Con la ayuda de Pandas, podemos realizar muchas funciones en un conjunto de datos, como cortar, indexar, manipular y limpiar el marco de datos.
Caso 1: Rebanar el marco de datos de Pandas usando DataFrame.iloc[]
Ejemplo 1: dividir filas
Python3
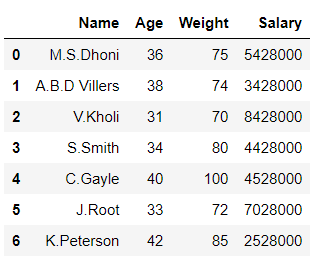
# importing pandas library import pandas as pd # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary']) # data frame before slicing df
Producción:
Python3
# Slicing rows in data frame df1 = df.iloc[0:4] # data frame after slicing df1
Producción:
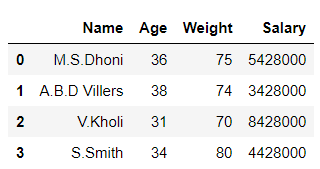
En el ejemplo anterior, cortamos las filas del marco de datos.
Ejemplo 2 : Columnas de corte
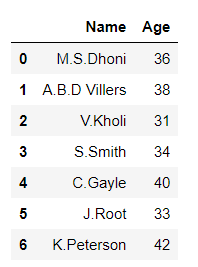
Python3
# importing pandas library import pandas as pd # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary']) # data frame before slicing df
Producción:
Python3
# Slicing columnss in data frame df1 = df.iloc[:,0:2] # data frame after slicing df1
Producción:
En el ejemplo anterior, cortamos las columnas del marco de datos.
Caso 2: Indización del marco de datos de Pandas
Python3
# importing pandas library import pandas as pd # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe and indexing it using Aplhabets df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary'], index=['A', 'B', 'C', 'D', 'E', 'F', 'G']) # Displaying data frame df
Producción:
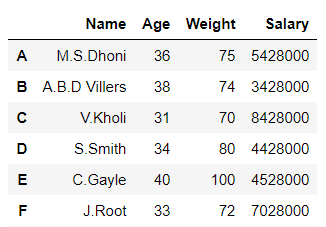
En el ejemplo anterior, indexamos el marco de datos.
Caso 3: Manipulación del marco de datos de Pandas
La manipulación del marco de datos se puede realizar de varias maneras, como aplicar funciones, cambiar un tipo de datos de columnas, dividir, agregar filas y columnas a un marco de datos, etc.
Ejemplo 1: Aplicar la función lambda a una columna usando Dataframe.assign()
Python3
# importing pandas library import pandas as pd # creating and initializing a list values = [['Rohan', 455], ['Elvish', 250], ['Deepak', 495], ['Sai', 400], ['Radha', 350], ['Vansh', 450]] # creating a pandas dataframe df = pd.DataFrame(values, columns=['Name', 'Univ_Marks']) # Applying lambda function to find percentage of # 'Univ_Marks' column using df.assign() df = df.assign(Percentage=lambda x: (x['Univ_Marks'] / 500 * 100)) # displaying the data frame df
Producción:
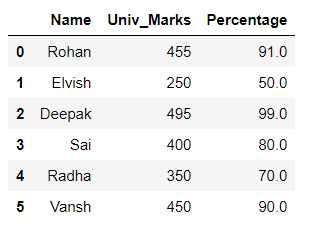
En el ejemplo anterior, la función lambda se aplica a la columna ‘Univ_Marks’ y se forma una nueva columna ‘Porcentaje’ con la ayuda de ella.
Ejemplo 2: ordenar el marco de datos en orden ascendente
Python3
# importing pandas library import pandas as pd # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary']) # Sorting by column 'Weight' df.sort_values(by=['Weight'])
Producción:
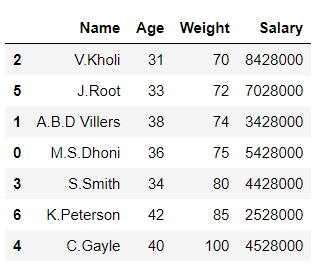
En el ejemplo anterior, ordenamos el marco de datos por columna ‘Peso’.
Caso 4: limpieza del marco de datos de Pandas
Python3
# importing pandas and Numpy libraries import pandas as pd import numpy as np # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villers', np.nan, 74, np.nan], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', np.nan, 100, np.nan], [np.nan, 33, np.nan, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary']) df
Producción:

Python3
# Checking for missing values df.isnull().sum()
Producción:
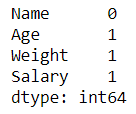
Python3
# dropping or cleaning the missing data df= df.dropna() df
Producción:
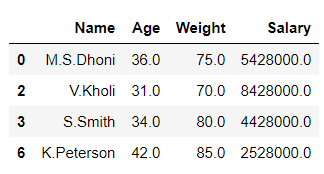
En el ejemplo anterior, limpiamos todos los valores faltantes del conjunto de datos.
Publicación traducida automáticamente
Artículo escrito por vanshgaur14866 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA