PyTorch es una biblioteca de Python desarrollada por Facebook para ejecutar y entrenar modelos de aprendizaje automático y aprendizaje profundo. Entrenar un modelo de aprendizaje profundo requiere que conviertamos los datos al formato que el modelo pueda procesar. PyTorch proporciona la biblioteca torch.utils.data para facilitar la carga de datos con la clase DataSets y Dataloader .
El conjunto de datos es en sí mismo el argumento del constructor de DataLoader que indica un objeto de conjunto de datos desde el que cargar. Hay dos tipos de conjuntos de datos:
- Conjuntos de datos estilo mapa: este conjunto de datos proporciona dos funciones __getitem__( ), __len__( ) que devuelven los índices de los datos de muestra a los que se hace referencia y el número de muestras, respectivamente. En el ejemplo, utilizaremos este tipo de conjunto de datos.
- Conjuntos de datos de estilo iterable: conjuntos de datos que se pueden representar en un conjunto de muestras de datos iterables, para esto usamos la función __iter__().
El cargador de datos, por otro lado, no solo nos permite iterar a través del conjunto de datos en lotes, sino que también nos brinda acceso a funciones integradas para multiprocesamiento (nos permite cargar múltiples lotes de datos en paralelo, en lugar de cargar un lote a la vez), barajar , etc.
Sintaxis:
Cargador de datos (conjunto de datos, tamaño de lote = 1, aleatorio = falso, muestreador = ninguno, muestreador de lotes = ninguno, num_workers = 0, collate_fn = ninguno, pin_memory = falso, drop_last = falso, tiempo de espera = 0, trabajador_init_fn = ninguno, *, prefetch_factor = 2, persistente_trabajadores=Falso)
Conjunto de datos utilizado: corazón
Tratemos un ejemplo para que el concepto quede más claro.
Primero importe todas las bibliotecas requeridas y el conjunto de datos para trabajar. Cargue el conjunto de datos en tensores de antorcha a los que se accede a través del protocolo __getitem__() para obtener el índice del conjunto de datos en particular. Luego desempaquetamos los datos e imprimimos las características y etiquetas correspondientes.
Ejemplo:
Python3
# importing libraries
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
# class to represent dataset
class HeartDataSet():
def __init__(self):
# loading the csv file from the folder path
data1 = np.loadtxt('heart.csv', delimiter=',',
dtype=np.float32, skiprows=1)
# here the 13th column is class label and rest
# are features
self.x = torch.from_numpy(data1[:, :13])
self.y = torch.from_numpy(data1[:, [13]])
self.n_samples = data1.shape[0]
# support indexing such that dataset[i] can
# be used to get i-th sample
def __getitem__(self, index):
return self.x[index], self.y[index]
# we can call len(dataset) to return the size
def __len__(self):
return self.n_samples
dataset = HeartDataSet()
# get the first sample and unpack
first_data = dataset[0]
features, labels = first_data
print(features, labels)
Producción:
tensor([ 63.0000, 1.0000, 3.0000, 145.0000, 233.0000, 1.0000, 0.0000,
150.0000, 0.0000, 2.3000, 0.0000, 0.0000, 1.0000]) tensor([1.])
El cargador de datos de la antorcha toma este conjunto de datos como entrada, junto con otros argumentos para el tamaño del lote, la reproducción aleatoria, etc., calcula nums_samples por lote y luego imprime los objetivos y las etiquetas en lotes.
Ejemplo:
Python3
# Loading whole dataset with DataLoader # shuffle the data, which is good for training dataloader = DataLoader(dataset=dataset, batch_size=4, shuffle=True) # total samples of data and number of iterations performed total_samples = len(dataset) n_iterations = total_samples//4 print(total_samples, n_iterations) for i, (targets, labels) in enumerate(dataloader): print(targets, labels)
Producción:

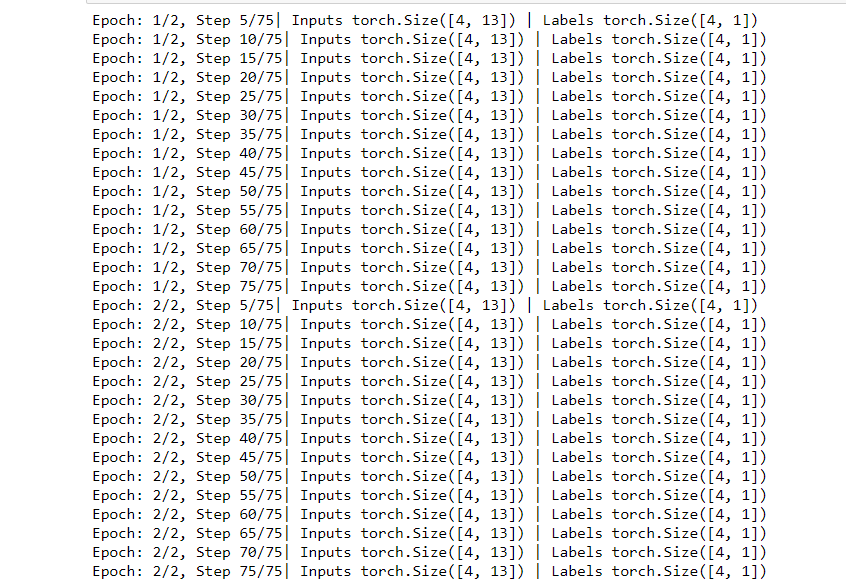
Ahora entrenamos los datos recorriendo primero la época y luego las muestras, después de eso imprimimos el número de épocas, el tensor de entrada y el tensor de etiquetas con cada iteración.
Ejemplo:
Python3
num_epochs = 2
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(dataloader):
# here: 303 samples, batch_size = 4, n_iters=303/4=75 iterations
# Run our training process
if (i+1) % 5 == 0:
print(f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations}|\
Inputs {inputs.shape} | Labels {labels.shape}')
Producción:
Publicación traducida automáticamente
Artículo escrito por barnadipdey2510 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA