Un flujo ordenado de valores para una variable en períodos de tiempo uniformemente espaciados se conoce como serie de tiempo. Las series de tiempo son útiles para identificar los factores y estructuras subyacentes que dieron como resultado los datos observados y después de ajustar un modelo, se puede pasar a la previsión y el seguimiento. algunas aplicaciones de series temporales son Análisis de la Bolsa de Valores, Rendimientos Estimados, estudios de propagación de enfermedades como covid19, etc. Podemos usar series temporales para un dato particular basado en ciertas condiciones. En este artículo, demostremos cómo usar datos de series temporales.
Haga clic aquí para ver y descargar el conjunto de datos.
Utilizar series temporales en Pandas
Todos los ejemplos están hechos sobre datos de covid_19. Después de importar el archivo CSV, las fechas ‘ObservationDate’ y ‘Last Update’ se convierten a fecha y hora mediante el método pd.to_datetime() .
Python3
# import packages
import pandas as pd
# read csv file
df = pd.read_csv('covid_19.csv', encoding='UTF-8')
df['ObservationDate'] = pd.to_datetime(df['ObservationDate'])
df['Last Update'] = pd.to_datetime(df['Last Update'])
print(df)
Producción:
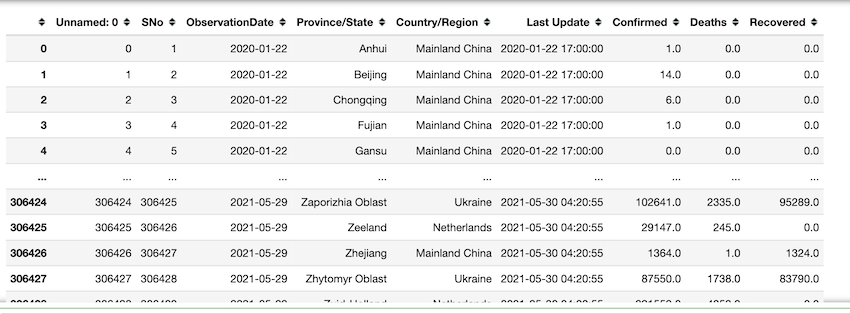
Extraiga todas las observaciones antes de 2021. Se recuperan 192466 filas.
Python3
df[df['ObservationDate']<='2021']
Producción:
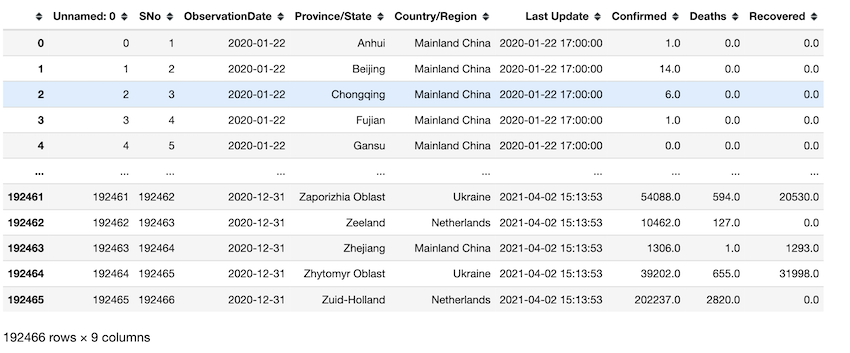
Recuperación de observaciones de un día en particular. en este ejemplo, configuramos el día para que sea ‘2020-06’.
Python3
df[df['ObservationDate'] == '2020-06']
Producción:
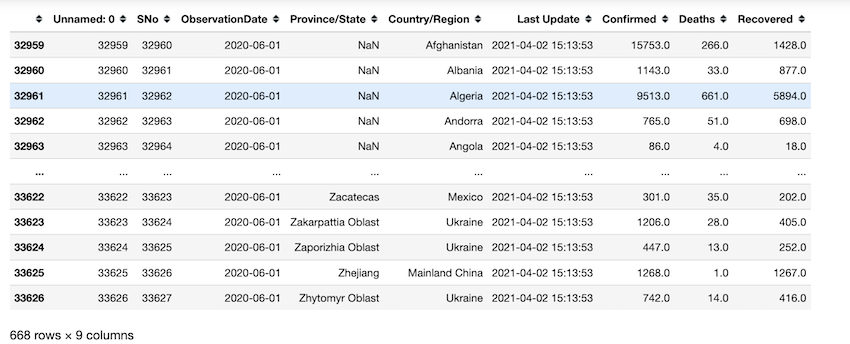
Recuperando el día en que las muertes máximas son las más altas. el 2021-05-29 se registra el máximo de muertes del Reino Unido según nuestros datos.
Python3
df[df['Deaths'] == max(df['Deaths'])]
Producción:

Producción
Suma de todas las muertes el ‘2021-05-20’.
Python3
sum(df[df['ObservationDate'] == '2021-05-20']['Deaths'])
Producción:
3430539.0
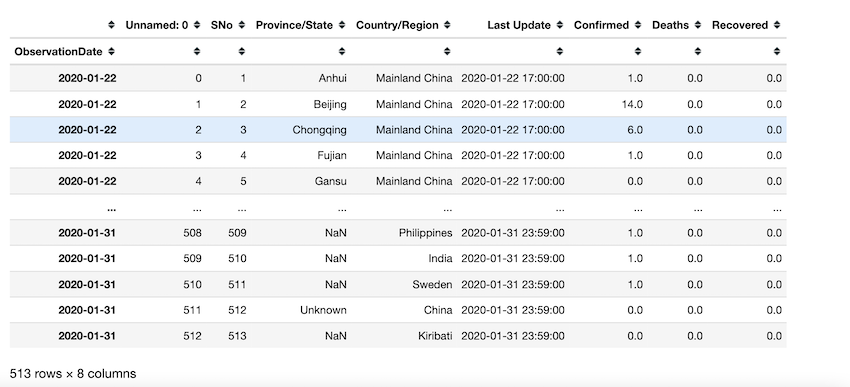
En lugar de trabajar de la manera difícil para recuperar datos, podemos establecer columnas de series de tiempo en fecha y hora y establecerlas como el índice del marco de datos para recuperar fácilmente la información que necesitamos. ObservationDate se establece como el índice del marco de datos en este ejemplo. al usar df.loc() podemos indexar y acceder a la información requerida por fechas directamente. df.loc[‘2020-01’] recupera todos los datos de esa fecha. La salida muestra que hay 513 observaciones.
Python3
# import packages
import pandas as pd
# read csv file
df = pd.read_csv('covid_19.csv')
df['ObservationDate'] = pd.to_datetime(df['ObservationDate'])
df['Last Update'] = pd.to_datetime(df['Last Update'])
df = df.set_index('ObservationDate')
print(df.loc['2020-01'])
Producción:
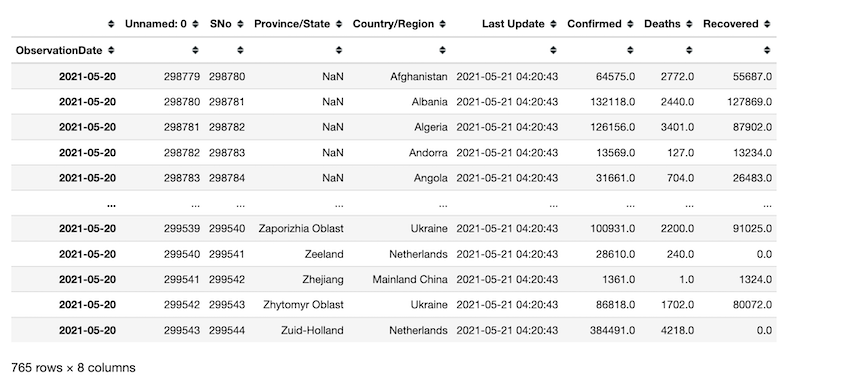
Las observaciones tomadas del 20 al 21 de mayo de 2021 se recuperan mediante indexación.
Python3
# import packages
import pandas as pd
# read csv file
df = pd.read_csv('covid_19.csv')
df['ObservationDate'] = pd.to_datetime(df['ObservationDate'])
df['Last Update'] = pd.to_datetime(df['Last Update'])
df = df.set_index('ObservationDate')
# observations taken from may 20th to may 21st of 2021
df.loc['2021-05-20':'2021-05-21']
Producción:
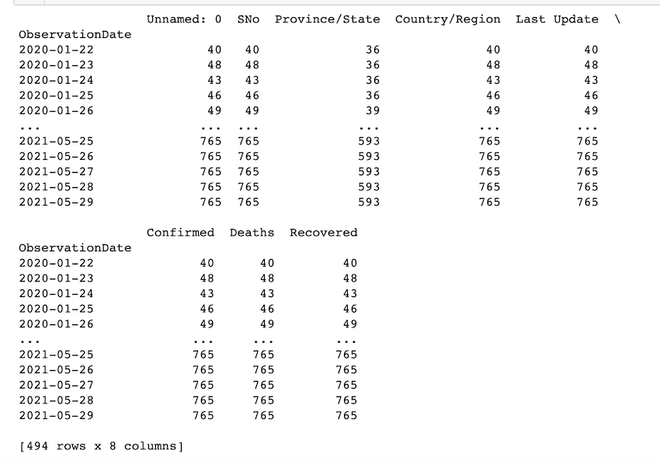
En este ejemplo, df.groupby() se usa para agrupar todas las observaciones según la fecha en que se actualizaron y contarlas. por ejemplo, la primera fila dice que hay 40 observaciones en ‘2020-01-22’.
Python3
# import packages
import pandas as pd
# read csv file
df = pd.read_csv('covid_19.csv')
df['ObservationDate'] = pd.to_datetime(df['ObservationDate'])
df['Last Update'] = pd.to_datetime(df['Last Update'])
df = df.set_index('ObservationDate')
print(df.groupby(level=0).count())
Producción:
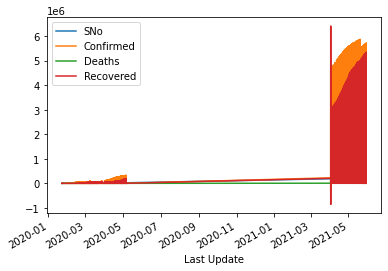
Después de establecer el índice del marco de datos en series de tiempo, usamos el método df.plot.line() para visualizar toda la información a través de un gráfico de una sola línea. Los datos de series temporales nos ayudan a sacar buenas conclusiones.
Python3
# import packages and libraries
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
# reading the dataset
df = pd.read_csv('covid_19_data.csv', encoding='UTF-8')
# convert Last update column to datetime
df['Last Update'] = pd.to_datetime(df['Last Update'])
# setting index
df.set_index('Last Update', inplace=True)
# plotting figure
df.plot.line()
Producción:
Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA