.
Por último, imprime el porcentaje de seguridad con el que se extrajeron las conclusiones.
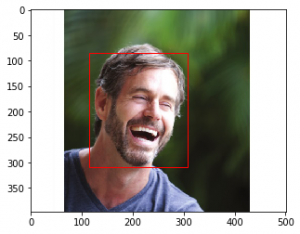
Por ejemplo, cuando se proporciona la siguiente imagen como entrada:

Producción:
Possibility of anger: VERY_UNLIKELY Possibility of joy: VERY_LIKELY Possibility of surprise: VERY_UNLIKELY Possibility of sorrow: VERY_UNLIKELY Vertices covering face: [(115, 84), (308, 84), (308, 309), (115, 309)] Confidence in Detection: 99.93739128112793%
Detección de logotipo:
Detecta logotipos de productos populares presentes en una imagen.
Python3
import os import io from google.cloud import vision from matplotlib import pyplot as plt os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = os.path.join(os.curdir, 'credentials.json') client = vision.ImageAnnotatorClient() f = 'image_filename.jpg' with io.open(f, 'rb') as image: content = image.read() image = vision.types.Image(content = content) response = client.logo_detection(image = image) logos = response.logo_annotations a = plt.imread(f) plt.imshow(a) for logo in logos: print(logo.description)
El código anterior detecta los logotipos de varias empresas en una imagen e imprime el nombre de las empresas. Por ejemplo, cuando se da la siguiente imagen:

Producción:
hp
Detección de etiquetas:
Detecta amplios conjuntos de categorías en una imagen, que van desde animales, árboles hasta vehículos, edificios, etc.
Python3
import os import io from google.cloud import vision from matplotlib import pyplot as plt os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = os.path.join(os.curdir, 'credentials.json') client = vision.ImageAnnotatorClient() f = 'image_filename.jpg' with io.open(f, 'rb') as image: content = image.read() image = vision.types.Image(content = content) response = client.label_detection(image = image) labels = response.label_annotations a = plt.imread(f) plt.imshow(a) for label in labels: print(label.description)
Todas las etiquetas o etiquetas posibles se adjuntan a una imagen. Por ejemplo, cuando se da la siguiente imagen como entrada:

Producción:
Street Neighbourhood Café Coffeehouse Sitting Leisure Tourism Restaurant Street performance City
Detección de puntos de referencia:
Detecta puntos de referencia famosos (en su mayoría hechos por el hombre) dentro de una imagen.
Python3
import os
import io
from google.cloud import vision
from matplotlib import pyplot as plt
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] =
os.path.join(os.curdir, 'credentials.json')
client = vision.ImageAnnotatorClient()
f = 'image_filename.jpg'
with io.open(f, 'rb') as image:
content = image.read()
image = vision.types.Image(content = content)
response = client.landmark_detection(image = image)
landmarks = response.landmark_annotations
a = plt.imread(f)
plt.imshow(a)
for landmark in landmarks:
print(landmark.description)
for location in landmark.locations:
print('Latitude: {}, Longitude: {}'.format(
location.lat_lng.latitude, location.lat_lng.longitude))
El código anterior reconoce cualquier punto de referencia famoso y también devuelve la ubicación de ese punto de referencia utilizando latitudes y longitudes. Por ejemplo, cuando ingresamos la siguiente imagen:

Producción:
Victoria Memorial Latitude: 22.545121, Longitude: 88.342781
Para obtener más información, visite la documentación de la API de Google Vision aquí .
Publicación traducida automáticamente
Artículo escrito por ArijitGayen y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA