A través de este artículo, aprenderemos cómo eliminar columnas duplicadas de una tabla de base de datos. Como sabemos, la duplicidad en nuestra base de datos tiende a ser una pérdida de espacio de memoria. Registra datos inexactos y tampoco puede obtener los datos correctos de la base de datos. Para eliminar las columnas duplicadas, usamos el operador DISTINCT en la declaración SELECT de la siguiente manera:
Sintaxis:
SELECT DISTINCT
column1, column2, ...
FROM
table1;
- DISTINCT cuando se usa en una columna, usa los valores en esa columna para evaluar los duplicados.
- Cuando hay dos o más columnas, utiliza la combinación de valores en esas columnas para evaluar el duplicado.
Nota: DISTINCT no elimina los datos de la tabla, solo elimina los duplicados en la tabla resultante.
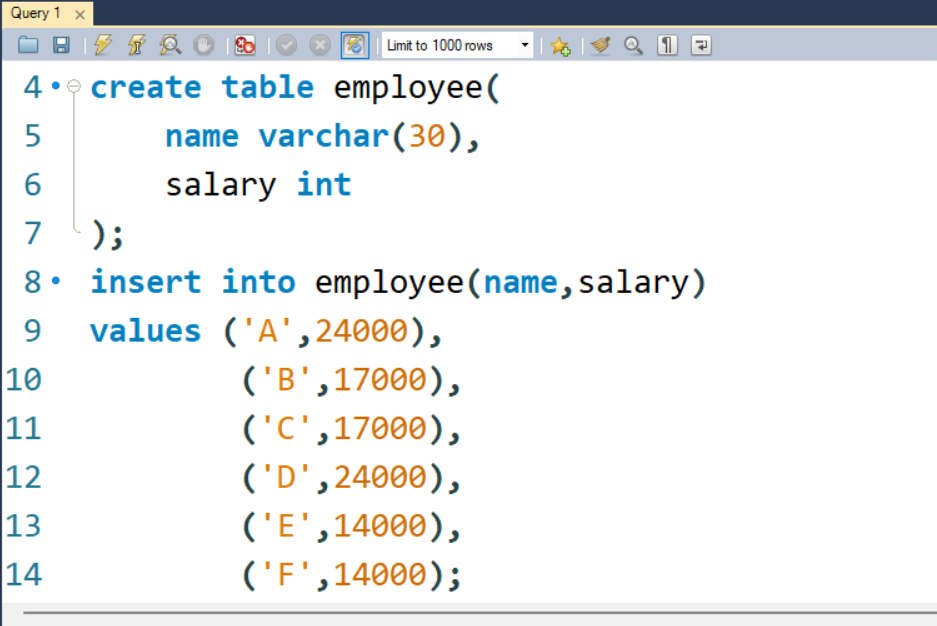
Paso 1: Primero tenemos que crear una tabla con el nombre «empleado»
Consulta:
CREATE TABLE employee ( name varchar(30),salary int);
Paso 2: Ahora, tenemos que insertar valores o datos en la tabla.
Consulta:
INSERT INTO employee (name,salary)
VALUES ('A',24000),
('B',17000),
('C',17000),
('D',24000),
('E',14000),
('F',14000);
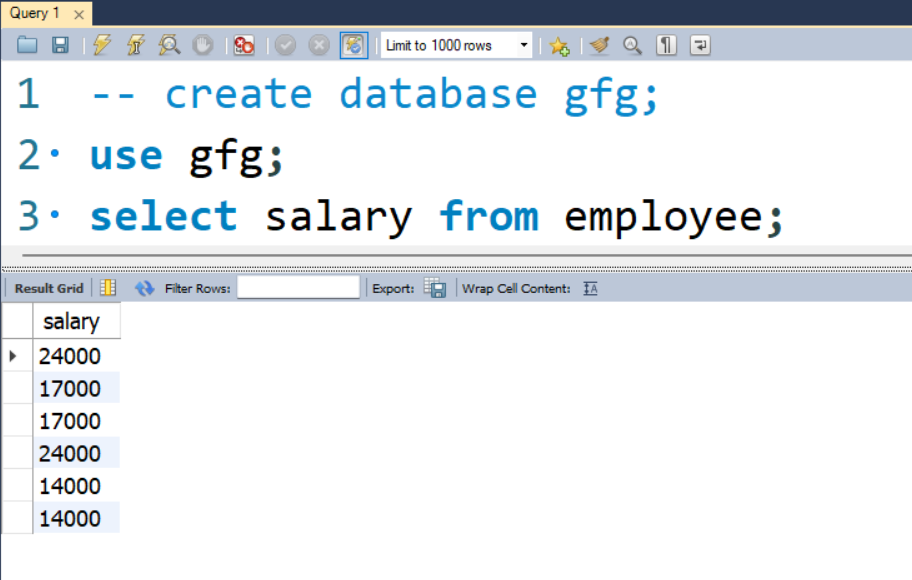
Paso 3: ahora vemos el valor de la tabla completa utilizando la consulta que se indica a continuación.
Consulta:
SELECT salary FROM employee;
Producción:
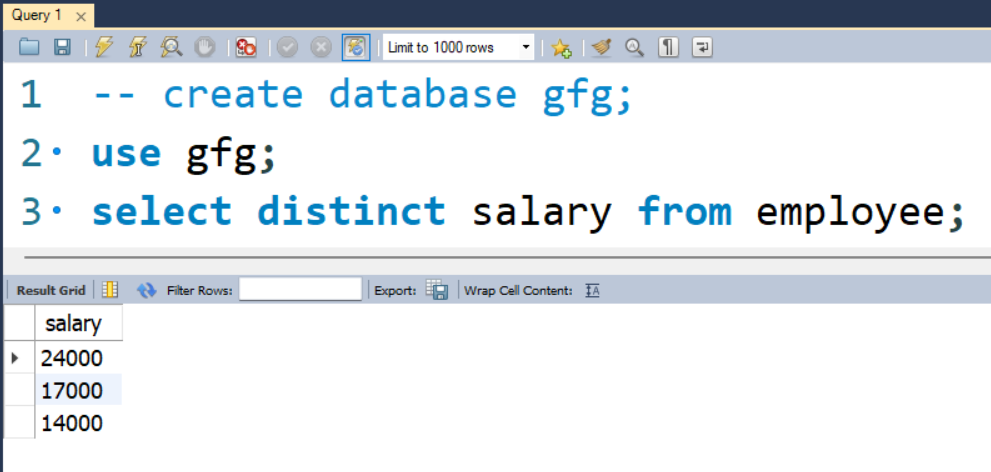
Paso 4: Estamos usando la tabla de empleados en una base de datos de muestra como muestra para mostrar usos DISTINTOS.
Consulta:
SELECT DISTINCT salary FROM employees;
Producción:
Publicación traducida automáticamente
Artículo escrito por adarshsingh100 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA