En este artículo, vamos a ver cómo convertir estructuras JSON anidadas en Pandas DataFrames.
JSON con múltiples niveles
En este caso, los datos JSON anidados contienen otro objeto JSON como valor para algunos de sus atributos. Esto hace que los datos sean de varios niveles y necesitamos aplanarlos según los requisitos del proyecto para una mejor legibilidad, como se explica a continuación.
Python3
# importing the libraries used
import pandas as pd
# initializing the data
data = {
'company': 'XYZ pvt ltd',
'location': 'London',
'info': {
'president': 'Rakesh Kapoor',
'contacts': {
'email': 'contact@xyz.com',
'tel': '9876543210'
}
}
}
Aquí, los datos contienen múltiples niveles. Para convertirlo en un dataframe usaremos la función json_normalize() de la biblioteca pandas.
Python3
pd.json_normalize(data)
Producción:

datos json convertidos a marco de datos pandas
Aquí, vemos que los datos se aplanan y se convierten en columnas. Si no deseamos aplanar completamente los datos, podemos usar el atributo max_level como se muestra a continuación.
Python3
pd.json_normalize(data,max_level=0)
Producción:

datos json convertidos a marco de datos pandas
Aquí, vemos que la columna de información no se aplana más.
Python3
pd.json_normalize(data,max_level=1)
Producción:

datos json convertidos a marco de datos pandas
Aquí, vemos que la columna de contactos no se aplana más.
Lista de JSON anidados
Ahora, si los datos son una lista de JSON anidados, obtendremos varios registros en nuestro marco de datos.
Python3
data = [
{
'id': '001',
'company': 'XYZ pvt ltd',
'location': 'London',
'info': {
'president': 'Rakesh Kapoor',
'contacts': {
'email': 'contact@xyz.com',
'tel': '9876543210'
}
}
},
{
'id': '002',
'company': 'PQR Associates',
'location': 'Abu Dhabi',
'info': {
'president': 'Neelam Subramaniyam',
'contacts': {
'email': 'contact@pqr.com',
'tel': '8876443210'
}
}
}
]
pd.json_normalize(data)
Producción:

datos json convertidos a marco de datos pandas
Entonces, en el caso de múltiples niveles de JSON, podemos probar diferentes valores del atributo max_level .
JSON con listas anidadas
En este caso, el JSON anidado tiene una lista de objetos JSON como valor para algunos de sus atributos. En tal caso, podemos elegir los elementos de la lista interna para que sean los registros/filas de nuestro marco de datos utilizando el atributo record_path .
Python3
# initialising the data
data = {
'company': 'XYZ pvt ltd',
'location': 'London',
'info': {
'president': 'Rakesh Kapoor',
'contacts': {
'email': 'contact@xyz.com',
'tel': '9876543210'
}
},
'employees': [
{'name': 'A'},
{'name': 'B'},
{'name': 'C'}
]
}
# converting the data to dataframe
df = pd.json_normalize(data)
Producción:

datos json convertidos a marco de datos pandas
Aquí, la lista anidada no se aplana. Necesitamos usar el atributo record_path para aplanar la lista anidada.
Python3
pd.json_normalize(data,record_path=['employees'])
Producción:
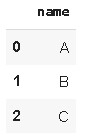
la lista anidada no se aplana
Ahora, observamos que no incluye ‘info’ y otras características. Para incluirlos usamos otro atributo, meta. Tenga en cuenta que, en el siguiente código, para incluir un atributo de un JSON interno, hemos especificado la ruta como «[‘info’, ‘president’]».
Python3
pd.json_normalize(data, record_path=['employees'], meta=[ 'company', 'location', ['info', 'president']])
Producción:
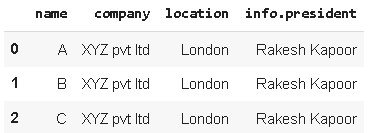
datos json convertidos a marco de datos pandas
Ahora, en el caso de varios objetos JSON anidados, obtendremos un marco de datos con varios registros, como se muestra a continuación.
Python3
data = [
{
'id': '001',
'company': 'XYZ pvt ltd',
'location': 'London',
'info': {
'president': 'Rakesh Kapoor',
'contacts': {
'email': 'contact@xyz.com',
'tel': '9876543210'
}
},
'employees': [
{'name': 'A'},
{'name': 'B'},
{'name': 'C'}
]
},
{
'id': '002',
'company': 'PQR Associates',
'location': 'Abu Dhabi',
'info': {
'president': 'Neelam Subramaniyam',
'contacts': {
'email': 'contact@pqr.com',
'tel': '8876443210'
}
},
'employees': [
{'name': 'L'},
{'name': 'M'},
{'name': 'N'}
]
}
]
df = pd.json_normalize(data, record_path=['employees'], meta=[
'company', 'location', ['info', 'president']])
print(df)
Producción :
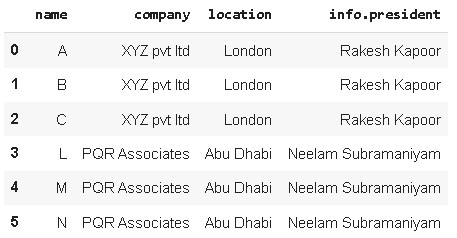
datos json convertidos a marco de datos pandas
Publicación traducida automáticamente
Artículo escrito por yuvrajgrover y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA