En este artículo, veremos cómo verificar una substring en el marco de datos de PySpark.
La substring es una secuencia continua de caracteres dentro de un tamaño de string más grande. Por ejemplo, «aprendiendo pyspark» es una substring de «Estoy aprendiendo pyspark de GeeksForGeeks». Veamos las diferentes formas en que podemos encontrar una substring de una o más columnas de un marco de datos de PySpark.
Creando Dataframe para demostración:
Python
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# Column names for the dataframe
columns = ["LicenseNo", "ExpiryDate"]
# Row data for the dataframe
data = [
("MH201411094334", "2024-11-19"),
("AR202027563890", "2030-03-16"),
("UP202010345567", "2035-12-30"),
("KN201822347800", "2028-10-29"),
]
# Create the dataframe using the above values
reg_df = spark.createDataFrame(data=data,
schema=columns)
# View the dataframe
reg_df.show()
Producción:
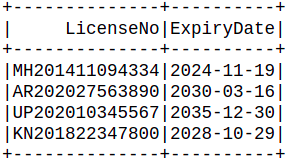
En el marco de datos anterior, LicenseNo se compone de 3 información, código de estado de 2 letras + año de registro + número de registro de 8 dígitos.
Método 1: U sar DataFrame.withColumn()
El DataFrame.withColumn(colName, col) se puede usar para extraer una substring de los datos de la columna usando la función substring() de pyspark junto con ella.
Sintaxis: DataFrame.withColumn(colName, col)
Parámetros:
- colName: str, nombre de la nueva columna
- col: str, una expresión de columna para la nueva columna
Devuelve un nuevo DataFrame agregando una columna o reemplazando la columna existente que tiene el mismo nombre.
Haremos uso de la función substring() de pyspark para crear una nueva columna «Estado» extrayendo la substring respectiva de la columna LicenseNo.
Sintaxis: pyspark.sql.functions.substring(str, pos, len)
Ejemplo 1: para columnas individuales como substring.
Python
from pyspark.sql.functions import substring
reg_df.withColumn(
'State', substring('LicenseNo', 1, 2)
).show()
Producción:
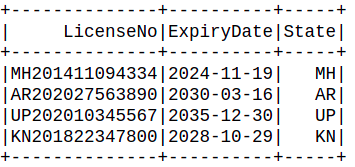
Aquí, hemos creado una nueva columna «Estado» donde la substring se toma de la columna «LicenseNo». (1, 2) indica que debemos comenzar desde el primer carácter y extraer 2 caracteres de la columna «LicenseNo».
Ejemplo 2: para varias columnas como substring
Extracción del código de estado como ‘Estado’, Año de registro como ‘RegYear’, ID de registro como ‘RegID’, Año de vencimiento como ‘ExpYr’, Fecha de vencimiento como ‘ExpDt’, Mes de vencimiento como ‘ExpMo’.
Python
from pyspark.sql.functions import substring
reg_df \
.withColumn('State' , substring('LicenseNo' , 1, 2)) \
.withColumn('RegYear', substring('LicenseNo' , 3, 4)) \
.withColumn('RegID' , substring('LicenseNo' , 7, 8)) \
.withColumn('ExpYr' , substring('ExpiryDate', 1, 4)) \
.withColumn('ExpMo' , substring('ExpiryDate', 6, 2)) \
.withColumn('ExpDt' , substring('ExpiryDate', 9, 2)) \
.show()
Producción:
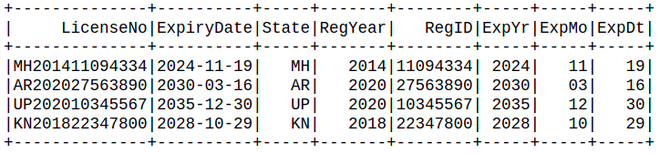
El código anterior demuestra cómo el método withColumn() se puede usar varias veces para obtener varias columnas de substrings. Cada método withColumn() agrega una nueva columna en el marco de datos. Vale la pena señalar que también conserva las columnas originales.
Método 2: usar substr en lugar de substring
Alternativamente, también podemos usar substr del tipo de columna en lugar de usar substring.
Sintaxis: pyspark.sql.Column.substr(startPos, longitud)
Devuelve una columna que es una substring de la columna que comienza en ‘startPos’ en byte y tiene una longitud de ‘longitud’ cuando ‘str’ es de tipo binario.
Ejemplo: uso de substr
Python
from pyspark.sql.functions import col
reg_df \
.withColumn('State' , col('LicenseNo' ).substr(1, 2)) \
.withColumn('RegYear', col('LicenseNo' ).substr(3, 4)) \
.withColumn('RegID' , col('LicenseNo' ).substr(7, 8)) \
.withColumn('ExpYr' , col('ExpiryDate').substr(1, 4)) \
.withColumn('ExpMo' , col('ExpiryDate').substr(6, 2)) \
.withColumn('ExpDt' , col('ExpiryDate').substr(9, 2)) \
.show()
Producción:
El método substr() funciona junto con la función col del módulo spark.sql . Sin embargo, más o menos es solo un cambio sintáctico y la lógica de posicionamiento sigue siendo la misma.
Método 3: Usando DataFrame.select()
Aquí usaremos la función select() para crear substrings en el marco de datos.
Sintaxis: pyspark.sql.DataFrame.select(*columnas)
Ejemplo: Uso de DataFrame.select()
Python
from pyspark.sql.functions import substring
reg_df.select(
substring('LicenseNo' , 1, 2).alias('State') ,
substring('LicenseNo' , 3, 4).alias('RegYear'),
substring('LicenseNo' , 7, 8).alias('RegID') ,
substring('ExpiryDate', 1, 4).alias('ExpYr') ,
substring('ExpiryDate', 6, 2).alias('ExpMo') ,
substring('ExpiryDate', 9, 2).alias('ExpDt') ,
).show()
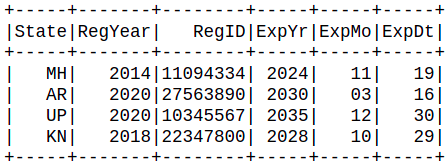
Producción:
Método 4: Usar ‘spark.sql()’
El método spark.sql() ayuda a ejecutar consultas SQL relacionales dentro de Spark. Permite la ejecución de consultas relacionales, incluidas las expresadas en SQL utilizando Spark.
Sintaxis: spark.sql(expresión)
Ejemplo: Usar ‘spark.sql()’
Python
reg_df.createOrReplaceTempView("reg_view")
reg_df2 = spark.sql('''
SELECT
SUBSTR(LicenseNo, 1, 3) AS State,
SUBSTR(LicenseNo, 3, 4) AS RegYear,
SUBSTR(LicenseNo, 7, 8) AS RegID,
SUBSTR(ExpiryDate, 1, 4) AS ExpYr,
SUBSTR(ExpiryDate, 6, 2) AS ExpMo,
SUBSTR(ExpiryDate, 9, 2) AS ExpDt
FROM reg_view;
''')
reg_df2.show()
Producción:
Aquí, podemos ver que la expresión utilizada dentro de spark.sql() es una consulta SQL relacional. También podemos usar lo mismo en un editor de consultas SQL para obtener la salida respectiva.
Método 5: Usar spark.DataFrame.selectExpr()
Usar el método selectExpr() es una forma de proporcionar consultas SQL, pero es diferente de las relacionales. Podemos proporcionar una o más expresiones SQL dentro del método. Toma una o más expresiones SQL en una string y devuelve un nuevo marco de datos
Sintaxis: selectExpr(exprs)
Ejemplo: uso de spark.DataFrame.selectExpr().
Python
from pyspark.sql.functions import substring reg_df.selectExpr( 'LicenseNo', 'ExpiryDate', 'substring(LicenseNo , 1, 2) AS State' , 'substring(LicenseNo , 3, 4) AS RegYear' , 'substring(LicenseNo , 7, 8) AS RegID' , 'substring(ExpiryDate, 1, 4) AS ExpYr' , 'substring(ExpiryDate, 6, 2) AS ExpMo' , 'substring(ExpiryDate, 9, 2) AS ExpDt' , ).show()
Producción:
En el fragmento de código anterior, podemos observar que hemos proporcionado múltiples expresiones SQL dentro del método selectExpr() . Cada una de estas expresiones se parece a una parte de la consulta SQL relacional que escribimos. También preservamos las columnas originales al mencionarlas explícitamente.
Publicación traducida automáticamente
Artículo escrito por apathak092 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA