La distribución t es un tipo de distribución de probabilidad que surge al muestrear una población distribuida normalmente cuando el tamaño de la muestra es pequeño y se desconoce la desviación estándar de la población. También se llama distribución t de Student. Es aproximadamente una curva de campana, es decir, tiene una distribución aproximadamente normal pero con un pico más bajo y más observaciones cerca de la cola. Esto implica que da una mayor probabilidad a las colas que la distribución normal estándar o la distribución z (la media es 0 y la desviación estándar es 1).
Grados de libertadestá relacionado con el tamaño de la muestra y muestra el número máximo de valores lógicamente independientes que pueden variar libremente en la muestra de datos. Se calcula como n – 1, donde n es el número total de observaciones. Por ejemplo, si tiene 3 observaciones en una muestra, 2 de las cuales son 10,15 y se revela que la media es 15, entonces la tercera observación tiene que ser 20. Entonces, los grados de libertad, en este caso, son 2 (solo dos observaciones pueden variar libremente). Los grados de libertad son importantes para una distribución t, ya que caracterizan la forma de la curva. Es decir, la varianza en una distribución t se estima en función de los grados de libertad del conjunto de datos. A medida que aumentan los grados de libertad, la distribución t se acercará más a la distribución normal estándar hasta que converjan (casi idénticas). Por lo tanto,
Una prueba t es una prueba de hipótesis estadística utilizada para determinar si existe una diferencia significativa (las diferencias se miden en medias) entre dos grupos y estimar la probabilidad de que esta diferencia exista puramente por casualidad (valor p). En una distribución t, se utiliza una estadística de prueba llamada puntuación t o valor t para describir qué tan lejos está una observación de la media. La puntuación t se utiliza en pruebas t, pruebas de regresión y para calcular intervalos de confianza.
Distribución t de Student en R
Funciones utilizadas:
- Para encontrar el valor de la función de densidad de probabilidad (pdf) de la distribución t de Student dada una variable aleatoria x, use la función dt() en R.
Sintaxis : dt(x, df)
Parámetros:
- x es el vector de cuantiles
- df son los grados de libertad
- La función pt() se usa para obtener la función de distribución acumulativa (CDF) de una distribución t
Sintaxis: pt(q, df, lower.tail = TRUE)
Parámetro:
- q es el vector cuantiles
- df son los grados de libertad
- cola inferior: si es VERDADERO (predeterminado), las probabilidades son P[X ≤ x]; de lo contrario, P[X > x].
- La función qt() se utiliza para obtener la función cuantil o la función de densidad acumulativa inversa de una distribución t.
Sintaxis: qt(p, df, lower.tail = TRUE)
Parámetro:
- p es el vector de probabilidades
- df son los grados de libertad
- cola inferior: si es VERDADERO (predeterminado), las probabilidades son P[X ≤ x]; de lo contrario, P[X > x].
Acercarse
- Establecer grados de libertad
- Para trazar la función de densidad para la distribución t de Student, siga los pasos dados:
- Primero cree un vector de cuantiles en R.
- Luego, use la función dt para encontrar los valores de una distribución t dada una variable aleatoria x y ciertos grados de libertad.
- Con estos valores, trace la función de densidad para la distribución t de Student.
- Ahora, en lugar de la función dt, utilice la función pt para obtener la función de distribución acumulada (CDF) de una distribución t y la función qt para obtener la función cuantil o función de densidad acumulada inversa de una distribución t. En pocas palabras, pt devuelve el área a la izquierda de una variable aleatoria dada q en la distribución t y qt encuentra que la puntuación t es del p -ésimo cuantil de la distribución t.
Ejemplo: Para encontrar un valor de distribución t en x=1, con ciertos grados de libertad, digamos D f = 25,
R
# value of t-distribution pdf at # x = 0 with 25 degrees of freedom dt(x = 1, df = 25)
Producción:
0.237211
Ejemplo:
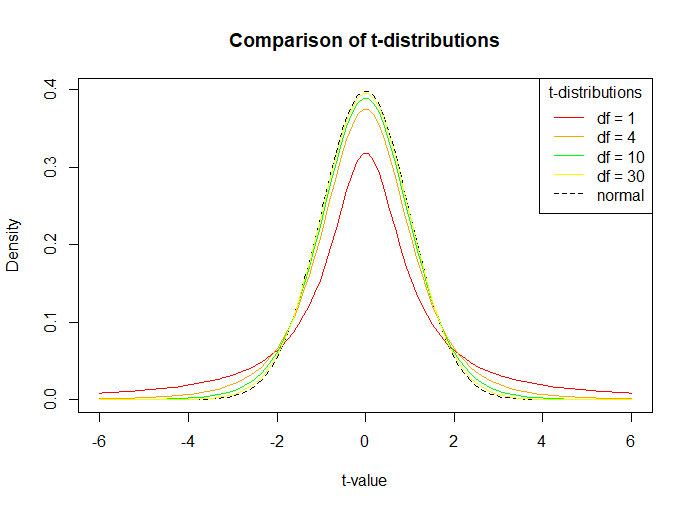
El siguiente código muestra una comparación de funciones de densidad de probabilidad que tienen diferentes grados de libertad. Se observa como se mencionó anteriormente, cuanto mayor es el tamaño de la muestra (grados de libertad crecientes), más cerca está la gráfica de una distribución normal (línea punteada en la figura).
R
# Generate a vector of 100 values between -6 and 6
x <- seq(-6, 6, length = 100)
# Degrees of freedom
df = c(1,4,10,30)
colour = c("red", "orange", "green", "yellow","black")
# Plot a normal distribution
plot(x, dnorm(x), type = "l", lty = 2, xlab = "t-value", ylab = "Density",
main = "Comparison of t-distributions", col = "black")
# Add the t-distributions to the plot
for (i in 1:4){
lines(x, dt(x, df[i]), col = colour[i])
}
# Add a legend
legend("topright", c("df = 1", "df = 4", "df = 10", "df = 30", "normal"),
col = colour, title = "t-distributions", lty = c(1,1,1,1,2))
Producción:
Ejemplo: encontrar el valor p y el intervalo de confianza con la distribución t
R
# area to the right of a t-statistic with # value of 2.1 and 14 degrees of freedom pt(q = 2.1, df = 14, lower.tail = FALSE)
Producción:
0.02716657
Esencialmente, encontramos el valor p unilateral, P (t> 2.1) como 2.7%. Supongamos ahora que queremos construir un intervalo de confianza del 95% de dos colas. Para ello, busque la puntuación t o el valor t para un 95 % de confianza utilizando la función qt o la distribución cuantil.
Ejemplo:
R
# value in each tail is 2.5% as confidence is 95% # find 2.5th percentile of t-distribution with # 14 degrees of freedom qt(p = 0.025, df = 14, lower.tail = TRUE)
Producción:
-2.144787
Por lo tanto, se utilizará un valor t de 2,14 como valor crítico para un intervalo de confianza del 95 %.
Publicación traducida automáticamente
Artículo escrito por akshisaxena y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA