Requisito previo: Creación de vistas en Pandas DataFrame | Serie 1
Muchas veces, mientras hacemos un análisis de datos, tratamos con un gran conjunto de datos que tiene muchos atributos. No todos los atributos son necesariamente igualmente importantes. Como resultado, queremos trabajar solo con un conjunto de columnas en el marco de datos. Para ello, veamos cómo podemos crear vistas en el Dataframe y seleccionar solo aquellas columnas que necesitamos y dejar el resto.
Dado un marco de datos que contiene datos nba , cree vistas en él de modo que solo se incluyan las columnas deseadas.
Nota: para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Solución #1: mientras leemos los datos del archivo csv en Python, podemos seleccionar todas las columnas que queremos leer en el DataFrame.
# importing pandas as pd
import pandas as pd
# list of columns that we want to
# read into the DataFrame
use_cols =['Name', 'Number', 'College']
# Reading the csv file
df = pd.read_csv('nba.csv', usecols = lambda x : x in use_cols,
index_col = False)
# Print the dataframe
print(df)
Producción :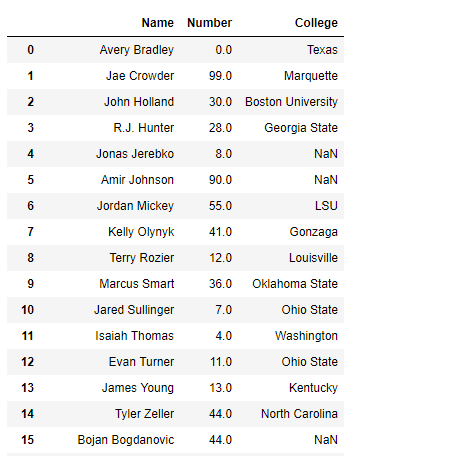
Solución #2: mientras leemos los datos del archivo csv en Python, podemos enumerar todas las columnas que no queremos leer en el DataFrame. Es como dejar caer esas columnas.
# importing pandas as pd
import pandas as pd
# list of columns that we do not want
# to read into the DataFrame
skip_cols =['Name', 'Number', 'College']
# Reading the csv file
df = pd.read_csv('nba.csv', usecols = lambda x : x not in skip_cols,
index_col = False)
# Print the dataframe
print(df)
Producción :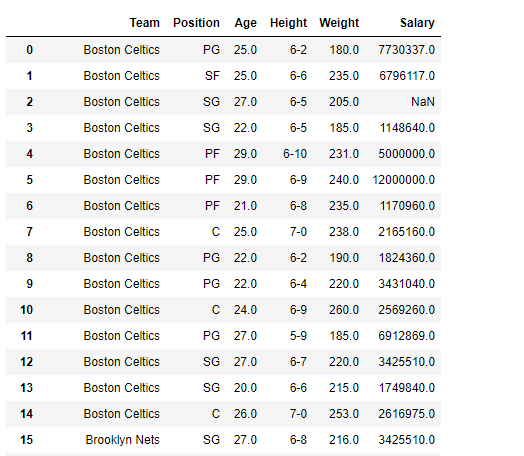
Solución #3: podemos usar el difference()método para eliminar las columnas que no necesitamos.
# importing pandas as pd
import pandas as pd
# Reading the csv file
df = pd.read_csv("nba.csv")
# Print the dataframe
print(df)
Producción :
Ahora eliminaremos aquellas columnas que no necesitamos usando el difference()método.
# Drop the listed columns df_view = df[df.columns.difference(['Position', 'Age', 'Salary'])] # Print the new DataFrame print(df_view)
Producción :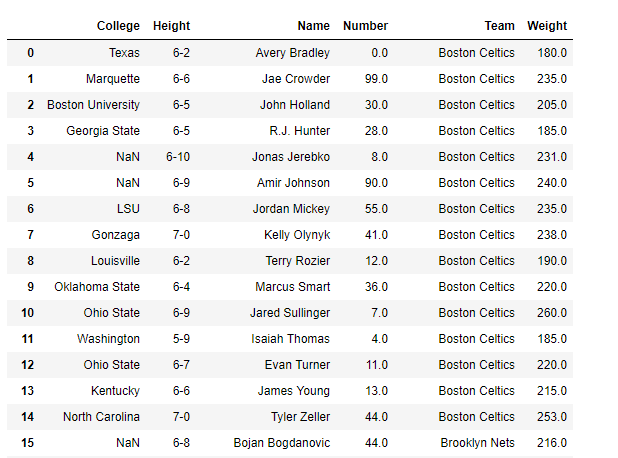
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA