En este artículo, aprenderemos cómo crear un PySpark DataFrame. Las aplicaciones de PySpark comienzan con la inicialización de SparkSession, que es el punto de entrada de PySpark, como se muestra a continuación.
# Inicialización de SparkSession
desde pyspark.sql importar SparkSession
chispa = SparkSession.builder.getOrCreate()
Nota: PySpark shell a través del ejecutable pyspark, crea automáticamente la sesión dentro de la chispa variable para los usuarios. Entonces también ejecutará esto usando shell.
Creación de un marco de datos PySpark
Un PySpark DataFrame a menudo se crea a través de pyspark.sql.SparkSession.createDataFrame . Hay métodos mediante los cuales crearemos PySpark DataFrame a través de pyspark.sql.SparkSession.createDataFrame. El pyspark.sql.SparkSession.createDataFrame toma el argumento del esquema para especificar el esquema del DataFrame. Cuando se omite, PySpark infiere el esquema correspondiente tomando una muestra de los datos.
Sintaxis
pyspark.sql.SparkSession.createDataFrame()
Parámetros:
- dataRDD: un RDD de cualquier tipo de representación de datos SQL (por ejemplo, Fila, tupla, int, booleano, etc.), o lista, o pandas.DataFrame.
- esquema: una string de tipo de datos o una lista de nombres de columna, el valor predeterminado es Ninguno.
- SamplingRatio: la relación de muestra de las filas utilizadas para inferir
- verificarEsquema: Verifica los tipos de datos de cada fila contra el esquema. Habilitado por defecto.
Devoluciones: marco de datos
A continuación, hay diferentes formas de crear el PySpark DataFrame:
Cree PySpark DataFrame a partir de un inventario de filas
En la implementación de dar, crearemos el marco de datos pyspark utilizando un inventario de filas. Para esto, proporcionamos los valores a cada variable (característica) en cada fila y los agregamos al objeto del marco de datos. Después de hacer esto, mostraremos el marco de datos y el esquema.
Python3
# Need to import to use date time from datetime import datetime, date # need to import for working with pandas import pandas as pd # need to import to use pyspark from pyspark.sql import Row # need to import for session creation from pyspark.sql import SparkSession # creating the session spark = SparkSession.builder.getOrCreate() # schema creation by passing list df = spark.createDataFrame([ Row(a=1, b=4., c='GFG1', d=date(2000, 8, 1), e=datetime(2000, 8, 1, 12, 0)), Row(a=2, b=8., c='GFG2', d=date(2000, 6, 2), e=datetime(2000, 6, 2, 12, 0)), Row(a=4, b=5., c='GFG3', d=date(2000, 5, 3), e=datetime(2000, 5, 3, 12, 0)) ]) # show table df.show() # show schema df.printSchema()
Producción:
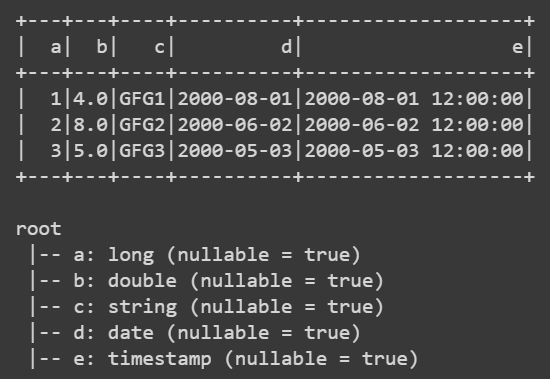
Cree PySpark DataFrame con un esquema explícito
En la implementación de dar, crearemos el marco de datos pyspark usando un esquema explícito. Para esto, proporcionamos los valores de características en cada fila y los agregamos al objeto del marco de datos con el esquema de variables (características). Después de hacer esto, mostraremos el marco de datos y el esquema.
Python3
# Need to import to use date time from datetime import datetime, date # need to import for working with pandas import pandas as pd # need to import to use pyspark from pyspark.sql import Row # need to import for session creation from pyspark.sql import SparkSession # creating the session spark = SparkSession.builder.getOrCreate() # PySpark DataFrame with Explicit Schema df = spark.createDataFrame([ (1, 4., 'GFG1', date(2000, 8, 1), datetime(2000, 8, 1, 12, 0)), (2, 8., 'GFG2', date(2000, 6, 2), datetime(2000, 6, 2, 12, 0)), (3, 5., 'GFG3', date(2000, 5, 3), datetime(2000, 5, 3, 12, 0)) ], schema='a long, b double, c string, d date, e timestamp') # show table df.show() # show schema df.printSchema()
Producción:
Cree PySpark DataFrame a partir de DataFrame usando Pandas
En la implementación de dar, crearemos el marco de datos pyspark usando Pandas Dataframe. Para esto, proporcionamos la lista de valores para cada característica que representa el valor de esa columna con respecto a cada fila y los agregamos al marco de datos. Después de hacer esto, mostraremos el marco de datos y el esquema.
Python3
# Need to import to use date time
from datetime import datetime, date
# need to import for working with pandas
import pandas as pd
# need to import to use pyspark
from pyspark.sql import Row
# need to import for session creation
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
## PySpark DataFrame from a pandas DataFrame
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [4., 8., 5.],
'c': ['GFG1', 'GFG2', 'GFG3'],
'd': [date(2000, 8, 1), date(2000, 6, 2),
date(2000, 5, 3)],
'e': [datetime(2000, 8, 1, 12, 0),
datetime(2000, 6, 2, 12, 0),
datetime(2000, 5, 3, 12, 0)]
})
df = spark.createDataFrame(pandas_df)
df
# show table
df.show()
# show schema
df.printSchema()
Producción:
Crear PySpark DataFrame desde RDD
En la implementación de dar, crearemos el marco de datos pyspark usando una lista de tuplas. Para esto, estamos creando el RDD proporcionando los valores de características en cada fila usando el método paralelizar() y los agregamos al objeto de marco de datos con el esquema de variables (características). Después de hacer esto, mostraremos el marco de datos y el esquema.
Python3
# Need to import to use date time from datetime import datetime, date # need to import for working with pandas import pandas as pd # need to import to use pyspark from pyspark.sql import Row # need to import for session creation from pyspark.sql import SparkSession # creating the session spark = SparkSession.builder.getOrCreate() # pyspark dataframe rdd = spark.sparkContext.parallelize([ (1, 4., 'GFG1', date(2000, 8, 1), datetime(2000, 8, 1, 12, 0)), (2, 8., 'GFG2', date(2000, 6, 2), datetime(2000, 6, 2, 12, 0)), (3, 5., 'GFG3', date(2000, 5, 3), datetime(2000, 5, 3, 12, 0)) ]) df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e']) df # show table df.show() # show schema df.printSchema()
Producción:
Crear PySpark DataFrame desde CSV
En la implementación de dar, crearemos el marco de datos pyspark usando CSV. Para esto, abrimos el archivo CSV y los agregamos al objeto del marco de datos. Después de hacer esto, mostraremos el marco de datos y el esquema.
CSV utilizado: train_dataset
Python3
# Need to import to use date time
from datetime import datetime, date
# need to import for working with pandas
import pandas as pd
# need to import to use pyspark
from pyspark.sql import Row
# need to import for session creation
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# PySpark DataFrame from a csv
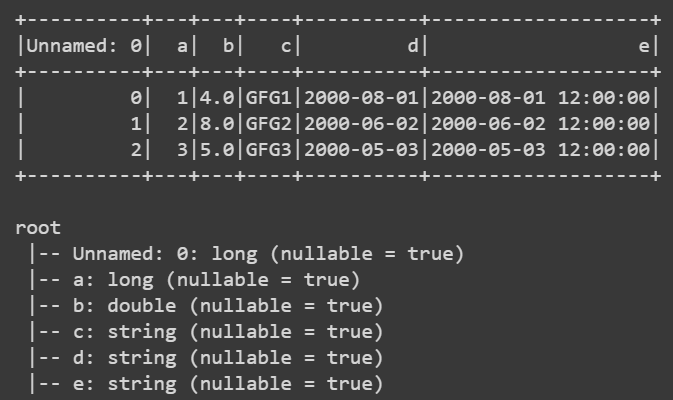
df = spark.createDataFrame(pd.read_csv('data.csv'))
df
# show table
df.show()
# show schema
df.printSchema()
Producción:
Crear PySpark DataFrame a partir de un archivo de texto
En la implementación de dar, crearemos un marco de datos pyspark utilizando un archivo de texto. Para esto, estamos abriendo el archivo de texto con valores que están separados por tabulaciones y los agregamos al objeto del marco de datos. Después de hacer esto, mostraremos el marco de datos y el esquema.
Archivo utilizado:

Python3
# Need to import to use date time
from datetime import datetime, date
# need to import for working with pandas
import pandas as pd
# need to import to use pyspark
from pyspark.sql import Row
# need to import for session creation
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# PySpark DataFrame from a csv
df = spark.createDataFrame(pd.read_csv('data.txt', delimiter="\t"))
df
# show table
df.show()
# show schema
df.printSchema()
Producción:
Crear PySpark DataFrame desde JSON
En la implementación de dar, crearemos el marco de datos pyspark usando JSON. Para esto, abrimos el archivo JSON y los agregamos al objeto del marco de datos. Después de hacer esto, mostraremos el marco de datos y el esquema.
JSON utilizado:

Python3
# Need to import to use date time
from datetime import datetime, date
# need to import for working with pandas
import pandas as pd
# need to import to use pyspark
from pyspark.sql import Row
# need to import for session creation
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# PySpark DataFrame from a csv
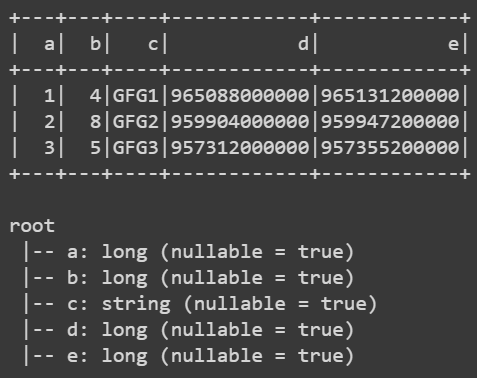
df = spark.createDataFrame(pd.read_json('data.json'))
df
# show table
df.show()
# show schema
df.printSchema()
Producción:
Entonces, todos estos son los métodos para crear un marco de datos PySpark. Los siguientes conjuntos de datos se utilizaron en los programas anteriores.
Publicación traducida automáticamente
Artículo escrito por YashKhandelwal8 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA