Mientras operamos marcos de datos en Pandas, podemos encontrar una situación para colapsar las columnas. Deje que se
acumulen datos de varias columnas o se colapsen en función de algún otro requisito. Veamos cómo colapsar varias columnas en Pandas.
Se deben seguir los siguientes pasos para colapsar varias columnas en Pandas:
Paso #1: Cargue numpy y Pandas.
Paso #2: Cree datos aleatorios y utilícelos para crear un marco de datos de pandas.
Paso #3: Convierta múltiples listas en un solo marco de datos, creando un diccionario para cada lista con un nombre.
Paso #4: luego use el marco de datos de Pandas en dict. Está listo un marco de datos con columnas de datos y una columna para nombres.
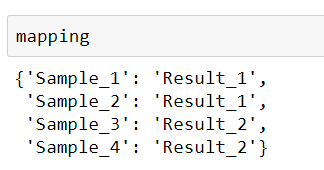
Paso #5: Especifique qué columnas se contraerán. Eso se puede hacer especificando la asignación como un diccionario, donde las claves son los nombres de las columnas que se combinarán o contraerán y los valores son los nombres de la columna resultante.
Ejemplo 1:
# Python program to collapse
# multiple Columns using Pandas
import pandas as pd
# sample data
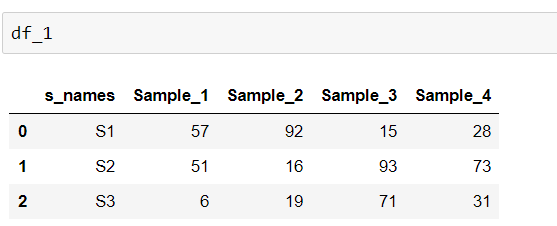
n = 3
Sample_1 = [57, 51, 6]
Sample_2 = [92, 16, 19]
Sample_3 = [15, 93, 71]
Sample_4 = [28, 73, 31]
sample_id = zip(["S"]*n, list(range(1, n + 1)))
s_names = [''.join([w[0], str(w[1])]) for w in sample_id]
d = {'s_names': s_names, 'Sample_1': Sample_1,
'Sample_2': Sample_2, 'Sample_3': Sample_3,
'Sample_4': Sample_4}
df_1 = pd.DataFrame(d)
mapping = {'Sample_1': 'Result_1',
'Sample_2': 'Result_1',
'Sample_3': 'Result_2',
'Sample_4': 'Result_2'}
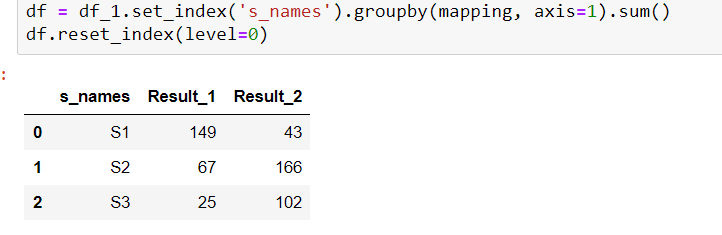
df = df_1.set_index('s_names').groupby(mapping, axis = 1).sum()
df.reset_index(level = 0)
Producción:
Ejemplo 2:
# Python program to collapse
# multiple Columns using Pandas
import pandas as pd
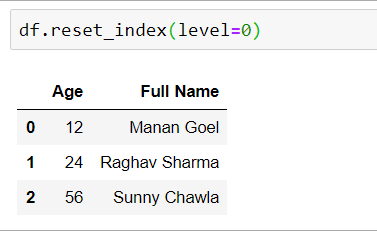
df = pd.DataFrame({'First': ['Manan ', 'Raghav ', 'Sunny '],
'Last': ['Goel', 'Sharma', 'Chawla'],
'Age':[12, 24, 56]})
mapping = {'First': 'Full Name', 'Last': 'Full Name'}
df = df.set_index('Age').groupby(mapping, axis = 1).sum()
df.reset_index(level = 0)
Producción: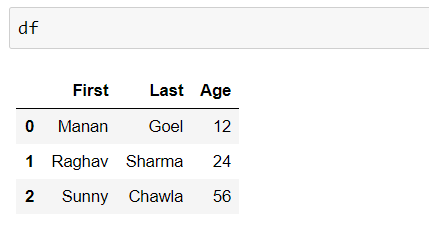

Publicación traducida automáticamente
Artículo escrito por apeksharustagi1998 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA