En este artículo, veremos cómo convertir el marco de datos de PySpark al diccionario, donde las claves son nombres de columna y los valores son valores de columna.
Antes de comenzar, crearemos un marco de datos de muestra:
Python3
# Importing necessary libraries
from pyspark.sql import SparkSession
# Create a spark session
spark = SparkSession.builder.appName('DF_to_dict').getOrCreate()
# Create data in dataframe
data = [(('Ram'), '1991-04-01', 'M', 3000),
(('Mike'), '2000-05-19', 'M', 4000),
(('Rohini'), '1978-09-05', 'M', 4000),
(('Maria'), '1967-12-01', 'F', 4000),
(('Jenis'), '1980-02-17', 'F', 1200)]
# Column names in dataframe
columns = ["Name", "DOB", "Gender", "salary"]
# Create the spark dataframe
df = spark.createDataFrame(data=data,
schema=columns)
# Print the dataframe
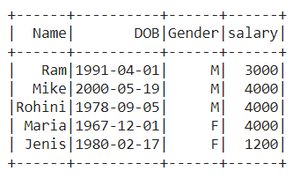
df.show()
Producción :
Método 1: Usar df.toPandas()
Convierta el marco de datos de PySpark en marco de datos de Pandas usando df.toPandas().
Sintaxis: DataFrame.toPandas()
Tipo de devolución: devuelve el marco de datos de pandas que tiene el mismo contenido que el marco de datos de Pyspark.
Obtenga el valor de cada columna y agregue la lista de valores al diccionario con el nombre de la columna como clave.
Python3
# Declare an empty Dictionary
dict = {}
# Convert PySpark DataFrame to Pandas
# DataFrame
df = df.toPandas()
# Traverse through each column
for column in df.columns:
# Add key as column_name and
# value as list of column values
dict[column] = df[column].values.tolist()
# Print the dictionary
print(dict)
Producción :
{‘Nombre’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘María’, ‘Jenis’],
‘Fecha de nacimiento’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Género’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salario’: [3000, 4000, 4000, 4000, 1200]}
Método 2: Usar df.collect()
Convierta el marco de datos de PySpark en la lista de filas y devuelva todos los registros de un marco de datos como una lista.
Sintaxis: DataFrame.collect()
Tipo de retorno: Devuelve todos los registros del marco de datos como una lista de filas.
Python3
import numpy as np
# Convert the dataframe into list
# of rows
rows = [list(row) for row in df.collect()]
# COnvert the list into numpy array
ar = np.array(rows)
# Declare an empty dictionary
dict = {}
# Get through each column
for i, column in enumerate(df.columns):
# Add ith column as values in dict
# with key as ith column_name
dict[column] = list(ar[:, i])
# Print the dictionary
print(dict)
Producción :
{‘Nombre’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘María’, ‘Jenis’],
‘Fecha de nacimiento’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Género’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salario’: [‘3000’, ‘4000’, ‘4000’, ‘4000’, ‘1200’]}
Método 3: Usar pandas.DataFrame.to_dict()
El marco de datos de Pandas se puede convertir directamente en un diccionario usando el método to_dict()
Sintaxis: DataFrame.to_dict(orient=’dict’,)
Parámetros:
- orient: Indicando el tipo de valores del diccionario. Toma valores como {‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’}
Tipo de retorno: Devuelve el diccionario correspondiente al marco de datos.
Código:
Python3
# COnvert PySpark dataframe to pandas # dataframe df = df.toPandas() # Convert the dataframe into # dictionary dict = df.to_dict(orient = 'list') # Print the dictionary print(dict)
Producción :
{‘Nombre’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘María’, ‘Jenis’],
‘Fecha de nacimiento’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Género’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salario’: [3000, 4000, 4000, 4000, 1200]}
Al convertir un marco de datos que tiene 2 columnas en un diccionario, cree un marco de datos con 2 columnas que nombran ‘ Ubicación’ y ‘Precio_casa’
Python3
# Importing necessary libraries
from pyspark.sql import SparkSession
# Create a spark session
spark = SparkSession.builder.appName('DF_to_dict').getOrCreate()
# Create data in dataframe
data = [(('Hyderabad'), 120000),
(('Delhi'), 124000),
(('Mumbai'), 344000),
(('Guntur'), 454000),
(('Bandra'), 111200)]
# Column names in dataframe
columns = ["Location", 'House_price']
# Create the spark dataframe
df = spark.createDataFrame(data=data, schema=columns)
# Print the dataframe
print('Dataframe : ')
df.show()
# COnvert PySpark dataframe to
# pandas dataframe
df = df.toPandas()
# Convert the dataframe into
# dictionary
dict = df.to_dict(orient='list')
# Print the dictionary
print('Dictionary :')
print(dict)
Producción :

Publicación traducida automáticamente
Artículo escrito por ManikantaBandla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA