En este artículo, aprenderemos cómo convertir una string separada por comas en una array en el marco de datos pyspark.
En pyspark SQL, la función split() convierte la string separada por delimitadores en una array. Se realiza dividiendo la string en función de delimitadores como espacios, comas y apilándolos en una array. Esta función devuelve pyspark.sql.Column de tipo Array.
Sintaxis: pyspark.sql.functions.split(str, pattern, limit=-1)
Parámetro:
- str:- La string a dividir.
- límite: un número entero que controla el número de veces que se aplica el patrón
- patrón: – El delimitador que se utiliza para dividir la string.
Ejemplos
Veamos algunos ejemplos para comprender el funcionamiento del código.
Ejemplo 1: trabajar con valores de string
Veamos un ejemplo de muestra para ver la función de división en acción. Para este ejemplo, hemos creado nuestro marco de datos personalizado y usamos la función de división para crear un nombre que se ponga en contacto con el nombre del estudiante. Aquí vamos a aplicar división a las columnas de formato de datos de string.
Python3
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, col
# start the spark session
spark = SparkSession.builder \
.appName('GeeksforGeeks') \
.getOrCreate()
# create the dataframe
data = [("Pulkit, Dhingra","M",70),
("Ritika, Pandey","F",85),
("Kaif, Ali","M",63),
("Asha, Deep","F",62)
]
columns=["Name","Gender","Marks"]
df=spark.createDataFrame(data,columns)
# use split function
df2 = df.select(split(col("Name"),",").alias("Name_Arr"),
col("Gender"),col("Marks")) \
.drop("Name")
df2.show()
# stop session
spark.stop()
Producción:
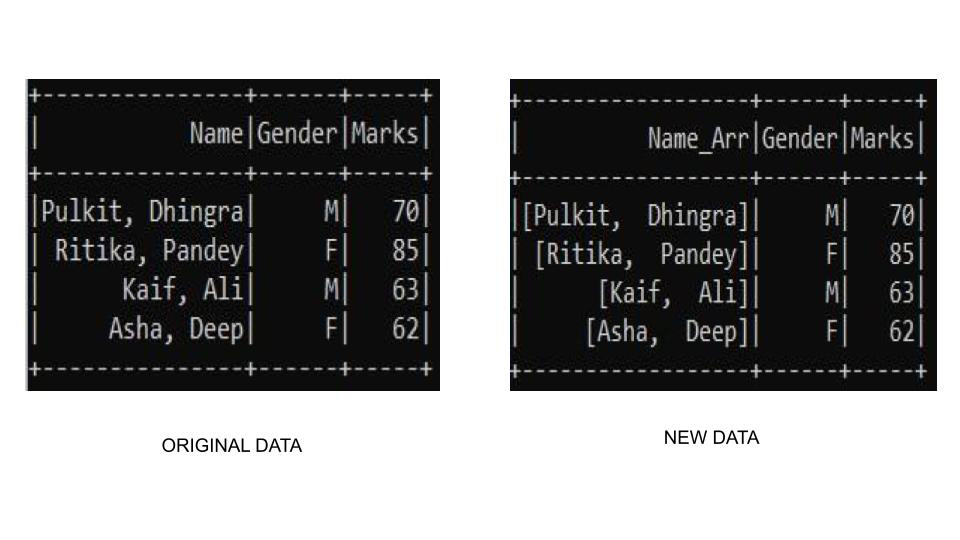
Ejemplo 2: trabajar con valores enteros
Si queremos convertir al tipo numérico, podemos usar la función cast() con la función split(). En este ejemplo, estamos usando la función cast() para construir una array de enteros, por lo que usaremos cast(ArrayType(IntegerType())) donde especifica claramente que necesitamos convertir a una array de tipo entero.
Python3
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, col
from pyspark.sql.types import ArrayType, IntegerType
# start the spark session
spark = SparkSession.builder \
.appName('GeeksforGeeks') \
.getOrCreate()
# create the dataframe
data = [("Pulkit, Dhingra","M","70,85"),
("Ritika, Pandey","F","85,95"),
("Kaif, Ali","M","63,72"),
("Asha, Deep","F","62,92")
]
columns=["Name","Gender","Marks"]
df=spark.createDataFrame(data,columns)
df.show()
# use split function
df2 = df.select(col("Name"),col("Gender"),
split(col("Marks"),",").cast(
ArrayType(IntegerType())).alias("Marks_Arr"))
df2.show()
# stop session
spark.stop()
Producción:
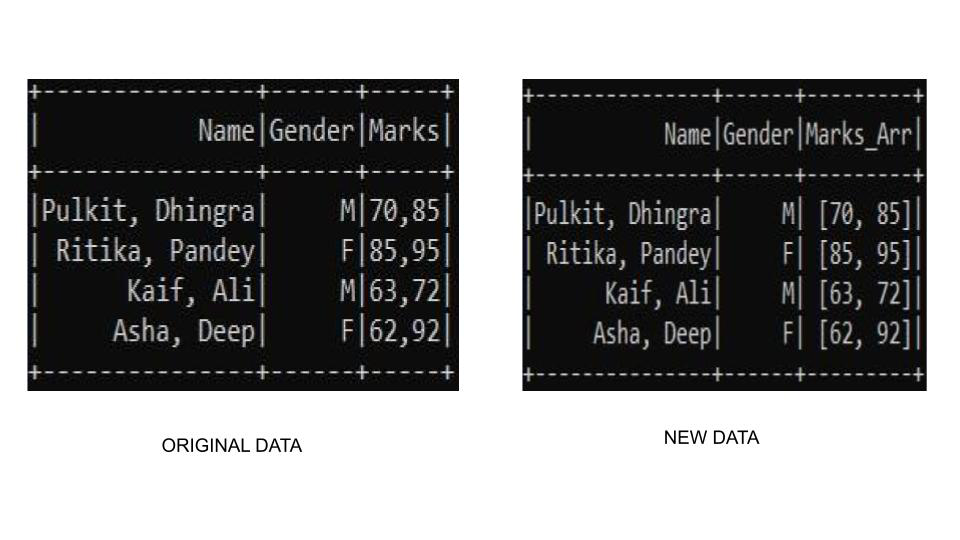
Ejemplo 3: trabajar con valores enteros y de string
Puede haber una condición en la que necesitemos verificar cada columna y dividir si existe un valor de columna separado por comas. La función split() viene cargada de ventajas. Puede haber una condición en la que el separador no esté presente en una columna. La función split() maneja esta situación al crear una sola array del valor de la columna en lugar de dar una excepción. Esto puede ser útil a veces.
Python3
# If you want to convert data to numeric
# types you can cast as follows
import findspark
findspark.init('c:/spark')
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, col
from pyspark.sql.types import ArrayType, IntegerType
def return_array(column):
return split(col(column),",")
# start the spark session
spark = SparkSession.builder \
.appName('GeeksforGeeks') \
.getOrCreate()
# create the dataframe
data = [("Pulkit, Dhingra","M","70,85"),
("Ritika, Pandey","F","85,95"),
("Kaif, Ali","M","63,72"),
("Asha, Deep","F","62,92")
]
columns=["Name","Gender","Marks"]
df=spark.createDataFrame(data,columns)
df.show()
# use split function
df2 = df.select(split(col("Name"),",").alias("Name"),
split(col("Gender"),",").alias("Gender"),
split(col("Marks"),",").alias("Marks_Arr"))
df2.show()
# stop session
spark.stop()
Producción:
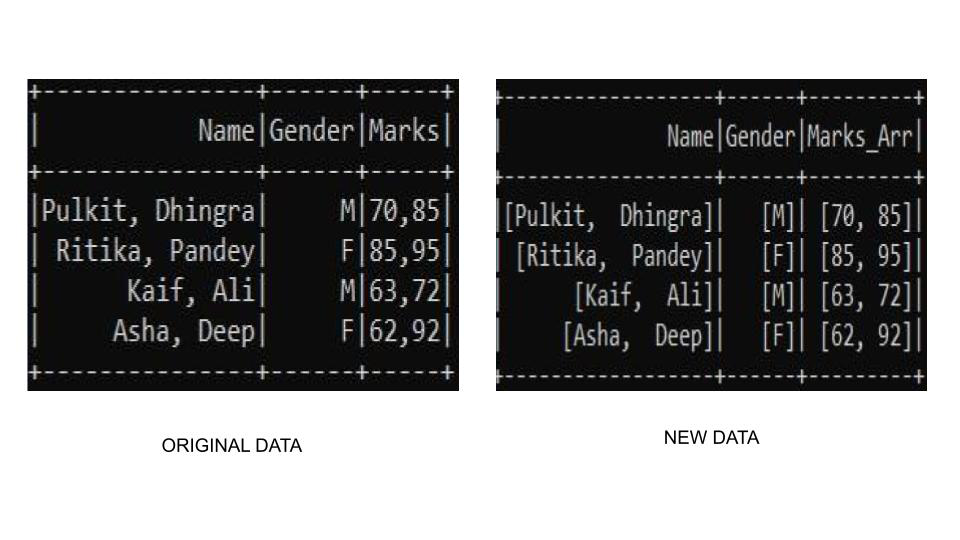
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA