Requisitos previos: LTSM , GRU
En este artículo, analizaremos un conjunto de herramientas de aprendizaje profundo utilizado para mejorar el tiempo de capacitación de los modelos actuales de reconocimiento de voz , entre otras cosas, como traducción de lenguaje natural , síntesis de voz y modelado de lenguaje . Los modelos creados con este kit de herramientas brindan un rendimiento de vanguardia con un tiempo de entrenamiento de 1,5 a 3 veces más rápido.
AbrirSeq2Seq
OpenSeq2Seq es un conjunto de herramientas basado en TensorFlow de código abierto que ofrece capacitación de precisión mixta y varias GPU que reduce significativamente el tiempo de capacitación de varios modelos de NLP. Por ejemplo,
1. Natural Language Translation: GNMT, Transformer, ConvS2S 2. Speech Recognition: Wave2Letter, DeepSpeech2 3. Speech Synthesis: Tacotron 2
Utiliza el paradigma Sequence to Sequence para construir y entrenar modelos para realizar una variedad de tareas, como traducción automática, resumen de texto.
Modelo de secuencia a secuencia
El modelo consta de 3 partes: codificador , vector codificador y decodificador .
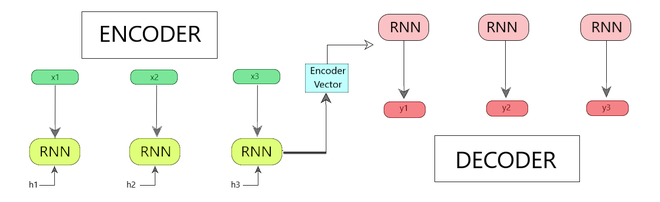
Fig. 1: Secuencia de codificador-decodificador a modelo de secuencia
- codificador
- En esto, se utilizan varias unidades recurrentes como LTSM (memoria a largo plazo) y GRU (unidad recurrente cerrada) para mejorar el rendimiento.
- Cada una de estas unidades recurrentes acepta un solo elemento de la secuencia de entrada, recopila la información de ese elemento y la propaga hacia adelante.
- La secuencia de entrada es una colección de todas las palabras de la pregunta.
- Los estados ocultos (h 1 , h 2 …, h n ) se calculan utilizando la siguiente fórmula. [Ecuación 1]
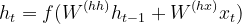
ecuación 1
where, ht = hidden state ht-1 = previous hidden state W(hh) = weights attached to the previous hidden state. (ht-1) xt = input vector W(hx) = weights attached to the input vector.
- Vector codificador
- El estado oculto final se calcula utilizando la ecuación 1 de la parte del codificador del modelo.
- El vector del codificador recopila la información de todos los elementos de entrada para ayudar al decodificador a realizar predicciones precisas.
- Sirve como el estado oculto inicial de la parte del decodificador del modelo.
- Descifrador
- En este, varias unidades recurrentes están presentes donde cada una predice una salida y t en un paso de tiempo t.
- Cada unidad recurrente acepta un estado oculto de la unidad anterior y produce una salida además de su propio estado oculto.
- Los estados ocultos (h 1 , h 2 …, h n ) se calculan utilizando la siguiente fórmula. [Ecuación 2]
ecuación 2
Por ejemplo, la figura 1. Muestra el modelo de secuencia a secuencia para un sistema de diálogo.
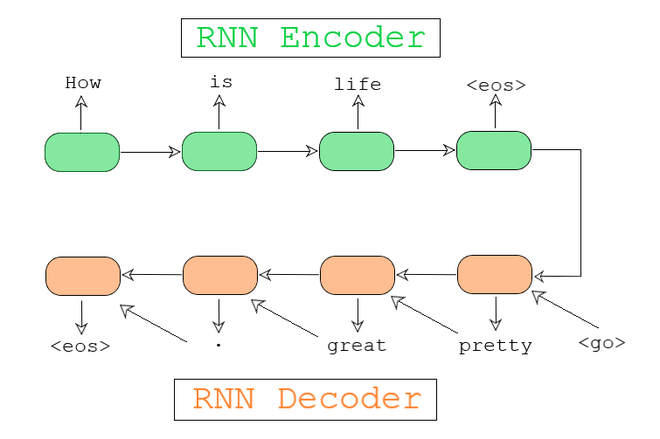
Fig. 2: Modelo de secuencia a secuencia para un sistema de diálogo
Cada modelo Sequence to Sequence tiene un codificador y un decodificador. Por ejemplo,
| S-no. | Tarea | codificador | Descifrador |
|---|---|---|---|
| 1. | Análisis de los sentimientos | RNN | Lineal SoftMax |
| 2. | Clasificación de imágenes | CNN | Lineal SoftMax |
Diseño y Arquitectura
El kit de herramientas OpenSeq2Seq proporciona varias clases de las que el usuario puede heredar sus propios módulos. El modelo se divide en 5 partes diferentes:
- Capa de datos
- codificador
- Descifrador
- Función de pérdida
- Hiperparámetros
- Optimizador
- Tasa de aprendizaje
- Abandonar
- regularización
- Tamaño del lote, etc.
For example, an OpenSeq2Seq model for Machine Translation would look like :
Encoder - GNMTLikeEncoderWithEmbedding
Decoder - RNNDecoderWithAttention
Loss Function - BasicSequenceLoss
Hyperparameters -
Learning Rate = 0.0008
Optimizer = 'Adam'
Regularization = 'weight decay'
Batch_Size = 32
Entrenamiento de precisión mixta:
Cuando se usa float16 para entrenar grandes modelos de redes neuronales, a veces es necesario aplicar ciertas técnicas algorítmicas y mantener algunas salidas en float32. (de ahí el nombre, precisión mixta).
Soporte de precisión mixta [usando algoritmo]
El modelo utiliza TensorFlow como base, por lo que tiene tensor-cores que ofrecen el rendimiento necesario para entrenar grandes redes neuronales. Permiten realizar la multiplicación array-array de 2 formas:
- Punto flotante de precisión simple (FP-32)
- Un formato de punto flotante de precisión simple es un formato de número de computadora que ocupa 32 bits (cuatro bytes en las computadoras modernas) en la memoria de la computadora.
- En un punto flotante de 32 bits, se reservan 8 bits para el exponente («magnitud») y 23 bits para la mantisa («precisión»).
- Punto flotante de media precisión (FP-16)
- Una precisión media es un formato binario de coma flotante, es un formato de número de computadora que ocupa 16 bits (dos bytes en las computadoras modernas) en la memoria de la computadora.
Anteriormente, cuando se entrenaba una red neuronal, se usaba FP-32 (como se muestra en la Fig. 2) para representar los pesos en la red por varias razones, como:
- Mayor precisión: los flotantes de 32 bits tienen suficiente precisión para que podamos distinguir números de diferentes magnitudes entre sí.
- Amplio rango: los puntos flotantes de 32 bits tienen suficiente rango para representar números de magnitud tanto más pequeña (10^-45) como más grande (10^38) de lo que se requiere para la mayoría de las aplicaciones.
- Compatible: todo el hardware (GPU, CPU) y las API admiten instrucciones de punto flotante de 32 bits de manera bastante eficiente.

Fig. 3: Representación del FP-32
Pero, más tarde, se descubrió que para modelos de aprendizaje profundo máximo, no se requiere tanta magnitud y precisión. Entonces, NVIDIA creó hardware que admitía instrucciones de punto flotante de 16 bits y observó que la mayoría de los pesos y gradientes tienden a caer dentro del rango representable de 16 bits.
Por lo tanto, en el modelo OpenSeq2Seq se ha utilizado FP-16 . Al usar esto, evitamos de manera efectiva que se desperdicien todos esos bits adicionales. Con FP-16, reducimos el número de bits a la mitad, reduciendo el exponente de 8 bits a 5 y la mantisa de 23 bits a 10. (Como se muestra en la Fig. 3)
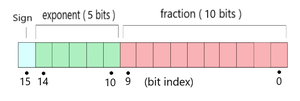
Fig. 4: Representación del FP-16
Riesgos de usar FP-16 :
1. Subdesbordamiento: intentar representar números tan pequeños que se limitan a cero.
2. Desbordamiento: números tan grandes (fuera del rango de FP-16) que se convierten en NaN, no en un número.
- Con underflow, nuestra red nunca aprende nada.
- Con desbordamiento, aprende basura.
- Para el Entrenamiento de Precisión Mixta, seguimos un algoritmo que involucra los siguientes 2 pasos:
Step 1 - Maintain float32 master copy of weights for weights update while using the float16
weights for forward and back propagation.
Step 2 - Apply loss scaling while computing gradients to prevent underflow during backpropagation.
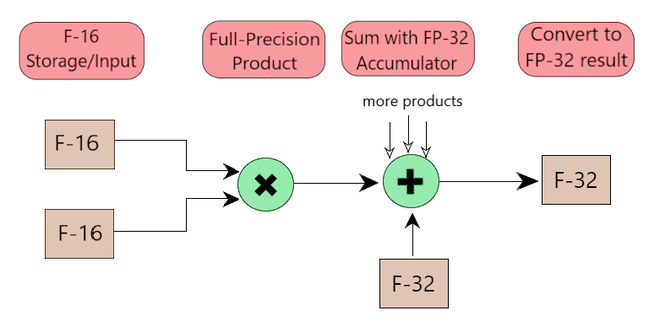
Fig 5: Operaciones aritméticas en FP16 y acumuladas en FP32
El entrenamiento de precisión mixto del modelo OpenSeq2Seq implica tres cosas:
- Optimizador de precisión mixta
- Regularizador de Precisión Mixto
- Escalado automático de pérdidas
1. Optimizador de precisión mixta
El modelo tiene todas las variables y gradientes como FP-16 por defecto, como se muestra en la Fig. 6. En este proceso se llevan a cabo los siguientes pasos:
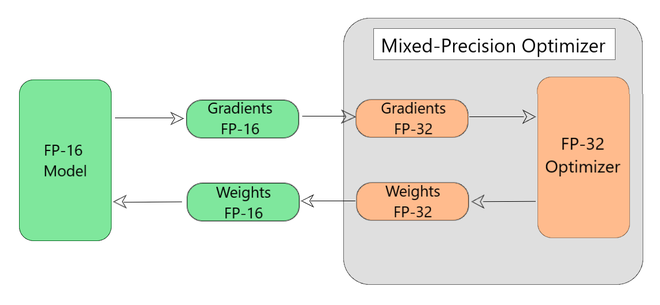
Fig. 6: Envoltura de precisión mixta alrededor de los optimizadores de TensorFlow
Working of Mixed Precision Wrapper (Step by Step)
Each Iteration
{
Step 1 - The wrapper automatically converts FP-16 gradients and FP-32 and feed them
to the tensorflow optimizer.
Step 2 - The tensorflow optimizer then updates the copy of weights in FP-32.
Step 3 - The updated FP-32 weights are then converted back to FP-16.
Step 4 - The FP-16 weights are then used by the model for the next iteration.
}
2. Regularización de Precisión Mixta
Como se discutió anteriormente, los riesgos involucrados con el uso de F-16 como desbordamiento/desbordamiento numérico. La regularización de precisión mixta asegura que tales casos no ocurran durante el entrenamiento. Entonces, para superar tales problemas, hacemos los siguientes pasos:
Step 1 - All regularizers should be defined during variable creation.
Step 2 - The regularizer function should be wrapped with the 'Mixed Precision Wrapper'. This takes care of 2 things:
2.1 - Adds the regularized variables to a tensorflow collection.
2.2 - Disables the underlying regularization function for FP-16 copy.
Step 3 - This collection is then retrieved by Mixed Precision Optimizer Wrapper.
Step 4 - The corresponding functions obtained from the MPO wrapper will be applied to the FP-32 copy
of the weights ensuring that their gradients always stay in full precision.
3. Escalado automático de pérdidas
El modelo OpenSeq2Seq implica escalado automático de pérdidas. Por lo tanto, el usuario no tiene que seleccionar el valor de pérdida manualmente. El optimizador analiza los gradientes después de cada iteración y actualiza el valor de pérdida para la próxima iteración.
Modelos involucrados
OpenSeq2Seq actualmente ofrece una implementación completa de una variedad de modelos:
- Máquina traductora
- Reconocimiento de voz
- Síntesis de voz
- Análisis de los sentimientos
- Clasificación de imágenes
OpenSeq2Seq presenta una variedad de modelos para modelado de lenguaje, traducción automática, síntesis de voz, reconocimiento de voz, análisis de sentimientos y más por venir. Su objetivo es ofrecer una rica biblioteca de codificadores y decodificadores de uso común. Esta fue una descripción general básica del modelo OpenSeq2Seq que cubre la intuición, la arquitectura y los conceptos involucrados. Para cualquier duda/consulta, comenta abajo.
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA