Los factores son estructuras de datos que se implementan para categorizar los datos o representar datos categóricos y almacenarlos en múltiples niveles. Se pueden almacenar como enteros con una etiqueta correspondiente a cada entero único. Aunque los factores pueden parecer similares a los vectores de caracteres, son números enteros y se debe tener cuidado al usarlos como strings. El factor acepta solo un número restringido de valores distintos. Es útil para categorizar datos y almacenarlos en múltiples niveles.
Conversión de factores a valores numéricos
A veces necesita cambiar explícitamente los factores a números o texto. Para lograr esto, uno tiene que usar las funciones as.character() o as.numeric() . Hay dos pasos para convertir un factor a numérico: Paso 1: Convierta el vector de datos en un factor. El comando factor() se usa para crear y modificar factores en R. Paso 2: El factor se convierte en un vector numérico usando as.numeric() . Cuando un factor se convierte en un vector numérico, se devolverán los códigos numéricos correspondientes a los niveles del factor. Ejemplo: tome un vector de datos ‘V’ que consta de direcciones y su factor se convertirá en numérico.
Python3
# Data Vector 'V'
V = c("North", "South", "East", "East")
# Convert vector 'V' into a factor
drn <- factor(V)
# Converting a factor into a numeric vector
as.numeric(drn)
Producción:
[1] 2 3 1 1
Conversión de un factor que es un número: si el factor es un número, primero conviértalo en un vector de caracteres y luego en numérico. Si un factor es un carácter, no necesita convertirlo en un carácter. Y si intenta convertir un carácter alfabético a numérico, devolverá NA. Ejemplo: supongamos que estamos tomando costos de jabones de varias marcas que son números con valor s (29, 28, 210, 28, 29).
Python3
# Creating a Factor soap_cost <- factor(c(29, 28, 210, 28, 29)) # Converting Factor to numeric as.numeric(as.character(soap_cost))
Producción:
[1] 29 28 210 28 29
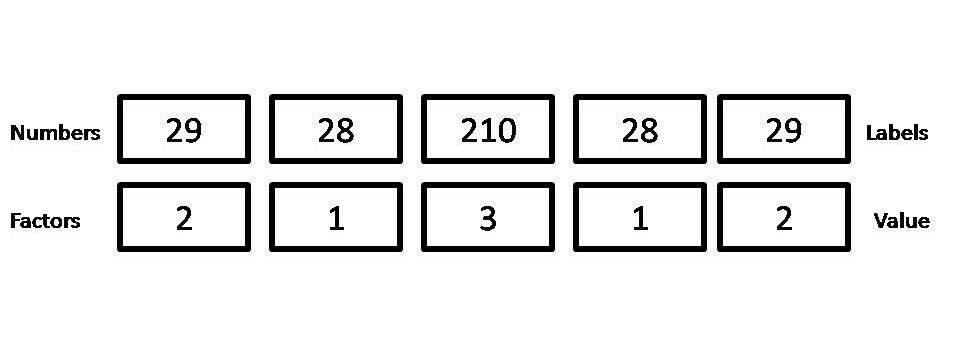 However, if you simply use as. numeric(), the output is a vector of the internal level representations of the factor and not the original values.
However, if you simply use as. numeric(), the output is a vector of the internal level representations of the factor and not the original values.
Python3
# Creating a Factor soap_cost <- factor(c(29, 28, 210, 28, 29)) # Converting Factor to Numeric as.numeric(soap_cost)
Producción:
[1] 2 1 3 1 2
Conversión de valor numérico a un factor
Para convertir un número en factor usamos la función cut() . cut() divide el rango del vector numérico (asumir x) que se va a convertir cortando en intervalos y codifica su valor (x) según el intervalo en el que se encuentran. El nivel uno corresponde al más a la izquierda, el nivel dos corresponde al siguiente más a la izquierda, y así sucesivamente.
Sintaxis: cut.default(x, breaks, label = NULL, include.lowest = FALSE, right = TRUE, dig.lab = 3)
dónde,
- Cuando se proporciona un número a través del argumento ‘break=’, el factor de salida se crea mediante la división del rango de variables en ese número de intervalos de igual longitud.
- En la sintaxis, include.lowest indica si se debe incluir una ‘x[i]’ que es igual al valor de ruptura más bajo (para right= TRUE). Y ‘derecha’ en la sintaxis indica si los intervalos deben estar abiertos a la izquierda y cerrados a la derecha o viceversa.
- Si no se proporcionan etiquetas, se utiliza dig.lab. El número de dígitos utilizados en el formato de los números de corte se determina a través de él.
Ejemplo 1: Supongamos un conjunto de datos de empleados de edad, salario y sexo. Para crear un factor correspondiente a la edad con tres niveles igualmente espaciados podemos escribir en R de la siguiente manera:
Python3
# Creating vectors
age <- c(40, 49, 48, 40, 67, 52, 53)
salary <- c(103200, 106200, 150200, 10606, 10390, 14070, 10220)
gender <- c("male", "male", "transgender",
"female", "male", "female", "transgender")
# Creating data frame named employee
employee<- data.frame(age, salary, gender)
# Creating a factor corresponding to age
# with three equally spaced levels
wfact = cut(employee$age, 3)
table(wfact)
Producción:
wfact
(40,49] (49,58] (58,67]
4 2 1
Ejemplo 2: ahora pondremos etiquetas: joven, mediana y mayor.
Python3
# Creating vectors
age <- c(40, 49, 48, 40, 67, 52, 53)
salary <- c(103200, 106200, 150200, 10606, 10390, 14070, 10220)
gender <- c("male", "male", "transgender",
"female", "male", "female", "transgender")
# Creating data frame named employee
employee<- data.frame(age, salary, gender)
# Creating a factor corresponding to age with labels
wfact = cut(employee$age, 3, labels=c('Young', 'Medium', 'Aged'))
table(wfact)
Producción:
wfact
Young Medium Aged
4 2 1
Los siguientes ejemplos usarán ‘ norm() ‘ para generar variantes aleatorias distribuidas normales multivariadas dentro del espacio especificado. Hay tres argumentos dados a rnorm():
- n: número de variables aleatorias que se deben generar
- media: Su valor es 0 por defecto si no se menciona
- sd: el valor de desviación estándar debe mencionarse; de lo contrario, es 1 por defecto
Sintaxis:
norm(n, mean, sd)
Python3
# Generating a vector with random numbers y <- rnorm(100) # the output factor is created by the division # of the range of variables into pi/3*(-3:3) # 4 equal-length intervals table(cut(y, breaks = pi/3*(-3:3)))
Producción:
(-3.14,-2.09] (-2.09,-1.05] (-1.05,0] (0,1.05] (1.05,2.09]
1 11 26 48 10
(2.09,3.14]
4
El factor de salida se crea mediante la división del rango de variables en 5 intervalos de igual longitud a través del argumento de ruptura.
Python3
age <- c(40, 49, 48, 40, 67, 52, 53)
gender <- c("male", "male", "transgender", "female", "male", "female", "transgender")
# Data frame generated from the above vectors
employee<- data.frame(age, gender)
# the output factor is created by the division
# of the range of variables into 5 equal-length intervals
wfact = cut(employee$age, breaks=5)
table(wfact)
Producción:
wfact
(40,45.4] (45.4,50.8] (50.8,56.2] (56.2,61.6] (61.6,67]
2 2 2 0 1
Python3
y <- rnorm(100) table(cut(y, breaks = pi/3*(-3:3), dig.lab=5))
Producción:
(-3.1416,-2.0944] (-2.0944,-1.0472] (-1.0472,0] (0,1.0472]
5 13 33 28
(1.0472,2.0944] (2.0944,3.1416]
19 2