Es bien sabido que Python es un lenguaje multiparadigma de propósito general que se usa ampliamente para el análisis de datos debido a su amplio soporte de biblioteca y una comunidad activa. Los métodos más conocidos para comparar dos marcos de datos de Pandas usando python son:
- Usando difflib
- usando fuzzywuzzy
- Coincidencia de expresiones regulares
Estos métodos son ampliamente utilizados por desarrolladores experimentados y nuevos, pero ¿qué sucede si necesitamos un informe para encontrar todas las columnas y filas coincidentes o no coincidentes? Aquí es cuando la biblioteca DataComPy entra en escena.
DataComPy es una biblioteca de Pandas de código abierto de capitalone. Se inició con el objetivo de reemplazar PROC COMPARE para los marcos de datos de Pandas. Toma dos marcos de datos como entrada y nos brinda un informe legible por humanos que contiene estadísticas que nos permiten conocer las similitudes y diferencias entre los dos marcos de datos.
Instalar a través de pip3:
pip3 install datacompy
Ejemplo:
from io import StringIO import pandas as pd import datacompy data1 = """employee_id, name 1, rajiv kapoor 2, rahul agarwal 3, alice johnson """ data2 = """employee_id, name 1, rajiv khanna 2, rahul aggarwal 3, alice tyson """ df1 = pd.read_csv(StringIO(data1)) df2 = pd.read_csv(StringIO(data2)) compare = datacompy.Compare( df1, df2, # You can also specify a list # of columns join_columns = 'employee_id', # Optional, defaults to 0 abs_tol = 0, # Optional, defaults to 0 rel_tol = 0, # Optional, defaults to 'df1' df1_name = 'Original', # Optional, defaults to 'df2' df2_name = 'New' ) # if ignore_exra_columns=True, # the function won't return False # in case of non-overlapping # column names compare.matches(ignore_extra_columns = False) # This method prints out a human-readable # report summarizing and sampling # differences print(compare.report())
Producción:
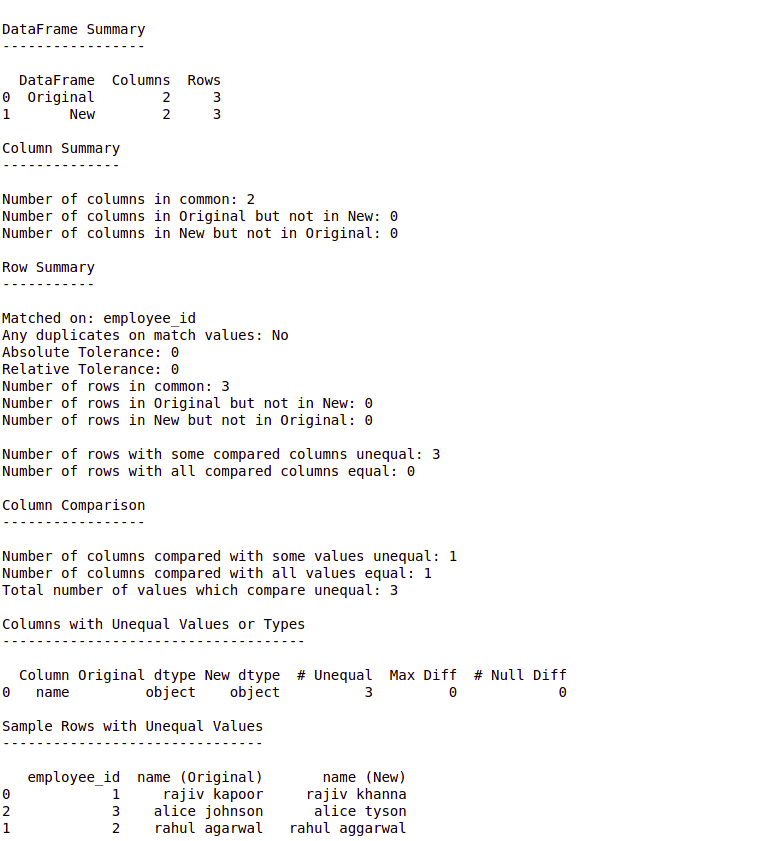
Explicación:
- En el ejemplo anterior, estamos uniendo los dos marcos de datos en una columna coincidente. También podemos pasar:
on_index = Trueen lugar de «join_columns» para unirnos en el índice. Compare.matches()es una función booleana. Devuelve True si hay una coincidencia, de lo contrario devuelve False.- DataComPy de forma predeterminada devuelve True solo si hay una coincidencia del 100 %. Podemos modificar esto configurando los valores de abs_tol y rel_tol en distintos de cero, lo que nos permite especificar una cantidad de desviación entre los valores numéricos que se puede tolerar. Representan tolerancia absoluta y tolerancia relativa respectivamente.
- Podemos ver en el ejemplo anterior que DataComPy es una biblioteca realmente poderosa y es extremadamente útil en los casos en que tenemos que generar un informe de comparación de 2 marcos de datos.
Publicación traducida automáticamente
Artículo escrito por preritpathak y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA