Usando pandas podemos realizar varias operaciones en archivos CSV, como agregar, actualizar, concatenar, etc. En este artículo, vamos a concatenar dos archivos CSV usando el módulo pandas .
Supongamos que tenemos un archivo .csv llamado Employee.csv que contiene algunos registros y es como se muestra a continuación:

Empleado.csv
Hay otro archivo .csv llamado Updated.csv que contiene nuevos registros, así como algunos registros del archivo Employee.csv pero con información actualizada. El archivo se da a continuación:

Actualizado.csv
Podemos ver que los primeros cinco registros en Updated.csv son nuevos y el resto tiene información actualizada. Por ejemplo, los salarios de Louis y Diane cambian, el email_id de Joe es diferente, etc.
El objetivo de este artículo es agregar nuevos registros y actualizar la información de los registros existentes del archivo Updated.csv en Employee.csv .
Nota: Dos empleados no pueden tener el mismo emp_id .
Enfoque: Siempre que se trata de manipular datos usando python, hacemos uso de Dataframes . Se ha utilizado el siguiente enfoque.
- Lea Employee.csv y cree un marco de datos, por ejemplo, employee_df..
- Del mismo modo, lea Updated.csv y desde un marco de datos, por ejemplo, updated_df .
- Concatene updated_df a employee_df y elimine los duplicados usando emp_id como clave principal.
- Cree un nuevo archivo .csv denominado Updated_Employees.csv que contenga todos los registros antiguos, nuevos y actualizados.
Ejemplo 1:
Python3
#import pandas
import pandas as pd
# read Employee file
employee_df = pd.read_csv('Employee.csv')
# print employee records
print(employee_df)
# read Updated file
updated_df = pd.read_csv('Updated.csv')
# print updated records
print(updated_df)
# form new dataframe by combining both employee_df and updated_df
# concat method appends records of updated_df to employee_df
# drop_duplicates method drop rows having same emp_id keeping
# only the latest insertions
# resets the index to 0
final_dataframe = pd.concat([employee_df, updated_df]).drop_duplicates(
subset='emp_id', keep='last').reset_index(drop=True)
# print old,new and updates records
print(final_dataframe)
# export all records to a new csv file
final_dataframe.to_csv(
'Updated_Employees.csv', index=False)
Producción:

empleado_df

actualizado_df

marco_de_datos_final
A continuación se muestra la imagen de Updated_Employee.csv .

Actualizado_Empleados.csv
Ejemplo:
A continuación se muestran los dos archivos CSV que se van a concatenar:

gfg3.csv

gfg2.csv
Ahora ejecuta el siguiente programa para concatenar los archivos CSV anteriores.
Python3
#import pandas
import pandas as pd
# read Employee file
df1 = pd.read_csv('gfg1.csv')
# print employee records
print('\ngfg1.csv:\n', df1)
# read Updated file
df2 = pd.read_csv('gfg2.csv')
# print updated records
print('\ngfg2.csv:\n', df2)
# form new dataframe by combining both employee_df
# and updated_df concat method appends records of
# updated_df to employee_df drop_duplicates method
# drop rows having same emp_id keeping only the
# latest insertions resets the index to 0
final_df = pd.concat([df1, df2]).drop_duplicates(
subset='ORGANIZATION').reset_index(drop=True)
# print old,new and updates records
print('\ngfg3.csv:\n', final_df)
# export all records to a new csv file
final_df.to_csv(
'gfg3.csv', index=False)
Producción:
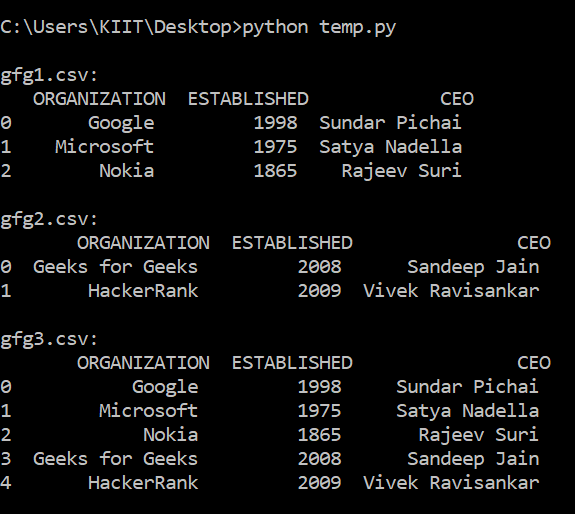
A continuación se muestra la imagen de gfg3.csv:

gfg3.csv
Publicación traducida automáticamente
Artículo escrito por rohanchopra96 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA