Suffix Tree es muy útil en numerosos problemas de procesamiento de strings y biología computacional. Muchos libros y recursos electrónicos hablan de ello teóricamente y en pocos lugares se discute la implementación del código. Pero aún así, sentí que faltaba algo y no es fácil implementar el código para construir el árbol de sufijos y su uso en muchas aplicaciones. Este es un intento de cerrar la brecha entre la teoría y la implementación completa del código de trabajo. Aquí discutiremos el algoritmo de construcción del árbol de sufijos de Ukkonen. Lo discutiremos paso a paso de manera detallada y en múltiples partes desde la teoría hasta la implementación. Comenzaremos con la forma de fuerza bruta e intentaremos comprender diferentes conceptos, trucos involucrados en el algoritmo de Ukkonen y, en la última parte, se discutirá la implementación del código.
NotaNota: Es posible que le resulte difícil comprender alguna parte del algoritmo durante la primera o la segunda lectura y está perfectamente bien. Con algunos intentos y pensamientos más, debería poder entender tales porciones.
Book Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology de Dan Gusfield explica muy bien los conceptos.
Un árbol de sufijos T para una string de caracteres m S es un árbol dirigido con raíz con exactamente m hojas numeradas del 1 al m. (Dado que el último carácter de la string es único en la string)
- Root puede tener cero, uno o más hijos.
- Cada Node interno, que no sea la raíz, tiene al menos dos hijos.
- Cada borde está etiquetado con una substring no vacía de S.
- Dos bordes que no salen del mismo Node no pueden tener etiquetas de borde que comiencen con el mismo carácter.
La concatenación de las etiquetas de borde en el camino desde la raíz hasta la hoja i da el sufijo de S que comienza en la posición i, es decir, S[i…m].
Nota: La posición comienza con 1 (no está indexada a cero, pero más adelante, durante la implementación del código, usaremos la posición indexada a cero)
Para la string S = xabxac con m = 6, el árbol de sufijos tendrá el siguiente aspecto:
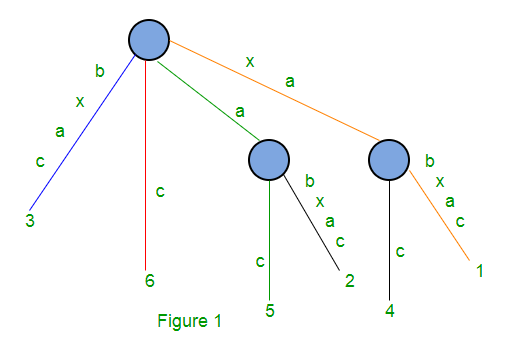
Tiene un Node raíz y dos Nodes internos y 6 Nodes hoja.
La profundidad de la ruta de la string es 1 y representa el sufijo c que comienza en la posición 6
La profundidad de la ruta de la string es 4 y representa el sufijo bxca que comienza en la posición 3
La profundidad de la ruta de la string es 2 y representa el sufijo ac que comienza en la posición 5
La profundidad de la ruta de la string es 6 y representa el sufijo xabxac a partir de la posición 1
Los bordes con etiquetas a() y xa() no son bordes de hoja (que terminan en un Node interno). Todos los demás bordes son borde de hoja (termina en una hoja)
Si un sufijo de S coincide con un prefijo de otro sufijo de S (cuando el último carácter no es único en la string), la ruta del primer sufijo no terminaría en una hoja.
Para String S = xabxa, con m = 5, el siguiente es el árbol de sufijos:
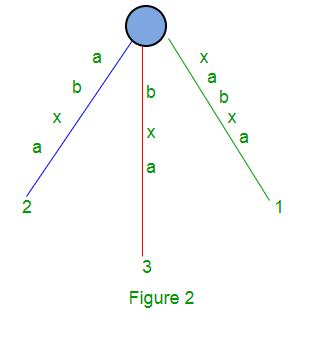
Aquí tendremos 5 sufijos: xabxa, abxa, bxa, xa y a.
La ruta para los sufijos ‘xa’ y ‘a’ no terminan en una hoja. Un árbol como el anterior (Figura 2) se llama árbol de sufijos implícitos ya que algunos sufijos (‘xa’ y ‘a’) no se ven explícitamente en el árbol.
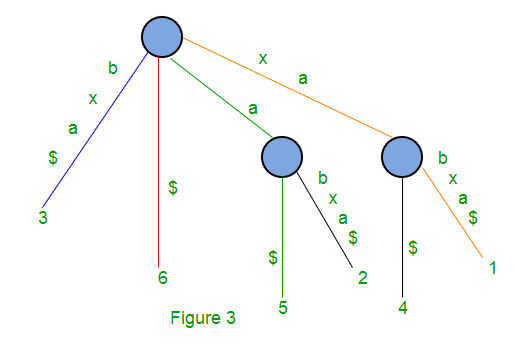
Para evitar este problema, agregamos un carácter que aún no está presente en la string. Normalmente usamos $, #, etc. como caracteres de terminación.
El siguiente es el árbol de sufijos para la string S = xabxa$con m = 6 y ahora los 6 sufijos terminan en hoja.
Un algoritmo ingenuo para construir un árbol de sufijos
Dada una string S de longitud m, ingrese un solo borde para el sufijo S[1 ..m]$(la string completa) en el árbol, luego ingrese sucesivamente el sufijo S[i..m] $en el árbol en crecimiento, porque i aumenta de 2 a m. Sea N i el árbol intermedio que codifica todos los sufijos del 1 al i.
Entonces N i +1 se construye a partir de N i de la siguiente manera:
- Empezar en la raíz de N i
- Encuentre la ruta más larga desde la raíz que coincida con un prefijo de S[i+1..m]$
- La coincidencia termina en el Node (digamos w) o en medio de un borde [digamos (u, v)].
- Si está en el medio de un borde (u, v), divida el borde (u, v) en dos bordes insertando un nuevo Node w justo después del último carácter en el borde que coincide con un carácter en S[i+l ..m] y justo antes del primer carácter en el borde que no coincide. La nueva arista (u, w) se etiqueta con la parte de la etiqueta (u, v) que coincidía con S[i+1..m], y la nueva arista (w, v) se etiqueta con la parte restante de la etiqueta (u, v).
- Cree un nuevo borde (w, i+1) desde w hasta una nueva hoja etiquetada como i+1 y etiquete el nuevo borde con la parte no coincidente del sufijo S[i+1..m]
Esto toma O(m 2 ) para construir el árbol de sufijos para la string S de longitud m.
Los siguientes son algunos pasos para construir un árbol de sufijos basado en la string “xabxa$” basado en el algoritmo anterior:
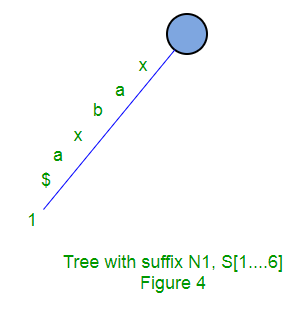
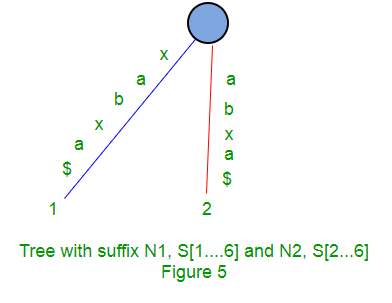
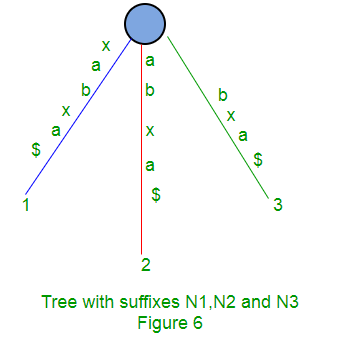
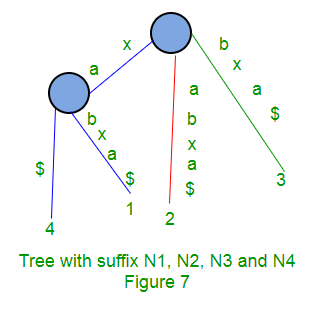
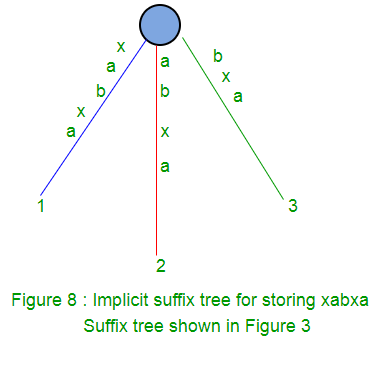
Árbol de sufijos implícito
Al generar el árbol de sufijos utilizando el algoritmo de Ukkonen, veremos el árbol de sufijos implícito en pasos intermedios varias veces dependiendo de los caracteres en la string S. En los árboles de sufijos implícitos, no habrá borde con $(o # o cualquier otro carácter de terminación) etiqueta y ningún Node interno con solo un borde saliendo de él.
Para obtener un árbol de sufijos implícito de un árbol de sufijos S$,
- Elimine todo el símbolo de terminal $de las etiquetas de borde del árbol,
- Eliminar cualquier borde que no tenga etiqueta
- Elimine cualquier Node que tenga solo un borde saliendo y fusione los bordes.
Descripción de alto nivel del algoritmo de Ukkonen El algoritmo
de Ukkonen construye un árbol de sufijos implícito Ti para cada prefijo S[l ..i ] de S (de longitud m).
Primero construye T 1 usando el 1er carácter, luego T 2 usando el 2 do carácter, luego T 3 usando el 3 er carácter, …, T m usando el m ésimo carácter.
El árbol de sufijos implícitos T i +1 se construye sobre el árbol de sufijos implícitos T i .
El verdadero árbol de sufijos para S se construye a partir de T m añadiendo $.
En cualquier momento, el algoritmo de Ukkonen construye el árbol de sufijos para los caracteres vistos hasta ahora, por lo que tiene una propiedad en línea que puede ser útil en algunas situaciones.
El tiempo empleado es O(m).
El algoritmo de Ukkonen se divide en m fases (una fase para cada carácter de la string con longitud m)
En la fase i+1, el árbol Ti +1 se construye a partir del árbol Ti .
Cada fase i+1 se divide además en extensiones i+1, una para cada uno de los sufijos i+1 de S[1..i+1].
En la extensión j de la fase i+1, el algoritmo primero encuentra el final de la ruta desde la raíz etiquetada con la substring S[j..i].
Luego extiende la substring agregando el carácter S(i+1) al final (si aún no está allí).
En la extensión 1 de la fase i+1, colocamos la string S[1..i+1] en el árbol. Aquí S[1..i] ya estará presente en el árbol debido a la fase anterior i. Solo necesitamos agregar el carácter S[i+1]th en el árbol (si aún no está allí).
En la extensión 2 de la fase i+1, colocamos la string S[2..i+1] en el árbol. Aquí S[2..i] ya estará presente en el árbol debido a la fase anterior i. Solo necesitamos agregar el carácter S[i+1]th en el árbol (si aún no está allí)
En la extensión 3 de la fase i+1, colocamos la string S[3..i+1] en el árbol. Aquí S[3..i] ya estará presente en el árbol debido a la fase anterior i. Solo necesitamos agregar el carácter S[i+1]th en el árbol (si aún no está allí)
.
.
En la extensión i+1 de la fase i+1, colocamos la string S[i+1..i+1] en el árbol. Este es solo un personaje que puede no estar en el árbol (si el personaje se ve por primera vez hasta ahora). Si es así, simplemente agregamos un nuevo borde de hoja con la etiqueta S[i+1].
Alto nivel Algoritmo de Ukkonen
Construya el árbol T 1
Para i de 1 a m-1
comience {fase i+1}
Para j de 1 a i+1
comience {extensión j}
Encuentre el final de la ruta desde la raíz etiquetada como S[j ..i] en el árbol actual.
Extienda esa ruta agregando el carácter S[i+l] si aún no está ahí
;
final;
La extensión de sufijo se trata de agregar el siguiente carácter en el árbol de sufijos construido hasta ahora.
En la extensión j de la fase i+1, el algoritmo encuentra el final de S[j..i] (que ya está en el árbol debido a la fase i anterior) y luego extiende S[j..i] para asegurarse de que el sufijo S[j..i+1] está en el árbol.
Hay 3 reglas de extensión:
Regla 1 : si la ruta desde la raíz etiquetada S[j..i] termina en el borde de la hoja (es decir, S[i] es el último carácter en el borde de la hoja), entonces el carácter S[i+1] es simplemente agregado al final de la etiqueta en ese borde de la hoja.
Regla 2 : si la ruta desde la raíz etiquetada S[j..i] termina en el borde que no es de hoja (es decir, hay más caracteres después de S[i] en la ruta) y el siguiente carácter no es s[i+1], entonces se crea un nuevo borde de hoja con la etiqueta s{i+1] y el número j a partir del carácter S[i+1].
También se creará un nuevo Node interno si s[1..i] termina dentro (en el medio) de un borde que no sea hoja.
Regla 3 : si la ruta desde la raíz etiquetada S[j..i] termina en el borde que no es de hoja (es decir, hay más caracteres después de S[i] en la ruta) y el siguiente carácter es s[i+1] (ya en árbol), no hacer nada.
Un punto importante a tener en cuenta aquí es que desde un Node dado (raíz o interno), habrá una y solo una arista a partir de un carácter. No habrá más de un borde saliendo de cualquier Node, comenzando con el mismo carácter.
A continuación, se muestra paso a paso la construcción del árbol de sufijos de la string xabxac utilizando el algoritmo de Ukkonen:
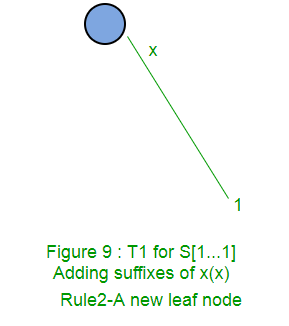
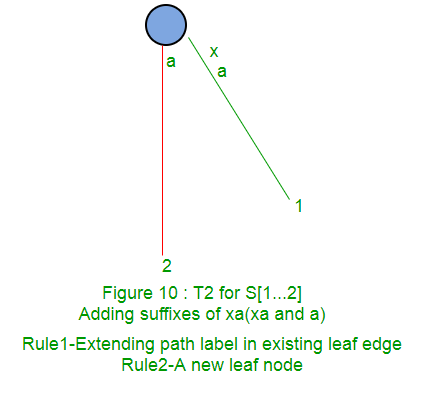
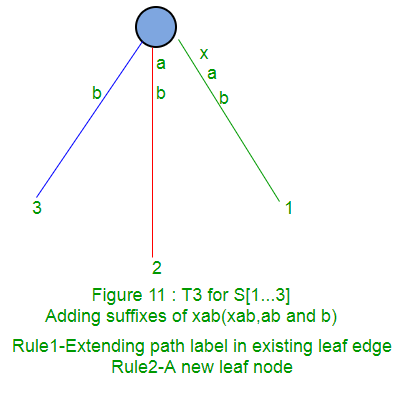
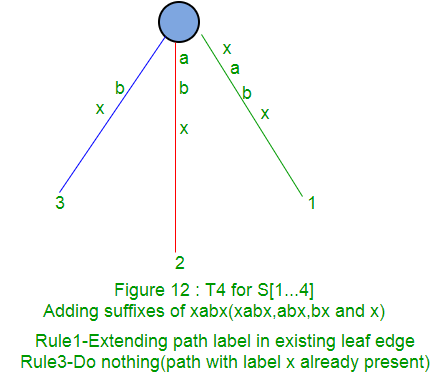
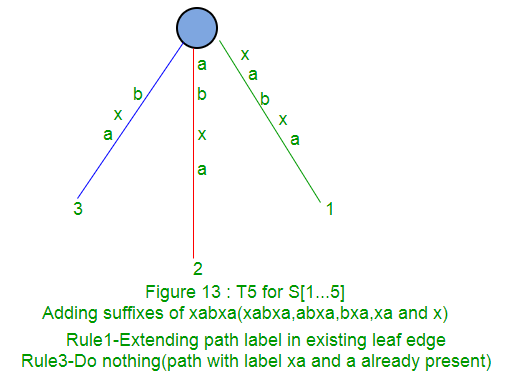
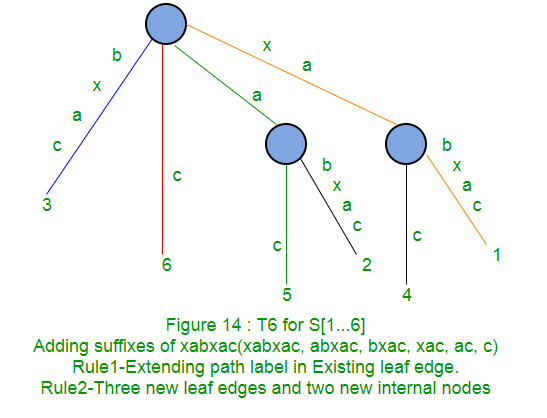
En las siguientes partes ( Parte 2 , Parte 3 , Parte 4 y Parte 5 ), discutiremos enlaces de sufijos, puntos activos, algunos trucos y finalmente implementaciones de código ( Parte 6 ).
Referencias :
http://web.stanford.edu/~mjkay/gusfield.pdf
Este artículo es una contribución de Anurag Singh . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA