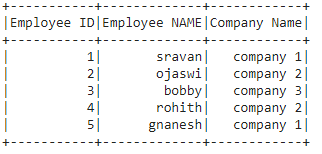
En este artículo, vamos a verificar el esquema del marco de datos pyspark. Vamos a utilizar el marco de datos a continuación para la demostración.
Método 1: Usar df.schema
El esquema se utiliza para devolver las columnas junto con el tipo.
Sintaxis : dataframe.schema
Donde, el marco de datos es el marco de datos de entrada
Código:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"]]
# specify column names
columns = ['Employee ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe columns
dataframe.schema
Producción:
StructType(List(StructField(Employee ID,StringType,true), StructField(Employee NAME,StringType,true), StructField(Company Name,StringType,true)))
Método 2: Usar schema.fields
Se utiliza para devolver los nombres de las columnas.
Sintaxis: dataframe.schema.fields
donde marco de datos es el nombre del marco de datos
Código:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"]]
# specify column names
columns = ['Employee ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe columns
dataframe.schema.fields
Producción:
[StructField(Employee ID,StringType,true), StructField(Employee NAME,StringType,true), StructField(Company Name,StringType,true)]
Método 3: Usando printSchema()
Se utiliza para devolver el esquema con nombres de columna.
Sintaxis: dataframe.printSchema()
donde dataframe es el marco de datos de pyspark de entrada
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"]]
# specify column names
columns = ['Employee ID', 'Employee NAME', 'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe columns
dataframe.printSchema()
Producción:
root |-- Employee ID: string (nullable = true) |-- Employee NAME: string (nullable = true) |-- Company Name: string (nullable = true)
Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA