En Construcción del árbol de sufijos de Ukkonen – Parte 1 , hemos visto el Algoritmo de Ukkonen de alto nivel. Esta segunda parte es la continuación de la primera parte .
Lea la Parte 1 antes de ver el artículo actual.
En la construcción del árbol de sufijos de la string S de longitud m, hay m fases y para una fase j (1 <= j <= m), agregamos j -ésimo carácter en el árbol construido hasta ahora y esto se hace a través de j extensiones. Todas las extensiones siguen una de las tres reglas de extensión (discutidas en la Parte 1 ).
Para hacer la j -ésima extensión de la fase i+1 (agregando el carácter S[i+1]), primero debemos encontrar el final de la ruta desde la raíz etiquetada como S[j..i] en el árbol actual. Una forma es comenzar desde la raíz y atravesar los bordes que coinciden con la string S[j..i]. Esto llevará O(m 3 ) tiempo para construir el árbol de sufijos. Usando algunas observaciones y trucos de implementación, se puede hacer en O(m) que veremos ahora.
Enlaces de sufijo
Para un Node interno v con etiqueta de ruta xA, donde x denota un solo carácter y A denota una substring (posiblemente vacía), si hay otro Node s(v) con etiqueta de ruta A, entonces un puntero de v a s(v) se llama enlace de sufijo.
Si A es una string vacía, el enlace del sufijo del Node interno irá al Node raíz.
No habrá ningún enlace de sufijo desde el Node raíz (ya que no se considera un Node interno). 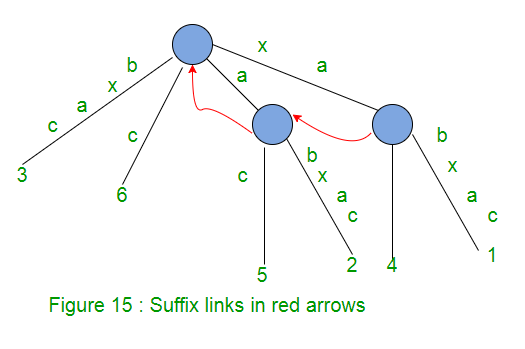
En la extensión j de alguna fase i, si se agrega un nuevo Node interno v con etiqueta de ruta xA, entonces en la extensión j+1 en la misma fase i:
- La ruta etiquetada como A ya termina en un Node interno (o en el Node raíz si A está vacío)
- O se creará un nuevo Node interno al final de la string A
En la extensión j+1 de la misma fase i, crearemos un enlace de sufijo desde el Node interno creado en la j -ésima extensión hasta el Node con la ruta etiquetada como A.
Entonces, en una fase determinada, cualquier Node interno recién creado (con la etiqueta de ruta xA) tendrá un enlace de sufijo (que apunta a otro Node con la etiqueta de ruta A) al final de la siguiente extensión.
En cualquier árbol de sufijos implícitos Ti después de la fase i , si el Node interno v tiene la etiqueta de ruta xA, entonces hay un Node s(v) en Ti con la etiqueta de ruta A y el Node v apuntará al Node s(v) usando enlace de sufijo
En cualquier momento, todos los Nodes internos en el árbol cambiante tendrán enlaces de sufijo desde ellos a otro Node interno (o raíz), excepto el Node interno agregado más recientemente, que recibirá su enlace de sufijo al final de la siguiente extensión.
¿Cómo se utilizan los enlaces de sufijo para acelerar la implementación?
En la extensión j de la fase i+1, necesitamos encontrar el final del camino desde la raíz etiquetada como S[j..i] en el árbol actual. Una forma es comenzar desde la raíz y atravesar los bordes que coinciden con la string S[j..i]. Los enlaces de sufijo proporcionan un atajo para encontrar el final de la ruta. 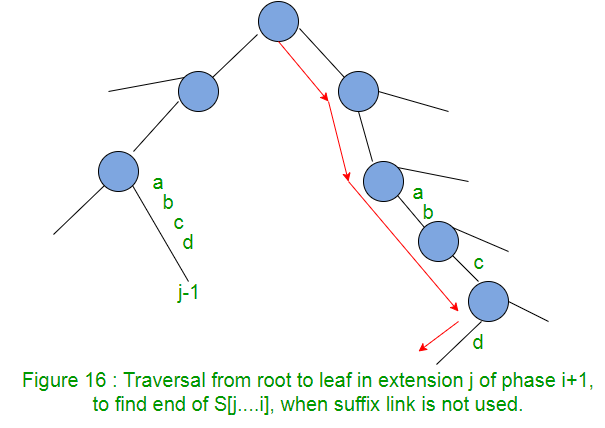
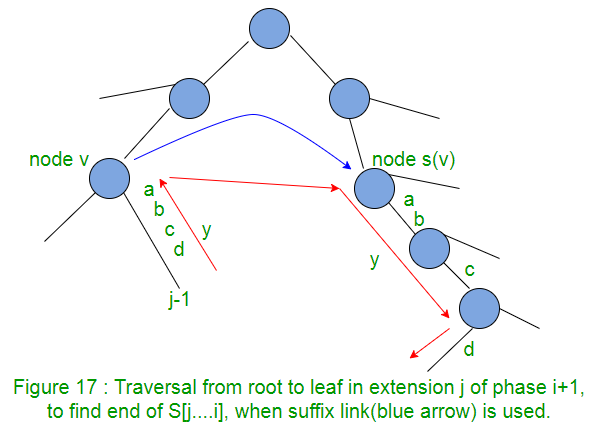
Entonces podemos ver que, para encontrar el final del camino S[j..i], no necesitamos atravesar desde la raíz. Podemos comenzar desde el final de la ruta S[j-1..i], subir un borde hasta el Node v (es decir, ir al Node principal), seguir el enlace del sufijo hasta s(v), luego caminar por la ruta y ( que es abcd aquí en la Figura 17).
Esto muestra que el uso del enlace de sufijo es una mejora con respecto al proceso.
Nota: En la siguiente parte 3, presentaremos activePoint que ayudará a evitar «caminar hacia arriba». Podemos ir directamente al Node s(v) desde el Node v.
Cuando hay un enlace de sufijo desde el Node v al Node s(v), entonces si hay una ruta etiquetada con la string y desde el Node v a una hoja, entonces debe haber una ruta etiquetada con la string y desde el Node s(v) a una hoja. En la Figura 17, hay una etiqueta de ruta «abcd» desde el Node v hasta una hoja, luego hay una ruta con la misma etiqueta «abcd» desde el Node s(v) hasta una hoja.
Este hecho se puede utilizar para mejorar la caminata de s(v) a leaf a lo largo del camino y. Esto se llama truco de “saltar/contar”.
Saltar/Contar truco
Al caminar desde el Node s(v) a la hoja, en lugar de hacer coincidir el camino carácter por carácter a medida que viajamos, podemos saltar directamente al siguiente Node si el número de caracteres en el borde es menor que el número de caracteres que necesitamos. necesito viajar Si la cantidad de caracteres en el borde es mayor que la cantidad de caracteres que necesitamos para viajar, saltamos directamente al último carácter en ese borde.
Si la implementación es tal que la cantidad de caracteres en cualquier borde, el carácter en una posición dada en la string S debe obtenerse en un tiempo constante, entonces el truco de omitir/contar hará el recorrido hacia abajo en proporción a la cantidad de Nodes en él en lugar de el número de caracteres en él. 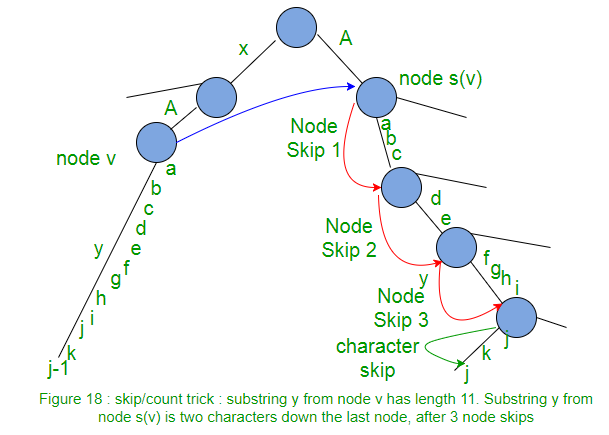
Usando el enlace de sufijo junto con el truco de omitir/contar, el árbol de sufijo se puede construir en O(m 2) ya que hay m fases y cada fase toma O(m).
Compresión de etiquetas de borde
Hasta ahora, las etiquetas de ruta se representan como caracteres en una string. Dicho árbol de sufijos ocupará un espacio de O(m 2 ) para almacenar las etiquetas de ruta. Para evitar esto, podemos usar dos pares de índices (inicio, final) en cada borde para las etiquetas de ruta, en lugar de la substring en sí. Los índices start y end le indican a la etiqueta de ruta la posición de inicio y fin en la string S. Con esto, el árbol de sufijos necesita un espacio O(m). 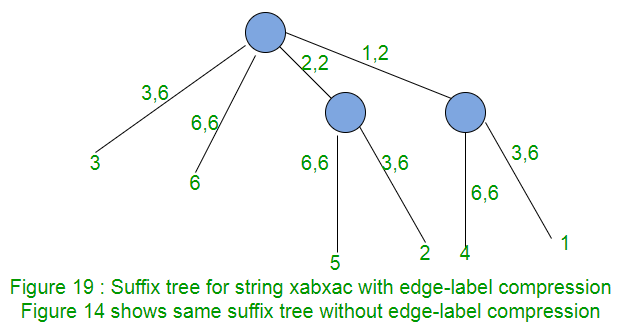
Hay dos observaciones sobre la forma en que las reglas de extensión interactúan en sucesivas extensiones y fases. Estas dos observaciones conducen a otros dos trucos de implementación (el primer truco «saltar/contar» ya se ve mientras camina hacia abajo).
Observación 1: La regla 3 es show stopper
En una fase i, hay i extensiones (1 a i) por hacer.
Cuando la regla 3 se aplica en cualquier extensión j de la fase i+1 (es decir, la ruta etiquetada S[j..i] continúa con el carácter S[i+1]), entonces también se aplicará en todas las extensiones posteriores de la misma fase (es decir, extensiones j+1 a i+1 en la fase i+1). Eso es porque si la ruta con la etiqueta S[j..i] continúa con el carácter S[i+1], entonces la ruta con la etiqueta S[j+1..i], S[j+2..i], S[j+3 ..i],…, S[i..i] también continuará con el carácter S[i+1].
Considere la Figura 11, la Figura 12 y la Figura 13 en la Parte 1 donde se aplica la Regla 3.
En la Figura 11, se agrega «xab» en el árbol y en la Figura 12 (Fase 4), agregamos el siguiente carácter «x». En este se hacen 3 extensiones (a las que se le suman 3 sufijos). El último sufijo «x» ya está presente en el árbol.
En la Figura 13, agregamos el carácter “a” en el árbol (Fase 5). Los primeros 3 sufijos se agregan en el árbol y los últimos dos sufijos «xa» y «a» ya están presentes en el árbol. Esto muestra que si el sufijo S[j..i] está presente en el árbol, entonces TODOS los sufijos restantes S[j+1..i], S[j+2..i], S[j+3..i] ,…, S[i..i] también estará allí en el árbol y no será necesario trabajar para agregar los sufijos restantes.
Por lo tanto, no fue necesario realizar más trabajo en ninguna fase tan pronto como se aplique la regla 3 en cualquier extensión de esa fase. Si se crea un nuevo Node interno v en la extensión j y se aplica la regla 3 en la siguiente extensión j+1, entonces debemos agregar un enlace de sufijo desde el Node v al Node actual (si estamos en el Node interno) o al Node raíz. ActiveNode, que se discutirá en la parte 3, ayudará al establecer enlaces de sufijo.
Truco 2
Detenga el procesamiento de cualquier fase tan pronto como se aplique la regla 3. Todas las extensiones adicionales ya están presentes en el árbol implícitamente.
Observación 2: Una vez que una hoja, siempre una hoja
Una vez que se crea una hoja y se etiqueta como j (para el sufijo que comienza en la posición j en la string S), esta hoja siempre será una hoja en fases y extensiones sucesivas. Una vez que una hoja se etiqueta como j, la regla de extensión 1 siempre se aplicará a la extensión j en todas las fases sucesivas.
Considere la Figura 9 a la Figura 14 en la Parte 1 .
En la Figura 10 (Fase 2), la regla 1 se aplica en la hoja etiquetada con 1. Después de esto, en todas las fases sucesivas, la regla 1 se aplica siempre en esta hoja.
En la Figura 11 (Fase 3), la regla 1 se aplica en la hoja etiquetada como 2. Después de esto, en todas las fases sucesivas, la regla 1 se aplica siempre en esta hoja.
En la Figura 12 (Fase 4), la Regla 1 se aplica en la hoja etiquetada como 3. Después de esto, en todas las fases sucesivas, la regla 1 se aplica siempre en esta hoja.
En cualquier fase i, hay una secuencia inicial de prórrogas consecutivas donde se aplica la regla 1 o la regla 2 y luego, tan pronto como se aplica la regla 3, finaliza la fase i.
Además, la regla 2 siempre crea una hoja nueva (ya veces un Node interno).
Si J i representa la última extensión en la fase i cuando se aplicó la regla 1 o 2 (es decir, después de la i -ésima fase, habrá hojas J i etiquetadas como 1, 2, 3, …, J i ), entonces J i <= J i +1
J i será igual a J i+1 cuando no se cree una nueva hoja en la fase i+1 (es decir, la regla 3 se aplica en la extensión J i+1 )
En la Figura 11 (Fase 3), la Regla 1 se aplica en las dos primeras extensiones y la Regla 2 se aplica en la tercera extensión, por lo que aquí J 3 = 3
En la Figura 12 (Fase 4), no se crea ninguna hoja nueva (la Regla 1 se aplica en la primera 3 prórrogas y luego se aplica la regla 3 en la 4ª prórroga que finaliza la fase). Aquí J 4 = 3 = J 3
En la Figura 13 (Fase 5), no se crea ninguna hoja nueva (la Regla 1 se aplica en las 3 primeras extensiones y luego la regla 3 se aplica en la 4ª extensión que finaliza la fase). Aquí J 5 = 3 = J 4
J i será menor que J i+1 cuando se creen pocas hojas nuevas en la fase i+1.
En la Figura 14 (Fase 6), nueva hoja creada (la regla 1 se aplica en las 3 primeras extensiones y luego la regla 2 se aplica en las últimas 3 extensiones, lo que finaliza la fase). Aquí J 6 = 6 > J 5
Entonces podemos ver que en la fase i+1, solo se aplicará la regla 1 en las extensiones 1 a J i (que realmente no necesita mucho trabajo, se puede hacer en tiempo constante y ese es el truco 3), extensión J i+1 en adelante, la regla 2 puede aplicarse a cero o más prórrogas y finalmente la regla 3, que finaliza la fase.
Ahora las etiquetas de borde se representan usando dos índices (inicio, final), para cualquier borde de hoja, el final siempre será igual al número de fase, es decir, para la fase i, final = i para los bordes de la hoja, para la fase i+1, final = i+1 para bordes de hojas.
Truco 3
En cualquier fase i, los bordes de las hojas pueden parecerse a (p, i), (q, i), (r, i),…. donde p, q, r son la posición inicial de los diferentes bordes e i es la posición final de todos. Luego, en la fase i+1, estos bordes de hoja se verán como (p, i+1), (q, i+1), (r, i+1),…. De esta manera, en cada fase, la posición final debe incrementarse en todos los bordes de la hoja. Para esto, necesitamos atravesar todos los bordes de las hojas e incrementar la posición final para ellos. Para hacer lo mismo en tiempo constante, mantenga un índice global e y e será igual al número de fase. Así que ahora los bordes de las hojas se verán como (p, e), (q, e), (r, e).. En cualquier fase, solo incremente e y se realizará la extensión en todos los bordes de las hojas. La figura 19 muestra esto.
Entonces, usando los enlaces de sufijos y los trucos 1, 2 y 3, se puede construir un árbol de sufijos en tiempo lineal.
Tree Tm podría ser árbol implícito si un sufijo es prefijo de otro. Entonces, primero podemos agregar un símbolo de terminal $y luego ejecutar el algoritmo para obtener un árbol de sufijos verdadero (un árbol de sufijos verdadero contiene todos los sufijos explícitamente). Para etiquetar cada hoja con la posición de inicio del sufijo correspondiente (todas las hojas están etiquetadas como índice global e), se puede realizar un recorrido de tiempo lineal en el árbol.
En este punto, hemos repasado la mayoría de las cosas que necesitábamos saber para crear un árbol de sufijos usando el algoritmo de Ukkonen. En la próxima Parte 3 , tomaremos la string S = «abcabxabcd» como ejemplo y revisaremos todo paso a paso y crearemos el árbol. Mientras construimos el árbol, discutiremos algunos problemas de implementación más que serán abordados por ActivePoints.
Continuaremos discutiendo el algoritmo en las Partes 4 y 5 . La implementación del código se discutirá en la Parte 6 .
Referencias :
http://web.stanford.edu/~mjkay/gusfield.pdf
Este artículo es una contribución de Anurag Singh . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA