El método Pandas Dataframe.groupby() se utiliza para dividir los datos en grupos según algunos criterios. La definición abstracta de agrupación es proporcionar una asignación de etiquetas al nombre del grupo.
Para concatenar strings de varias filas usando Dataframe.groupby() , realice los siguientes pasos:
- Agrupa los datos usando el método Dataframe.groupby() cuyos atributos necesitas concatenar.
- Concatene la string usando la función de combinación y transforme el valor de esa columna usando la instrucción lambda .
Usaremos el archivo CSV que tiene 2 columnas, el contenido del archivo se muestra en la siguiente imagen:
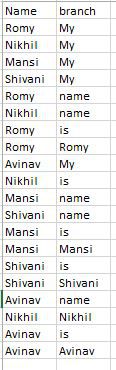
Ejemplo 1: Concatenaremos los datos en la columna de la rama que tiene el mismo nombre.
Python3
# import pandas library
import pandas as pd
# read csv file
df = pd.read_csv("Book2.csv")
# concatenate the string
df['branch'] = df.groupby(['Name'])['branch'].transform(lambda x : ' '.join(x))
# drop duplicate data
df = df.drop_duplicates()
# show the dataframe
print(df)
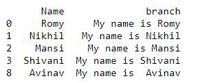
Producción:
Ejemplo 2: También podemos realizar Pandas groupby en varias columnas.
Usaremos el archivo CSV que tiene 3 columnas, el contenido del archivo se muestra en la siguiente imagen:
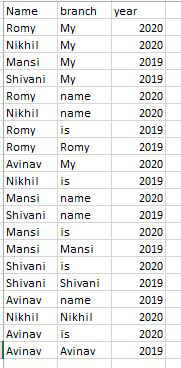
Aplicar groupby en la columna Nombre y año
Python3
# import pandas library
import pandas as pd
# read a csv file
df = pd.read_csv("Book1.csv")
# concatenate the string
df['branch'] = df.groupby(['Name', 'year'])['branch'].transform(
lambda x: ' '.join(x))
# drop duplicate data
df = df.drop_duplicates()
# show the dataframe
df
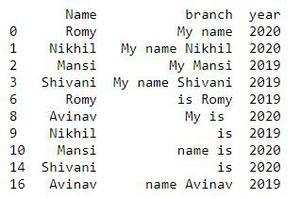
Producción:
Publicación traducida automáticamente
Artículo escrito por romy421kumari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA