Fog Computing es el término acuñado por Cisco que se refiere a extender la computación en la nube a un extremo de la red de la empresa. Por ello, también se le conoce como Edge Computing o Fogging. Facilita la operación de servicios informáticos, de almacenamiento y de redes entre dispositivos finales y centros de datos informáticos.
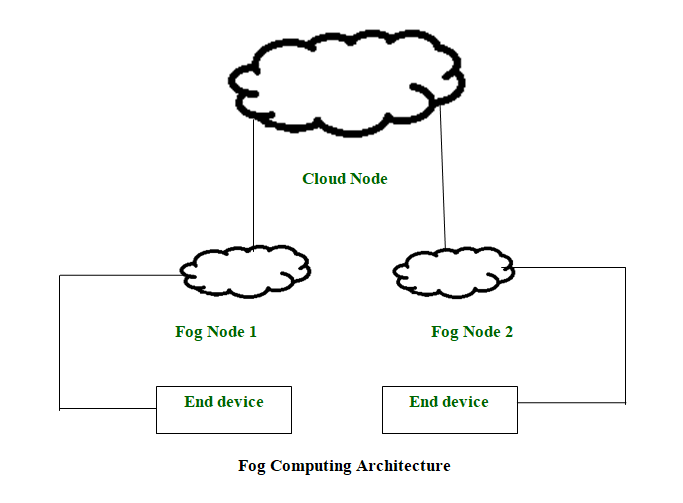
- Los dispositivos que componen la infraestructura de niebla se conocen como Nodes de niebla.
- En la computación en la niebla, todas las capacidades de almacenamiento, las capacidades de computación, los datos y las aplicaciones se colocan entre la nube y el host físico.
- Todas estas funcionalidades se colocan más hacia el anfitrión. Esto hace que el procesamiento sea más rápido, ya que se realiza casi en el lugar donde se crean los datos.
- Mejora la eficiencia del sistema y también se utiliza para garantizar una mayor seguridad.
Historia de la computación en la niebla
El término computación en la niebla fue acuñado por Cisco en enero de 2014. Esto se debió a que la niebla se refiere a las nubes que están cerca del suelo de la misma manera que la computación en la niebla se relaciona con los Nodes que están presentes cerca de los Nodes en algún lugar del entre el host y la nube. Estaba destinado a acercar las capacidades computacionales del sistema a la máquina host. Después de que esto ganara un poco de popularidad, IBM, en 2015, acuñó un término similar llamado “Edge Computing”.
¿Cuándo usar la computación en la niebla?
Fog Computing se puede utilizar en los siguientes escenarios:
- Se utiliza cuando solo se requieren datos seleccionados para enviar a la nube. Estos datos seleccionados se eligen para el almacenamiento a largo plazo y el host accede con menos frecuencia.
- Se utiliza cuando los datos deben analizarse en una fracción de segundos, es decir, la latencia debe ser baja.
- Se utiliza cuando es necesario proporcionar una gran cantidad de servicios en un área grande en diferentes ubicaciones geográficas.
- Los dispositivos que están sujetos a cálculos y procesamientos rigurosos deben usar computación de niebla.
- Los ejemplos del mundo real en los que se utiliza la computación en la niebla son los dispositivos IoT (p. ej., Car-to-Car Consortium, Europa), dispositivos con sensores, cámaras (IIoT-Internet industrial de las cosas), etc.
Ventajas de la computación en la niebla
- Este enfoque reduce la cantidad de datos que deben enviarse a la nube.
- Dado que se reduce la distancia a recorrer por los datos, se ahorra ancho de banda de red.
- Reduce el tiempo de respuesta del sistema.
- Mejora la seguridad general del sistema ya que los datos residen cerca del host.
- Proporciona una mejor privacidad ya que las industrias pueden realizar análisis de sus datos localmente.
Desventajas de la computación en la niebla
- Puede producirse una congestión entre el host y el Node de niebla debido al aumento del tráfico (flujo de datos pesado).
- El consumo de energía aumenta cuando se coloca otra capa entre el host y la nube.
- La programación de tareas entre el host y los Nodes de niebla junto con los Nodes de niebla y la nube es difícil.
- La gestión de datos se vuelve tediosa ya que, junto con los datos almacenados y computados, la transmisión de datos también implica el cifrado y descifrado, lo que a su vez libera datos.
Aplicaciones de la computación en la niebla
- Se puede utilizar para monitorear y analizar la condición de los pacientes. En caso de emergencia, los médicos pueden ser alertados.
- Se puede usar para el monitoreo ferroviario en tiempo real, ya que para los trenes de alta velocidad queremos la menor latencia posible.
- Se puede utilizar para la optimización de tuberías de gas y petróleo. Genera una gran cantidad de datos y es ineficiente almacenar todos los datos en la nube para su análisis.
Referencias:
https://en.wikipedia.org/wiki/Fog_computing
Publicación traducida automáticamente
Artículo escrito por anukruti16 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA