Las arrays dispersas están en formato orientado a columnas y contienen en su mayoría valores nulos. Los elementos de la array dispersa que no son nulos se organizan en orden ascendente. En este artículo, convertiremos la array y el marco de datos en una array dispersa en el lenguaje de programación R.
Conversión de array a array dispersa
Como sabemos, las arrays en el lenguaje de programación R son los objetos o colecciones de elementos dispuestos en un diseño bidimensional. Podemos construir una array en R usando la función matrix() .
El primer paso que vamos a hacer es instalar el paquete Matrix usando install.packages («Matrix») y luego cargar el paquete usando la función de biblioteca en R. A continuación, construiremos nuestra array usando la función matrix() proporcionada por el paquete Matrix. Después de generar la array, cree una array dispersa equivalente usando as().
Sintaxis:
array dispersa <- como (array base, «array dispersa»)
Parámetros:
- sparsematrix : esta es nuestra array dispersa de muestra que se convertirá a partir de nuestra array base.
- BaseMatrix: esta es nuestra array R de muestra.
- “sparseMatrix”: es la categoría especificada dentro de la función as() para convertir la array R base a formato disperso.
Ejemplo: conversión de array a array dispersa en R
R
# loading the Matrix package library(Matrix) # Constructing a base R matrix set.seed(0) nrows <- 6L ncols <- 8L values <- sample(x = c(0,1,2,3), prob = c(0.6,0.2,0.4,0.8), size = nrows*ncols, replace = TRUE) BaseMatrix <- matrix(values, nrow = nrows) BaseMatrix # For converting base matrix to sparse matrix sparsematrix <- as(BaseMatrix, "sparseMatrix") sparsematrix
Producción :

Convertir un marco de datos en una array dispersa
Sabemos que un marco de datos es una tabla o una estructura similar a una array 2D que tiene filas y columnas y es la forma más común de almacenar datos. Convertiremos el marco de datos en una array dispersa usando la función sparseMatrix() en R.
Sintaxis: sparseMatrix(i = ep, j = ep, p, x, dims, dimnames, simétrico = FALSO, triangular = FALSO, index1 = TRUE, repr = “C”, giveCsparse =(repr == “C”), check = “VERDADERO”, use.last.ij = FALSO)
Parámetros:
- i, j: estos son los números enteros de la misma longitud que especifican las ubicaciones de los índices de fila y columna de la array.
- p : estos son el vector entero de punteros, uno para cada columna o fila en la indexación de filas y columnas basada en cero.
- x : estos son los valores opcionales utilizados en las entradas de array.
- dims : Estos son los vectores enteros no negativos.
- dimnames : Estas son las listas opcionales para ‘dimnames’.
- simétrico: Esta es la variable lógica. Si se especifica verdadero, entonces la array resultante debe ser simétrica y falsa, de lo contrario.
- triangular: esta es también la variable lógica que da verdadero si la array resultante debe ser triangular y falso, de lo contrario.
- index1 : Esta es la variable escalar lógica. Si es verdadero, entonces el conteo de filas y columnas comienza en 1. Si es falso, entonces el conteo de filas y columnas comienza en 0.
- repr: estas son las strings de caracteres que especifican la representación dispersa utilizada para el resultado.
- giveCsparse : Es una variable lógica que indica si la array resultante es Csparse o Tsparse.
- check : Es una variable lógica que indica si se realiza una verificación de validez.
- use.last.ij : También es lógico que indique en caso de pares duplicados, solo se debe usar el último.
Ejemplo: convertir un marco de datos en una array dispersa en R
R
library(Matrix)
# Creating a table of buyers
buyer <- data.frame(Buyers = c("Robert", "Stewart", "Kristen",
"Joe", "Kriti", "Rafel"))
buyer
# Creating a table of cars
car <- data.frame(Cars = c("Maruti", "Sedan", "SUV", "Baleno",
"Hyundai", "BMW","Audi"))
car
# Creating a table of orders: (Buyers, cars, units)
# triplets
order <- data.frame(Buyers = c("Robert", "Robert", "Stewart",
"Stewart", "Kristen", "Kristen",
"Joe", "Kriti", "Joe"),
Cars = c("Maruti", "Maruti", "BMW", "BMW",
"Audi", "Audi", "Maruti", "Audi",
"Sedan"))
# Insert the RowIndex column, identifying
# the row index to assign each buyer
order$RowIndex <- match(order$Buyers, buyer$Buyers)
# Insert the ColIndex column, identifying
# the column index to assign each car
order$ColIndex <- match(order$Cars, car$Cars)
# Now inspect
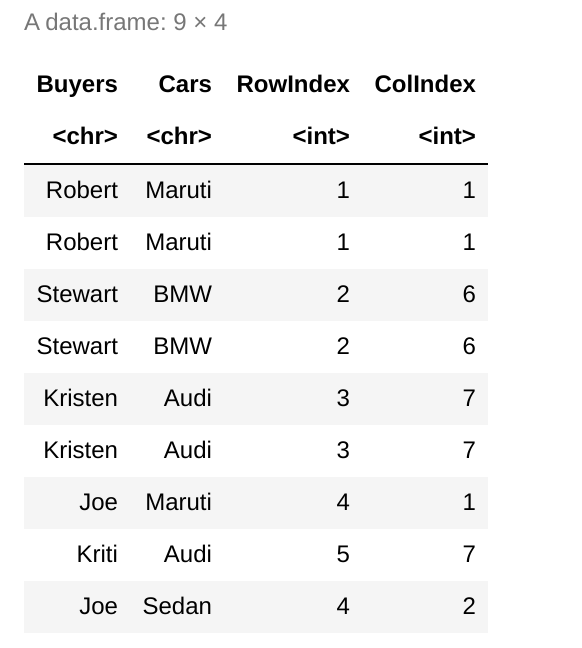
order
# Creating a basic sparse matrix where element
# (i,j) is true if buyer i bought
# car j and false, otherwise
msparse1 <- sparseMatrix( i = order$RowIndex, j = order$ColIndex)
msparse1
# Creating another sparse matrix to make sure
# every buyer and every car appears in our matrix
# by setting the dimensions explicitly
msparse2 <- sparseMatrix( i = order$RowIndex, j = order$ColIndex,
dims = c(nrow(buyer), nrow(car)),
dimnames = list(buyer$Buyers, car$Cars))
msparse2
# Creating another sparse matrix indicating number
# of times buyer i bought car j
msparse3 <- sparseMatrix( i = order$RowIndex, j = order$ColIndex, x = 1L,
dims = c(nrow(buyer), nrow(car)),
dimnames = list(buyer$Buyers, car$Cars))
msparse3
Producción :


Publicación traducida automáticamente
Artículo escrito por mishrapratikshya12 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA