En este artículo, discutiremos cómo podemos convertir JSON anidado a CSV en Python.
Un ejemplo de un archivo JSON simple:

Una representación JSON simple
Como puede ver en el ejemplo, un único par clave-valor está separado por dos puntos (:), mientras que cada par clave-valor está separado por una coma (,). Aquí, «nombre», «perfil», «edad» y «ubicación» son los campos clave, mientras que los valores correspondientes son » Amit Pathak «, » Ingeniero de software «, «24», «Londres, Reino Unido», respectivamente.
Un JSON anidado es una estructura en la que el valor de uno o más campos puede tener otro formato JSON. Por ejemplo, siga el ejemplo a continuación que vamos a usar para convertir al formato CSV.
Un ejemplo de un archivo JSON anidado:

Un ejemplo de JSON anidado
En el ejemplo anterior, el campo clave » artículo » tiene un valor que es otro formato JSON. JSON admite varios nidos para crear archivos JSON complejos si es necesario.
Conversión de JSON anidado a CSV
Nuestro trabajo es convertir el archivo JSON a un formato CSV. Puede haber muchas razones por las que necesitamos realizar esta conversión. CSV son fáciles de leer cuando se abren en una aplicación GUI de hoja de cálculo como Google Sheets o MS Excel. Es fácil trabajar con ellos para la tarea de análisis de datos. También es un formato ampliamente aceptado cuando se trabaja con datos tabulares, ya que es fácil de ver para los humanos, a diferencia del formato JSON.
Acercarse
- El primer paso es leer el archivo JSON como un objeto dict de Python. Esto nos ayudará a hacer uso de los métodos dict de Python para realizar algunas operaciones. La función read_json() se usa para la tarea, que toma la ruta del archivo junto con la extensión como parámetro y devuelve el contenido del archivo JSON como un objeto dict de Python.
- Normalizamos el objeto dict usando la función normalize_json() . Comprueba los pares clave-valor en el objeto dict. Si el valor es nuevamente un dictado, concatena la string de clave con la string de clave del dictado anidado.
- Los datos CSV deseados se crean usando la función generate_csv_data() . Esta función concatena cada registro usando una coma (,) y luego todos estos registros individuales se agregan con una nueva línea (‘\n’ en python).
- En el paso final, escribimos los datos CSV generados en el paso anterior en una ubicación preferida proporcionada a través del parámetro de ruta de archivo.
Archivo utilizado: archivo article.json
{
"article_id": 3214507,
"article_link": "http://sample.link",
"published_on": "17-Sep-2020",
"source": "moneycontrol",
"article": {
"title": "IT stocks to see a jump this month",
"category": "finance",
"image": "http://sample.img",
"sentiment": "neutral"
}
}
Ejemplo: convertir JSON a CSV
Python
import json
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def normalize_json(data: dict) -> dict:
new_data = dict()
for key, value in data.items():
if not isinstance(value, dict):
new_data[key] = value
else:
for k, v in value.items():
new_data[key + "_" + k] = v
return new_data
def generate_csv_data(data: dict) -> str:
# Defining CSV columns in a list to maintain
# the order
csv_columns = data.keys()
# Generate the first row of CSV
csv_data = ",".join(csv_columns) + "\n"
# Generate the single record present
new_row = list()
for col in csv_columns:
new_row.append(str(data[col]))
# Concatenate the record with the column information
# in CSV format
csv_data += ",".join(new_row) + "\n"
return csv_data
def write_to_file(data: str, filepath: str) -> bool:
try:
with open(filepath, "w+") as f:
f.write(data)
except:
raise Exception(f"Saving data to {filepath} encountered an error")
def main():
# Read the JSON file as python dictionary
data = read_json(filename="article.json")
# Normalize the nested python dict
new_data = normalize_json(data=data)
# Pretty print the new dict object
print("New dict:", new_data)
# Generate the desired CSV data
csv_data = generate_csv_data(data=new_data)
# Save the generated CSV data to a CSV file
write_to_file(data=csv_data, filepath="data.csv")
if __name__ == '__main__':
main()
Producción:

Salida de la consola de Python para el bloque de código 1

Salida CSV para el bloque de código 1
Lo mismo se puede lograr mediante el uso de la biblioteca Pandas Python. Pandas es una biblioteca de Python de fuente gratuita que se utiliza para la manipulación y el análisis de datos. Realiza operaciones convirtiendo los datos en un formato pandas.DataFrame . Ofrece muchas funcionalidades y operaciones que se pueden realizar en el marco de datos.
Acercarse
- El primer paso es leer el archivo JSON como un objeto dict de Python. Esto nos ayudará a hacer uso de los métodos dict de Python para realizar algunas operaciones. La función read_json() se usa para la tarea, que toma la ruta del archivo junto con la extensión como parámetro y devuelve el contenido del archivo JSON como un objeto dict de Python.
- Normalizamos el objeto dict usando la función normalize_json() . Comprueba los pares clave-valor en el objeto dict. Si el valor es nuevamente un dictado, concatena la string de clave con la string de clave del dictado anidado.
- En este paso, en lugar de hacer un esfuerzo manual para agregar objetos individuales como cada registro del CSV, estamos usando el método pandas.DataFrame() . Toma el objeto dict y genera los datos CSV deseados en forma de objeto pandas DataFrame. Vale la pena señalar una cosa en el código anterior: los valores de la variable de dictado » new_data » están presentes en una lista. La razón es que al pasar un diccionario para crear un marco de datos de pandas, los valores del dict deben ser una lista de valores donde cada valor representa el valor presente en cada fila para esa clave o nombre de columna. Aquí, tenemos una sola fila.
- Usamos el método pandas.DataFrame.to_csv() que toma la ruta junto con el nombre del archivo donde desea guardar el CSV como parámetro de entrada y guarda los datos CSV generados en el Paso 3 como CSV.
Ejemplo: conversión de JSON a CSV usando Pandas
Python
import json
import pandas
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def normalize_json(data: dict) -> dict:
new_data = dict()
for key, value in data.items():
if not isinstance(value, dict):
new_data[key] = value
else:
for k, v in value.items():
new_data[key + "_" + k] = v
return new_data
def main():
# Read the JSON file as python dictionary
data = read_json(filename="article.json")
# Normalize the nested python dict
new_data = normalize_json(data=data)
print("New dict:", new_data, "\n")
# Create a pandas dataframe
dataframe = pandas.DataFrame(new_data, index=[0])
# Write to a CSV file
dataframe.to_csv("article.csv")
if __name__ == '__main__':
main()
Producción:

Salida de la consola Python para Code Block 2
Salida CSV para el bloque de código 2
Los dos ejemplos anteriores son buenos cuando tenemos un solo nivel de anidamiento para JSON, pero a medida que aumenta el anidamiento y hay más registros, los códigos anteriores requieren más edición. Podemos manejar dicho JSON con mucha facilidad usando la biblioteca pandas. Veamos cómo.
Convertir JSON anidado N a CSV
Cualquier número de anidamientos y registros en un JSON se puede manejar con un código mínimo usando el método » json_normalize() » en pandas .
Sintaxis:
json_normalize (datos)
Archivo en uso: archivo details.json
{
"details": [
{
"id": "STU001",
"name": "Amit Pathak",
"age": 24,
"results": {
"school": 85,
"high_school": 75,
"graduation": 70
},
"education": {
"graduation": {
"major": "Computers",
"minor": "Sociology"
}
}
},
{
"id": "STU002",
"name": "Yash Kotian",
"age": 32,
"results": {
"school": 80,
"high_school": 58,
"graduation": 49
},
"education": {
"graduation": {
"major": "Biology",
"minor": "Chemistry"
}
}
},
{
"id": "STU003",
"name": "Aanchal Singh",
"age": 28,
"results": {
"school": 90,
"high_school": 70,
"graduation":65
},
"education": {
"graduation": {
"major": "Art",
"minor": "IT"
}
}
},
{
"id": "STU004",
"name": "Juhi Vadia",
"age": 23,
"results": {
"school": 95,
"high_school": 89,
"graduation": 83
},
"education": {
"graduation": {
"major": "IT",
"minor": "Social"
}
}
}
]
}
Aquí, la clave » detalles » consiste en una array de 4 elementos, donde cada elemento contiene 3 niveles de objetos JSON anidados . La clave “ mayor ” y “ menor ” en cada uno de estos objetos está en un anidamiento de nivel 3.
Acercarse
- El primer paso es leer el archivo JSON como un objeto dict de Python. Esto nos ayudará a hacer uso de los métodos dict de Python para realizar algunas operaciones. La función read_json() se usa para la tarea, que toma la ruta del archivo junto con la extensión como parámetro y devuelve el contenido del archivo JSON como un objeto dict de Python.
- Hemos iterado para cada objeto JSON presente en la array de detalles. En cada iteración, primero normalizamos el JSON y creamos un marco de datos temporal. Luego, este marco de datos se agregó al marco de datos de salida.
- Una vez hecho esto, se cambió el nombre de la columna para una mejor visibilidad. Si vemos la salida de la consola, la columna » major » se nombró como » education.graduation.major » antes de cambiar el nombre. Esto se debe a que el método » json_normalize() » usa las claves en el nido completo para generar el nombre de la columna para evitar el problema de la columna duplicada. Entonces, » educación » es el primer nivel, » graduación » es el segundo y » especialización » es el tercer nivel en el anidamiento JSON. Por lo tanto, la columna » educación.graduación.major » simplemente se renombró como «graduación».
- Después de cambiar el nombre de las columnas, el método to_csv() guarda el objeto del marco de datos de pandas como CSV en la ubicación del archivo proporcionada.
Ejemplo: convertir JSON n anidado a CSV
Python
import json
import pandas
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def create_dataframe(data: list) -> pandas.DataFrame:
# Declare an empty dataframe to append records
dataframe = pandas.DataFrame()
# Looping through each record
for d in data:
# Normalize the column levels
record = pandas.json_normalize(d)
# Append it to the dataframe
dataframe = dataframe.append(record, ignore_index=True)
return dataframe
def main():
# Read the JSON file as python dictionary
data = read_json(filename="details.json")
# Generate the dataframe for the array items in
# details key
dataframe = create_dataframe(data=data['details'])
# Renaming columns of the dataframe
print("Normalized Columns:", dataframe.columns.to_list())
dataframe.rename(columns={
"results.school": "school",
"results.high_school": "high_school",
"results.graduation": "graduation",
"education.graduation.major": "grad_major",
"education.graduation.minor": "grad_minor"
}, inplace=True)
print("Renamed Columns:", dataframe.columns.to_list())
# Convert dataframe to CSV
dataframe.to_csv("details.csv", index=False)
if __name__ == '__main__':
main()
Producción:
$Salida de consola
—–
Columnas normalizadas: [‘id’, ‘nombre’, ‘edad’, ‘resultados.escuela’, ‘resultados.escuela_secundaria’, ‘resultados.graduación’, ‘educación.graduación.major’, ‘educación.graduación.menor’]
Columnas renombradas: [‘id’, ‘nombre’, ‘edad’, ‘escuela’, ‘high_school’, ‘graduación’, ‘grad_major’, ‘grad_minor’]
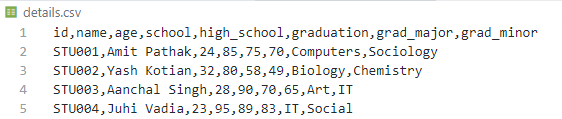
Salida CSV para el bloque de código 3
Publicación traducida automáticamente
Artículo escrito por apathak092 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA