Aquí, vamos a convertir la estructura XML en un DataFrame usando el paquete BeautifulSoup de Python. Es una biblioteca de Python que se utiliza para extraer páginas web. Para instalar esta biblioteca, el comando es
pip install beautifulsoup4
Vamos a extraer los datos de un archivo XML utilizando esta biblioteca y luego convertiremos los datos extraídos en Dataframe. Para convertir a Dataframes, necesitamos instalar la biblioteca de panda.
Biblioteca Pandas: es una biblioteca de Python que se utiliza para la manipulación y el análisis de datos. Para instalar esta biblioteca, el comando es
pip install pandas
Nota: si le pide que instale una biblioteca de analizador, use el comando
pip install et_xmlfile
Implementación paso a paso:
Paso 1: importa las bibliotecas.
Python3
from bs4 import BeautifulSoup import pandas as pd
Primero necesitamos importar las bibliotecas que vamos a usar en nuestro programa. Aquí, importamos la biblioteca BeautifulSoup del módulo bs4 y también importamos la biblioteca pandas y creamos su alias como ‘pd’.
Paso 2: Lea el archivo xml.
Python3
file = open("gfg.xml",'r')
contents = file.read()
Aquí, estamos abriendo nuestro archivo xml llamado ‘gfg.xml’ usando la función de apertura («nombre de archivo», «modo») en el modo de lectura ‘r’ y almacenándolo en la variable ‘archivo’. Luego estamos leyendo los contenidos reales almacenados en el archivo usando la función read().
Paso 3:
Python3
soup = BeautifulSoup(contents,'xml')
Aquí, estamos dando los datos del archivo que se va a raspar, que se almacena en la variable ‘contenido’ a la función BeautifulSoup y también pasamos el tipo de archivo que es XML.
Paso 4: Búsqueda de datos.
Aquí, estamos extrayendo los datos. Estamos utilizando la función find_all() que devuelve los datos extraídos presentes dentro de la etiqueta que se pasa en esta función.
Python3
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')
Ejemplo:
authors = soup.find_all('author')
Estamos almacenando los datos extraídos en la variable de autores. Esta función find_all(‘autor’) extraerá todos los datos dentro de la etiqueta de autor en el archivo xml. Los datos se almacenarán como una lista, es decir, los autores son una lista de datos extraídos de todas las etiquetas de autor en ese archivo xml. Lo mismo con las otras declaraciones.
Paso 5: obtenga datos de texto de xml.
Python3
data = [] for i in range(0,len(authors)): rows = [authors[i].get_text(),titles[i].get_text(), genres[i].get_text(),prices[i].get_text(), pubdate[i].get_text(),des[i].get_text()] data.append(rows)
Ahora, tenemos todos los datos extraídos del archivo xml en varias listas según las etiquetas. Ahora necesitamos combinar todos los datos relacionados con un libro de diferentes listas. Así que ejecutamos un ciclo for donde todos los datos de un libro en particular de diferentes listas se almacenan en una lista llamada ‘filas’ y luego cada una de esas filas se agrega en otra lista llamada ‘datos’.
Paso 6: Imprima el marco de datos.
Finalmente, tenemos datos combinados separados para cada libro. Ahora necesitamos convertir esta lista de datos en un DataFrame.
Python3
df = pd.DataFrame(data,columns = ['Author','Book Title', 'Genre','Price','Publish Date', 'Description'], dtype = float) display(df)
Producción:
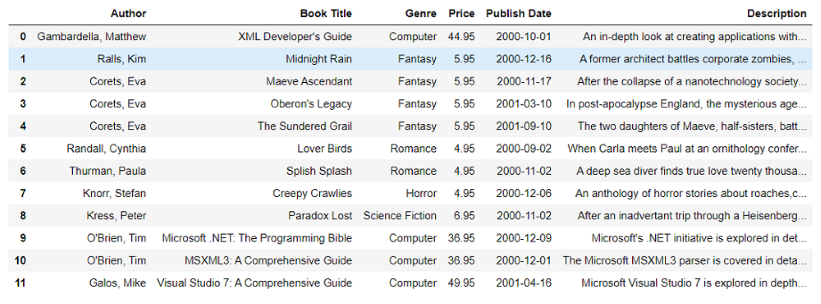
Marco de datos
Aquí, estamos convirtiendo esa lista de datos en un Dataframe usando el comando pd.DataFrame(). En este comando pasamos la lista de ‘datos’ y también pasamos los nombres de las columnas que queremos tener. También hemos mencionado el tipo de datos (dtype) como flotante, lo que hará que todos los valores numéricos floten.
Ahora hemos extraído los datos del archivo XML utilizando BeautifulSoup en DataFrame y se almacena como ‘df’. Para ver el DataFrame, usamos la declaración de impresión para imprimirlo.
Archivo XML utilizado: GFG.xml
A continuación se muestra la implementación completa:
Python3
# Python program to convert xml
# structure into dataframes using beautifulsoup
# Import libraries
from bs4 import BeautifulSoup
import pandas as pd
# Open XML file
file = open("gfg.xml", 'r')
# Read the contents of that file
contents = file.read()
soup = BeautifulSoup(contents, 'xml')
# Extracting the data
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')
data = []
# Loop to store the data in a list named 'data'
for i in range(0, len(authors)):
rows = [authors[i].get_text(), titles[i].get_text(), genres[i].get_text(
), prices[i].get_text(), pubdate[i].get_text(), des[i].get_text()]
data.append(rows)
# Converting the list into dataframe
df = pd.DataFrame(data, columns=['Author',
'Book Title', 'Genre',
'Price', 'Publish Date',
'Description'], dtype = float)
display(df)
Producción:
Marco de datos
Publicación traducida automáticamente
Artículo escrito por yashgupta2808 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA