La codificación Huffman es uno de los métodos de compresión básicos, que ha demostrado ser útil en los estándares de compresión de imágenes y videos. Al aplicar la técnica de codificación de Huffman en una imagen, los símbolos de origen pueden ser intensidades de píxeles de la imagen o la salida de una función de mapeo de intensidad.
Prerrequisitos: Codificación Huffman | Manejo de archivos
El primer paso de la técnica de codificación de Huffman es reducir la imagen de entrada a un histograma ordenado, donde la probabilidad de ocurrencia de un cierto valor de intensidad de píxel es como
prob_pixel = numpix/totalnum
donde numpix es el número de aparición de un píxel con un determinado valor de intensidad y totalnum es el número total de píxeles en la imagen de entrada.
Tomemos una imagen de 8 X 8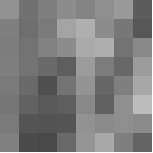
Los valores de intensidad de píxel son: ![]()
Esta imagen contiene 46 valores de intensidad de píxel distintos, por lo tanto, tendremos 46 palabras de código Huffman únicas.
Es evidente que no todos los valores de intensidad de píxel pueden estar presentes en la imagen y, por lo tanto, no tendrán una probabilidad de ocurrencia distinta de cero.
A partir de aquí, los valores de intensidad de píxel en la imagen de entrada se abordarán como Nodes hoja.
Ahora, hay 2 pasos esenciales para construir un árbol de Huffman:
- Construye un árbol de Huffman:
- Combine los dos Nodes hoja de menor probabilidad en un nuevo Node.
- Reemplace los dos Nodes hoja por el nuevo Node y ordene los Nodes de acuerdo con los nuevos valores de probabilidad.
- Continúe con los pasos (a) y (b) hasta que obtengamos un solo Node con un valor de probabilidad de 1.0. Llamaremos a este Node como raíz.
- Retroceda desde la raíz, asignando ‘0’ o ‘1’ a cada Node intermedio, hasta llegar a los Nodes hoja
En este ejemplo, asignaremos ‘0’ al Node secundario izquierdo y ‘1’ al derecho.
Ahora, veamos la implementación:
Paso 1:
lea la imagen en una array 2D ( imagen )
Si la imagen está en formato .bmp , entonces la imagen se puede leer en la array 2D, utilizando este código proporcionado en este enlace aquí .
int i, j;
char filename[] = "Input_Image.bmp";
int data = 0, offset, bpp = 0, width, height;
long bmpsize = 0, bmpdataoff = 0;
int** image;
int temp = 0;
// Reading the BMP File
FILE* image_file;
image_file = fopen(filename, "rb");
if (image_file == NULL)
{
printf("Error Opening File!!");
exit(1);
}
else
{
// Set file position of the
// stream to the beginning
// Contains file signature
// or ID "BM"
offset = 0;
// Set offset to 2, which
// contains size of BMP File
offset = 2;
fseek(image_file, offset, SEEK_SET);
// Getting size of BMP File
fread(&bmpsize, 4, 1, image_file);
// Getting offset where the
// pixel array starts
// Since the information
// is at offset 10 from
// the start, as given
// in BMP Header
offset = 10;
fseek(image_file, offset, SEEK_SET);
// Bitmap data offset
fread(&bmpdataoff, 4, 1, image_file);
// Getting height and width of the image
// Width is stored at offset 18 and height
// at offset 22, each of 4 bytes
fseek(image_file, 18, SEEK_SET);
fread(&width, 4, 1, image_file);
fread(&height, 4, 1, image_file);
// Number of bits per pixel
fseek(image_file, 2, SEEK_CUR);
fread(&bpp, 2, 1, image_file);
// Setting offset to start of pixel data
fseek(image_file, bmpdataoff, SEEK_SET);
// Creating Image array
image = (int**)malloc(height * sizeof(int*));
for (i = 0; i < height; i++)
{
image[i] = (int*)malloc(width * sizeof(int));
}
// int image[height][width]
// can also be done
// Number of bytes in the
// Image pixel array
int numbytes = (bmpsize - bmpdataoff) / 3;
// Reading the BMP File
// into Image Array
for (i = 0; i < height; i++)
{
for (j = 0; j < width; j++)
{
fread(&temp, 3, 1, image_file);
// the Image is a
// 24-bit BMP Image
temp = temp & 0x0000FF;
image[i][j] = temp;
}
}
}
Cree un histograma de los valores de intensidad de píxeles presentes en la imagen
// Creating the Histogram int hist[256]; for (i = 0; i < 256; i++) hist[i] = 0; for (i = 0; i < height; i++) for (j = 0; j < width; j++) hist[image[i][j]] += 1;
Encuentre el número de valores de intensidad de píxel que tienen una probabilidad de ocurrencia distinta de cero
. Dado que los valores de intensidad de píxel varían de 0 a 255, y es posible que no todos los valores de intensidad de píxel estén presentes en la imagen (como se desprende del histograma y también de la array de imagen). ) y, por lo tanto, no tendrá una probabilidad de ocurrencia distinta de cero. También otro propósito de este paso es que la cantidad de valores de intensidad de píxeles que tienen valores de probabilidad distintos de cero nos dará la cantidad de Nodes de hoja en la imagen.
// Finding number of
// non-zero occurrences
int nodes = 0;
for (i = 0; i < 256; i++)
{
if (hist[i] != 0)
nodes += 1;
}
Cálculo de la longitud máxima de las palabras de código de Huffman
Como lo muestran YSAbu-Mostafa y RJMcEliece en su artículo «Longitudes máximas de palabra de código en los códigos de Huffman» , que, si  , entonces en cualquier código de prefijo eficiente para una fuente cuya probabilidad mínima es p, la palabra de código más larga la longitud es como máximo K & Si
, entonces en cualquier código de prefijo eficiente para una fuente cuya probabilidad mínima es p, la palabra de código más larga la longitud es como máximo K & Si  , existe una fuente cuya probabilidad más pequeña es p, y que tiene un código de Huffman cuya palabra más larga tiene una longitud K. Si
, existe una fuente cuya probabilidad más pequeña es p, y que tiene un código de Huffman cuya palabra más larga tiene una longitud K. Si  , existe una fuente para la cual cada código óptimo tiene una palabra más larga de longitud K
, existe una fuente para la cual cada código óptimo tiene una palabra más larga de longitud K
Aquí, está  el
el  número de Fibonacci.
número de Fibonacci.
Gallager [1] noted that every Huffman tree is efficient, but in fact it is easy to see more generally that every optimal tree is efficient
La serie de Fibonacci es: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
En nuestro ejemplo, la probabilidad más baja (p) es 0.015625
Por eso,
1/p = 64
For K = 9, F(K+2) = F(11) = 55 F(K+3) = F(12) = 89
Por lo tanto,
1/F(K+3) < p < 1/F(K+2) Hence optimal length of code is K=9
// Calculating max length // of Huffman code word i = 0; while ((1 / p) < fib(i)) i++; int maxcodelen = i - 3;
// Function for getting Fibonacci
// numbers defined outside main
int fib(int n)
{
if (n <= 1)
return n;
return fib(n - 1) + fib(n - 2);
}
Paso 2
Defina una estructura que contendrá los valores de intensidad de píxeles ( pix ), sus probabilidades correspondientes ( frecuencia ), el puntero a los Nodes secundarios izquierdo ( *izquierda ) y derecho( *derecha ) y también la array de strings para la palabra clave de Huffman ( código ).
Estas estructuras se definen dentro de main() , para usar la longitud máxima del código ( maxcodelen ) para declarar el campo de array de código de la estructura pixfreq
// Defining Structures pixfreq
struct pixfreq
{
int pix;
float freq;
struct pixfreq *left, *right;
char code[maxcodelen];
};
Paso 3
Defina otra Struct que contendrá los valores de intensidad de píxeles ( pix ), sus probabilidades correspondientes ( freq ) y un campo adicional, que se utilizará para almacenar la posición de los nuevos Nodes generados ( arrloc ).
// Defining Structures huffcode
struct huffcode
{
int pix, arrloc;
float freq;
};
Paso 4
Declarar una array de estructuras . Cada elemento de la array corresponde a un Node en el árbol de Huffman.
// Declaring structs struct pixfreq* pix_freq; struct huffcode* huffcodes;
¿Por qué usar dos arrays de estructura?
Inicialmente, la array struct pix_freq , así como la array struct huffcodes solo contendrán la información de todos los Nodes hoja en el Huffman Tree.
La array struct pix_freq se usará para almacenar todos los Nodes del árbol de Huffman y la array huffcodes se usará como el árbol actualizado (y ordenado).
Recuerde que solo se ordenarán los huffcodes en cada iteración, y no pix_freq
Los nuevos Nodes creados al combinar dos Nodes de frecuencia más baja, en cada iteración, se agregarán al final de la array pix_freq y también a la array huffcodes .
Pero la array huffcodes se ordenará nuevamente de acuerdo con la probabilidad de ocurrencia, después de agregarle el nuevo Node.
La posición del nuevo Node en la array pix_freq se almacenará en el campo arrloc de la estructura huffcode .
El campo arrloc se utilizará al asignar el puntero al elemento secundario izquierdo y derecho de un nuevo Node.
Paso 4 continuación…
Ahora, si hay un número N de Nodes hoja, el número total de Nodes en todo el árbol de Huffman será igual a 2N-1
Y después de combinar dos Nodes y reemplazarlos por el nuevo Node principal , la cantidad de Nodes disminuye en 1 en cada iteración. Por lo tanto, es suficiente tener una longitud de Nodes para la array huffcodes , que se usará como los Nodes de Huffman actualizados y ordenados.
int totalnodes = 2 * nodes - 1; pix_freq = (struct pixfreq*)malloc(sizeof(struct pixfreq) * totalnodes); huffcodes = (struct huffcode*)malloc(sizeof(struct huffcode) * nodes);
Paso 5
Inicialice las dos arrays pix_freq y huffcodes con información de los Nodes hoja.
j = 0;
int totpix = height * width;
float tempprob;
for (i = 0; i < 256; i++)
{
if (hist[i] != 0)
{
// pixel intensity value
huffcodes[j].pix = i;
pix_freq[j].pix = i;
// location of the node
// in the pix_freq array
huffcodes[j].arrloc = j;
// probability of occurrence
tempprob = (float)hist[i] / (float)totpix;
pix_freq[j].freq = tempprob;
huffcodes[j].freq = tempprob;
// Declaring the child of
// leaf node as NULL pointer
pix_freq[j].left = NULL;
pix_freq[j].right = NULL;
// initializing the code
// word as end of line
pix_freq[j].code[0] = '\0';
j++;
}
}
Paso 6
Ordenar la array de huffcodes según la probabilidad de ocurrencia de los valores de intensidad de píxel
Tenga en cuenta que es necesario ordenar la array huffcodes , pero no la array pix_freq , ya que estamos almacenando la ubicación de los valores de píxel en el campo arrloc de la array huffcodes .
// Sorting the histogram
struct huffcode temphuff;
// Sorting w.r.t probability
// of occurrence
for (i = 0; i < nodes; i++)
{
for (j = i + 1; j < nodes; j++)
{
if (huffcodes[i].freq < huffcodes[j].freq)
{
temphuff = huffcodes[i];
huffcodes[i] = huffcodes[j];
huffcodes[j] = temphuff;
}
}
}
Paso 7
Construyendo el árbol de Huffman
Comenzamos combinando los dos Nodes con las probabilidades de ocurrencia más bajas y luego reemplazando los dos Nodes por el nuevo Node. Este proceso continúa hasta que tenemos un Node raíz . El primer Node principal formado se almacenará en los Nodes de índice en la array pix_freq y los Nodes principales posteriores obtenidos se almacenarán en valores más altos de índice.
// Building Huffman Tree
float sumprob;
int sumpix;
int n = 0, k = 0;
int nextnode = nodes;
// Since total number of
// nodes in Huffman Tree
// is 2*nodes-1
while (n < nodes - 1)
{
// Adding the lowest
// two probabilities
sumprob = huffcodes[nodes - n - 1].freq + huffcodes[nodes - n - 2].freq;
sumpix = huffcodes[nodes - n - 1].pix + huffcodes[nodes - n - 2].pix;
// Appending to the pix_freq Array
pix_freq[nextnode].pix = sumpix;
pix_freq[nextnode].freq = sumprob;
pix_freq[nextnode].left = &pix_freq[huffcodes[nodes - n - 2].arrloc];
// arrloc points to the location
// of the child node in the
// pix_freq array
pix_freq[nextnode].right = &pix_freq[huffcodes[nodes - n - 1].arrloc];
pix_freq[nextnode].code[0] = '\0';
// Using sum of the pixel values as
// new representation for the new node
// since unlike strings, we cannot
// concatenate because the pixel values
// are stored as integers. However, if we
// store the pixel values as strings
// we can use the concatenated string as
// a representation of the new node.
i = 0;
// Sorting and Updating the huffcodes
// array simultaneously New position
// of the combined node
while (sumprob <= huffcodes[i].freq)
i++;
// Inserting the new node in
// the huffcodes array
for (k = nnz; k >= 0; k--)
{
if (k == i)
{
huffcodes[k].pix = sumpix;
huffcodes[k].freq = sumprob;
huffcodes[k].arrloc = nextnode;
}
else if (k > i)
// Shifting the nodes below
// the new node by 1
// For inserting the new node
// at the updated position k
huffcodes[k] = huffcodes[k - 1];
}
n += 1;
nextnode += 1;
}
¿Cómo funciona este código?
Veámoslo con un ejemplo:
Inicialmente
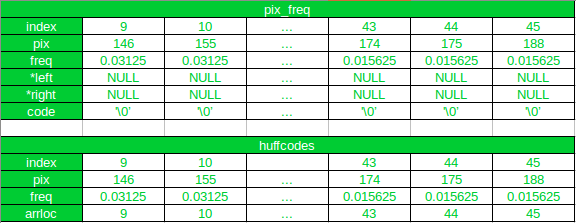
Después de la primera iteración
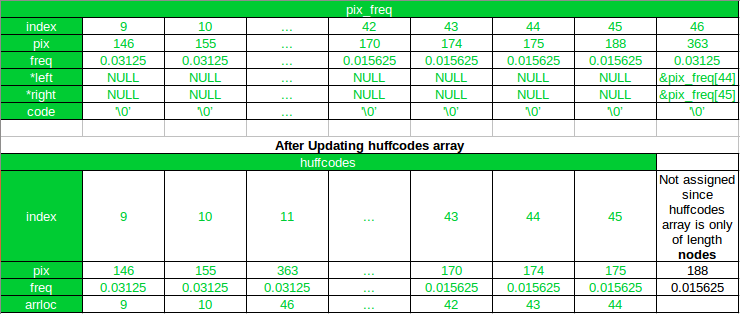
Como puede ver, después de la primera iteración, el nuevo Node se agregó a la array pix_freq y su índice es 46. Y en huffcode, el nuevo Node se agregó en su nueva posición después de la clasificación, y el arrloc apunta al índice. del nuevo Node en la array pix_freq . Además, tenga en cuenta que todos los elementos de la array después del nuevo Node (en el índice 11) en la array huffcodes se han desplazado en 1 y el elemento de la array con el valor de píxel 188 se excluye en la array actualizada.
Ahora, en la próxima (2da) iteración se combinarán 170 y 174, ya que 175 y 188 ya se combinaron.
Índice de los dos Nodes más bajos en términos de los Nodes variables y n es
left_child_index=(nodes-n-2)
y
right_child_index=(nodes-n-1)
En la segunda iteración, el valor de n es 1 (ya que n comienza desde 0).
Para Node con valor 170
left_child_index=46-1-2=43
Para Node con valor 174
right_child_index=46-1-1=44
Por lo tanto, incluso si 175 sigue siendo el último elemento de la array actualizada, se excluirá.
Otra cosa a tener en cuenta en este código es que, si en cualquier iteración posterior, el nuevo Node formado en la primera iteración es el hijo de otro nuevo Node, entonces se puede acceder al puntero del nuevo Node obtenido en la primera iteración usando el arrloc almacenado en la array huffcodes , como se hace en esta línea de código
pix_freq[nextnode].right = &pix_freq[huffcodes[nodes - n - 1].arrloc];
Paso 8
Retroceda desde la raíz hasta los Nodes hoja para asignar palabras de código
Comenzando desde la raíz, asignamos ‘0’ al Node secundario izquierdo y ‘1’ al Node secundario derecho.
Ahora, dado que estábamos agregando los Nodes recién formados a la array pix_freq , se espera que la raíz sea el último elemento de la array en el índice totalnodes-1 .
Por lo tanto, comenzamos desde el último índice e iteramos sobre la array, asignando palabras de código a los Nodes secundarios izquierdo y derecho, hasta llegar al primer Node principal formado en los Nodes de índice . No iteramos sobre los Nodes de hoja ya que esos Nodes tienen punteros NULL como su hijo izquierdo y derecho.
// Assigning Code through backtracking
char left = '0';
char right = '1';
int index;
for (i = totalnodes - 1; i >= nodes; i--) {
if (pix_freq[i].left != NULL) {
strconcat(pix_freq[i].left->code, pix_freq[i].code, left);
}
if (pix_freq[i].right != NULL) {
strconcat(pix_freq[i].right->code, pix_freq[i].code, right);
}
}
void strconcat(char* str, char* parentcode, char add)
{
int i = 0;
while (*(parentcode + i) != '\0') {
*(str + i) = *(parentcode + i);
i++;
}
str[i] = add;
str[i + 1] = '\0';
}
Paso final
Codificar la imagen
// Encode the Image
int pix_val;
// Writing the Huffman encoded
// Image into a text file
FILE* imagehuff = fopen("encoded_image.txt", "wb");
for (r = 0; r < height; r++)
for (c = 0; c < width; c++) {
pix_val = image[r];
for (i = 0; i < nodes; i++)
if (pix_val == pix_freq[i].pix)
fprintf(imagehuff, "%s", pix_freq[i].code);
}
fclose(imagehuff);
// Printing Huffman Codes
printf("Huffmann Codes::\n\n");
printf("pixel values -> Code\n\n");
for (i = 0; i < nodes; i++) {
if (snprintf(NULL, 0, "%d", pix_freq[i].pix) == 2)
printf(" %d -> %s\n", pix_freq[i].pix, pix_freq[i].code);
else
printf(" %d -> %s\n", pix_freq[i].pix, pix_freq[i].code);
}
Otro punto importante a tener en cuenta
Número promedio de bits necesarios para representar cada píxel.
// Calculating Average number of bits float avgbitnum = 0; for (i = 0; i < nodes; i++) avgbitnum += pix_freq[i].freq * codelen(pix_freq[i].code);
La función codelen calcula la longitud de las palabras clave O el número de bits necesarios para representar el píxel.
int codelen(char* code)
{
int l = 0;
while (*(code + l) != '\0')
l++;
return l;
}
Para esta imagen de ejemplo específica
Average number of bits = 5.343750
Los resultados impresos para la imagen de ejemplo
pixel values -> Code
72 -> 011001
75 -> 010100
79 -> 110111
83 -> 011010
84 -> 00100
87 -> 011100
89 -> 010000
93 -> 010111
94 -> 00011
96 -> 101010
98 -> 101110
100 -> 000101
102 -> 0001000
103 -> 0001001
105 -> 110110
106 -> 00110
110 -> 110100
114 -> 110101
115 -> 1100
118 -> 011011
119 -> 011000
122 -> 1110
124 -> 011110
125 -> 011111
127 -> 0000
128 -> 011101
130 -> 010010
131 -> 010011
136 -> 00111
138 -> 010001
139 -> 010110
140 -> 1111
142 -> 00101
143 -> 010101
146 -> 10010
148 -> 101011
149 -> 101000
153 -> 101001
155 -> 10011
163 -> 101111
167 -> 101100
169 -> 101101
170 -> 100010
174 -> 100011
175 -> 100000
188 -> 100001
Imagen codificada:
0111010101000110011101101010001011010000000101111 00010001101000100100100100010010101011001101110111001 00000001100111101010010101100001111000110110111110010 10110001000000010110000001100001100001110011011110000 10011001101111111000100101111100010100011110000111000 01101001110101111100000111101100001110010010110101000 0111101001100101101001010111
Esta imagen codificada tiene una longitud de 342 bits, mientras que el número total de bits en la imagen original es de 512 bits. (64 píxeles cada uno de 8 bits).
Image Compression Code
// C Code for
// Image Compression
#include <stdio.h>
#include <stdlib.h>
// function to calculate word length
int codelen(char* code)
{
int l = 0;
while (*(code + l) != '\0')
l++;
return l;
}
// function to concatenate the words
void strconcat(char* str, char* parentcode, char add)
{
int i = 0;
while (*(parentcode + i) != '\0')
{
*(str + i) = *(parentcode + i);
i++;
}
if (add != '2')
{
str[i] = add;
str[i + 1] = '\0';
}
else
str[i] = '\0';
}
// function to find fibonacci number
int fib(int n)
{
if (n <= 1)
return n;
return fib(n - 1) + fib(n - 2);
}
// Driver code
int main()
{
int i, j;
char filename[] = "Input_Image.bmp";
int data = 0, offset, bpp = 0, width, height;
long bmpsize = 0, bmpdataoff = 0;
int** image;
int temp = 0;
// Reading the BMP File
FILE* image_file;
image_file = fopen(filename, "rb");
if (image_file == NULL)
{
printf("Error Opening File!!");
exit(1);
}
else
{
// Set file position of the
// stream to the beginning
// Contains file signature
// or ID "BM"
offset = 0;
// Set offset to 2, which
// contains size of BMP File
offset = 2;
fseek(image_file, offset, SEEK_SET);
// Getting size of BMP File
fread(&bmpsize, 4, 1, image_file);
// Getting offset where the
// pixel array starts
// Since the information is
// at offset 10 from the start,
// as given in BMP Header
offset = 10;
fseek(image_file, offset, SEEK_SET);
// Bitmap data offset
fread(&bmpdataoff, 4, 1, image_file);
// Getting height and width of the image
// Width is stored at offset 18 and
// height at offset 22, each of 4 bytes
fseek(image_file, 18, SEEK_SET);
fread(&width, 4, 1, image_file);
fread(&height, 4, 1, image_file);
// Number of bits per pixel
fseek(image_file, 2, SEEK_CUR);
fread(&bpp, 2, 1, image_file);
// Setting offset to start of pixel data
fseek(image_file, bmpdataoff, SEEK_SET);
// Creating Image array
image = (int**)malloc(height * sizeof(int*));
for (i = 0; i < height; i++)
{
image[i] = (int*)malloc(width * sizeof(int));
}
// int image[height][width]
// can also be done
// Number of bytes in
// the Image pixel array
int numbytes = (bmpsize - bmpdataoff) / 3;
// Reading the BMP File
// into Image Array
for (i = 0; i < height; i++)
{
for (j = 0; j < width; j++)
{
fread(&temp, 3, 1, image_file);
// the Image is a
// 24-bit BMP Image
temp = temp & 0x0000FF;
image[i][j] = temp;
}
}
}
// Finding the probability
// of occurrence
int hist[256];
for (i = 0; i < 256; i++)
hist[i] = 0;
for (i = 0; i < height; i++)
for (j = 0; j < width; j++)
hist[image[i][j]] += 1;
// Finding number of
// non-zero occurrences
int nodes = 0;
for (i = 0; i < 256; i++)
if (hist[i] != 0)
nodes += 1;
// Calculating minimum probability
float p = 1.0, ptemp;
for (i = 0; i < 256; i++)
{
ptemp = (hist[i] / (float)(height * width));
if (ptemp > 0 && ptemp <= p)
p = ptemp;
}
// Calculating max length
// of code word
i = 0;
while ((1 / p) > fib(i))
i++;
int maxcodelen = i - 3;
// Defining Structures pixfreq
struct pixfreq
{
int pix, larrloc, rarrloc;
float freq;
struct pixfreq *left, *right;
char code[maxcodelen];
};
// Defining Structures
// huffcode
struct huffcode
{
int pix, arrloc;
float freq;
};
// Declaring structs
struct pixfreq* pix_freq;
struct huffcode* huffcodes;
int totalnodes = 2 * nodes - 1;
pix_freq = (struct pixfreq*)malloc(sizeof(struct pixfreq) * totalnodes);
huffcodes = (struct huffcode*)malloc(sizeof(struct huffcode) * nodes);
// Initializing
j = 0;
int totpix = height * width;
float tempprob;
for (i = 0; i < 256; i++)
{
if (hist[i] != 0)
{
// pixel intensity value
huffcodes[j].pix = i;
pix_freq[j].pix = i;
// location of the node
// in the pix_freq array
huffcodes[j].arrloc = j;
// probability of occurrence
tempprob = (float)hist[i] / (float)totpix;
pix_freq[j].freq = tempprob;
huffcodes[j].freq = tempprob;
// Declaring the child of leaf
// node as NULL pointer
pix_freq[j].left = NULL;
pix_freq[j].right = NULL;
// initializing the code
// word as end of line
pix_freq[j].code[0] = '\0';
j++;
}
}
// Sorting the histogram
struct huffcode temphuff;
// Sorting w.r.t probability
// of occurrence
for (i = 0; i < nodes; i++)
{
for (j = i + 1; j < nodes; j++)
{
if (huffcodes[i].freq < huffcodes[j].freq)
{
temphuff = huffcodes[i];
huffcodes[i] = huffcodes[j];
huffcodes[j] = temphuff;
}
}
}
// Building Huffman Tree
float sumprob;
int sumpix;
int n = 0, k = 0;
int nextnode = nodes;
// Since total number of
// nodes in Huffman Tree
// is 2*nodes-1
while (n < nodes - 1)
{
// Adding the lowest two probabilities
sumprob = huffcodes[nodes - n - 1].freq + huffcodes[nodes - n - 2].freq;
sumpix = huffcodes[nodes - n - 1].pix + huffcodes[nodes - n - 2].pix;
// Appending to the pix_freq Array
pix_freq[nextnode].pix = sumpix;
pix_freq[nextnode].freq = sumprob;
pix_freq[nextnode].left = &pix_freq[huffcodes[nodes - n - 2].arrloc];
pix_freq[nextnode].right = &pix_freq[huffcodes[nodes - n - 1].arrloc];
pix_freq[nextnode].code[0] = '\0';
i = 0;
// Sorting and Updating the
// huffcodes array simultaneously
// New position of the combined node
while (sumprob <= huffcodes[i].freq)
i++;
// Inserting the new node
// in the huffcodes array
for (k = nodes; k >= 0; k--)
{
if (k == i)
{
huffcodes[k].pix = sumpix;
huffcodes[k].freq = sumprob;
huffcodes[k].arrloc = nextnode;
}
else if (k > i)
// Shifting the nodes below
// the new node by 1
// For inserting the new node
// at the updated position k
huffcodes[k] = huffcodes[k - 1];
}
n += 1;
nextnode += 1;
}
// Assigning Code through
// backtracking
char left = '0';
char right = '1';
int index;
for (i = totalnodes - 1; i >= nodes; i--)
{
if (pix_freq[i].left != NULL)
strconcat(pix_freq[i].left->code, pix_freq[i].code, left);
if (pix_freq[i].right != NULL)
strconcat(pix_freq[i].right->code, pix_freq[i].code, right);
}
// Encode the Image
int pix_val;
int l;
// Writing the Huffman encoded
// Image into a text file
FILE* imagehuff = fopen("encoded_image.txt", "wb");
for (i = 0; i < height; i++)
for (j = 0; j < width; j++)
{
pix_val = image[i][j];
for (l = 0; l < nodes; l++)
if (pix_val == pix_freq[l].pix)
fprintf(imagehuff, "%s", pix_freq[l].code);
}
// Printing Huffman Codes
printf("Huffmann Codes::\n\n");
printf("pixel values -> Code\n\n");
for (i = 0; i < nodes; i++) {
if (snprintf(NULL, 0, "%d", pix_freq[i].pix) == 2)
printf(" %d -> %s\n", pix_freq[i].pix, pix_freq[i].code);
else
printf(" %d -> %s\n", pix_freq[i].pix, pix_freq[i].code);
}
// Calculating Average Bit Length
float avgbitnum = 0;
for (i = 0; i < nodes; i++)
avgbitnum += pix_freq[i].freq * codelen(pix_freq[i].code);
printf("Average number of bits:: %f", avgbitnum);
}
¿Escribir código en un comentario? Utilice ide.geeksforgeeks.org , genere un enlace y compártalo aquí.
Publicación traducida automáticamente
Artículo escrito por SiladittyaManna y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA